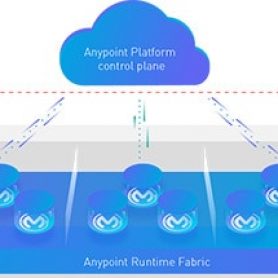
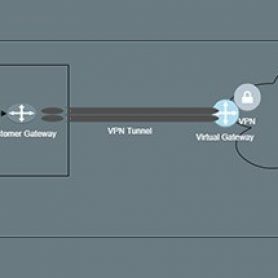
From Chaos to Clarity: How Data Integration Drives Efficiency
The average enterprise has data in more than 1,000 applications, yet only 29% of them are connected. If disconnected data is slowing you down,

11 mins read | February 26, 2024