
3 Ways Generative AI Will Help Marketers Connect With Customers
3 min read




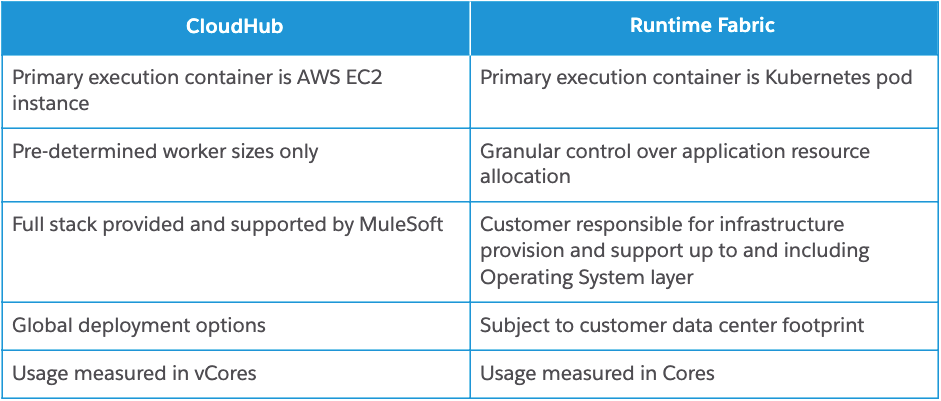
Anypoint Platform offers several options for the deployment and management of MuleSoft runtimes (“Mules”). Fully-managed cloud integration platform-as-a-service (iPaaS) CloudHub and the customer-hosted Anypoint Runtime Fabric options are among the most popular.
While both options provide industry-leading capabilities and high levels of operational flexibility, underlying differences in how they operate need to be considered in order to accurately size and scale Mules running in these modes.
We’ll examine the underlying architectural differences between the two models and how this fundamentally affects the non-functional characteristics of deployed Mule applications. We’ll consider how these differences impact performance testing approaches as well as considerations for ensuring that applications perform in a consistent manner.



The terms ‘vCPU’ and ‘vCore’ and how they are applied in the context of Anypoint as they are often used interchangeably when they actually have distinct definitions. A ‘CPU’ or ‘vCPU’ is a technical unit of computing that (normally) equates to a processor socket or core. In comparison, a ‘core’ (or ‘vCore’) is a commercial unit that is how MuleSoft Runtimes are primarily licensed.
While there are links between these terms it is important to retain this distinction between the two and no equivalence between these terms should be implied. We’ll use these terms consistently in this post.
Both CloudHub and Anypoint Runtime Fabric offer isolation between applications running on the same host, however differ substantially in how this is achieved. For CloudHub, this is achieved by virtualization, through use of AWS EC2 instances. For Runtime Fabric, however, this is achieved by using containerization. This is important because at the highest level in CloudHub this effectively gives deployments access to a near-infinite amount of compute (subject to their commercial agreement), whereas in Runtime Fabric a deployment is configured with an allocation from a fixed — albeit extensible — pool of compute.
The following table provides further detail on key differences between the two approaches that are likely to be important to consider when determining the best platform for your use case.
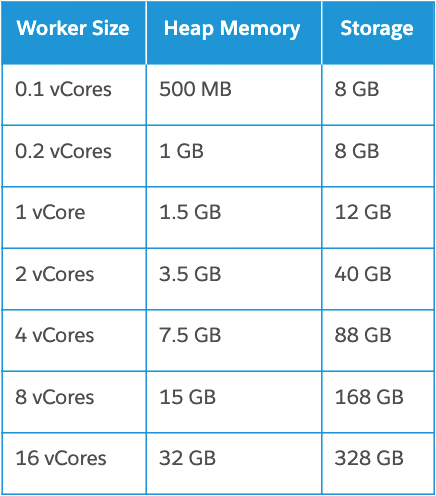
CloudHub offers seven pre-determined worker sizes that dictate the amount of JVM heap memory (RAM) and storage available to that worker.
While larger workers also offer more compute capacity, this is not always linear to the worker vCore sizing (core != CPU). Instead, MuleSoft makes use of AWS EC2 burstable performance instances for fractional vCore workers, which allow for short periods of high performance.
EC2 burstable instances use a ‘credit’ system, where periods of light activity accumulate credits that can then be spent to enable higher performance. These are ideally suited for API applications that are not under constant load.
In addition, the instances run in ‘unlimited’ mode for the first hour after deployment to accelerate application start up and warm up processes.
See the table below for the full set of CloudHub worker sizes:
According to AWS: “Each burstable performance instance continuously earns (at a millisecond-level resolution) a set rate of CPU credits per hour, depending on the instance size.
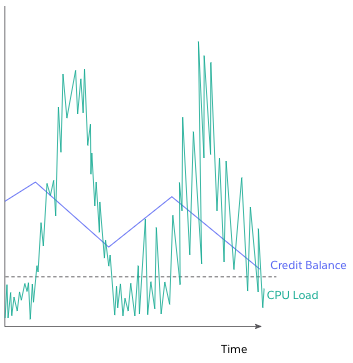
“If a burstable performance instance uses fewer CPU resources than is required for baseline utilization (such as when it is idle), the unspent CPU credits are accrued in the CPU credit balance. If a burstable performance instance needs to burst above the baseline utilization level, it spends the accrued credits. The more credits that a burstable performance instance has accrued, the more time it can burst beyond its baseline when more CPU utilization is needed.”
While exact CloudHub worker to AWS instance sizing is not published (as this is determined by MuleSoft and may change without notice), for workers backed by burstable performance instances the relative performance is controlled by the accrual of CPU credits as opposed to the number of vCPUs in the instance.
This means that while credits are available, relative performance of fractional core CloudHub workers will become equal. However, relative performance will become disparate under load in favor of larger instance sizes over time as CPU credits are exhausted.
For Runtime Fabric, performance is directly controlled via a fixed allocation of vCPU or fractions of a physical/virtual CPU.
This can be a fixed amount (reserve) or set to allow bursting behaviour (limit), but is defined during application deployment and cannot be adjusted dynamically in a running application.
Runtime Fabric offers more flexibility and increased granularity in specifying application CPU and memory sizing. CPU reserve values as low as 0.02 (1/50th) CPU can be set and memory specified independently from the CPU allocation. As a comparison, 1/50th of a current-day laptop is roughly the equivalent of a Pentium desktop circa 1999!
The burstable vCPU capability in Runtime Fabric allows for resources to be utilized in a more efficient way, especially across multiple applications where load is inconsistent. However, this flexibility comes with an associated reduction of deterministic behavior, which could lead to erratic application performance.
As burst vCPUs are shared between multiple applications, the capacity can only ever be provided on a “best attempts” model; it should never be depended on to be available. In addition, other applications can be deployed into burst space, which means burst capacity on a worker node may reduce over time.
As worker nodes are filled with more applications, availability of burst space will reduce. Different worker nodes may have differing levels of available burst at any given time depending on deployments. In addition, the underlying container engine of Runtime Fabric will move replicas between worker nodes (for example during applying upgrades), so worker load will not remain consistent over time.
In Runtime Fabric, applications that have critical performance requirements should not utilize burst vCPUs as it can not be guaranteed that these will be available when needed. Such applications should be sized using guaranteed ‘reserve’ vCPUs only.
It is highly recommended that applications and their underlying resources are managed proactively to ensure burst space is appropriately leveraged. This includes monitoring the overall vCPU allocations across Runtime Fabric worker nodes and scaling horizontally or vertically when capacity limits are approached.
If bursting is being used, it is suggested to “ring fence” a portion of worker vCPUs for burst. It should be agreed that no application will normally be deployed into this ring fenced area, so that it will remain available for burst by other applications. You may choose to set vCPU bursting limits for applications accordingly, so that they do not expect to receive more burst vCPUs than are available on the worker node. The vCPUs are still not guaranteed to be always available if multiple applications on the same worker node burst concurrently.
So, given the architectural differences discussed, it is clear that performance testing cannot be carried out on a like-for-like basis between CloudHub and Runtime Fabric.
While CloudHub is a fully controlled environment, variables within the customer environment can significantly impact Runtime Fabric performance (hosted CPU speed/vendor/architecture, disk speed/IOPS, network bandwidth, etc.) Variations of overall performance should be expected between applications due to variances in application complexity, payload shape/sizing, upstream connectivity/bandwidth etc.
It is suggested that a deployment target (CloudHub/Runtime Fabric) is selected based on functional and connectivity requirements, then is sized appropriately for that target based on non-functional requirements. Any application with stated performance NFRs must be specifically performance tested.
In CloudHub, applications start in ‘unlimited’ mode for the first hour, so performance testing should not commence until an hour after application deployment. Testing should be executed over a long enough period to exhaust available burst credits and results normalised to produce realistic aggregated performance metrics. Ideally, performance loading should mirror expected production traffic shaping. (e.g. consistent load, load spiking, etc.)
CloudHub applications can be performance tested in isolation as there is no resource overlap or impediment from other applications.
When executing performance tests on a pre-production environment, any factors that may yield this environment to not be fully representative of production performance should be considered. This includes applying production-like load to other applications on that fabric if burst vCPUs are used. If this is not performed then invalid performance test results may be produced as applications under test may depend on burst capacity that is not later available in the production environment.
Slower application startup times should be expected when using a low level of vCPUs (< 0.5 vCPUs) as startup is a compute expensive operation. This will also increase downtime if an application is restarted without high availability configuration in place.
The combination of CloudHub and Anypoint Runtime Fabric offers a great degree of flexibility in terms of how and where to deploy Mule applications to unlock data and business processes as part of an application network. However, it’s important to ensure that the right sizing approach is used depending on the deployment platform being used.
CloudHub provides a powerful platform for hosting Mule applications, with little to no set up required, with built-in scaling, advanced management features and includes hosting and support. Runtime Fabric provides additional flexibility and opportunities for granular control, but more care must be taken to ensure the balance between scalability and performance is maintained.
Ultimately, there will be many factors that influence the decision on whether to use CloudHub or Anypoint Runtime Fabric for your application network. Consider the technical elements first; network connectivity and security models are likely to dominate these discussions. Secondly, consider the application use cases as some will be better suited to the burstable nature of CloudHub and some to the higher-density and granularity of Anypoint Runtime Fabric.
Ensure you’re sizing your deployments appropriately according to the target architecture chosen, but don’t assume that the same performance model can be used for both architectures. Use performance testing cycles or baseline against similar applications on the same architecture to help set initial levels; then, continually monitor performance and tune accordingly.








Get the latest articles in your inbox.














