
API response time is essential to providing the frictionless end-user experiences necessary for you to meet your API program’s KPIs and retention goals. One way to optimize performance is by having a caching layer in your API architecture. This layer allows you to deliver cached responses for common requests––thereby accessing data in a quick and inexpensive manner.
Today, we are very excited to announce the GA of a caching policy for Anypoint API Manager. Instead of having to write the caching logic inside Mule application code, you can now apply this policy with a single click. With this policy, users can avoid making multiple calls to a backend system to fetch any data which, in turn, improves API performance by reducing any expensive data processing.
This policy is unique because it leverages MuleSoft’s Object Store. With Object Store, each CloudHub application is given its own storage. This storage is fully managed, provides high availability, as well as unlimited key-value pairs to store. This makes it an obvious choice for persistence. It can serve a wide variety of use cases, including:
- Storing synchronization information from API responses that change at predictable intervals
- Storing temporal information, such as access tokens
- Storing any infrequently evolving business rules
By using Object Store, which is fully managed and integrated with Anypoint Platform, users can take advantage of many of its benefits:
- Support for unlimited keys
- High availability across availability zones within a region
- Data co-located in the same region as your deployed Mule applications
- End-to-end secure transport and storage, because the Object Store uses TLS for secure transport
- Data at rest is stored using FIPS 140-2 compliant encryption standards
Before we provide a deep dive into the details of the policy, one questions users typically ask is, “what should I cache?” Here are some general guidelines:
- Any resource accessible via HTTP GET or CONNECT
- Static data
- Responses that are immutable
- Responses that change infrequently or at predictable intervals
- Responses used by many clients (frequently-requested data)
This blog post will review an implementation scenario to help you understand the benefits of API response caching. In case you’re already wondering what we found as we explored this scenario, let’s give you a key result:
Based on the test results, we observed that the test API could be delivered up to 10x faster when cached.
What does this policy store?
This policy stores a whole HTTP response up to 1 MB from the backend, including the status codes, headers, payload, and session variables. If any policies can edit the response before this policy receives it, those changes are also stored in the response.
Let’s start with the basics of policy configuration
HTTP Caching Key: Key identifier for caching an entry. It supports DataWeave expressions For example: #[attributes.headers[‘key’]]
Maximum Cache Entries: This is the maximum number of responses that can be present in the cache at the same time. The criteria for removing the responses from the cache when this maximum is surpassed is FIFO.
Entry Time To Live: This is the expiration time for an entry to be removed from a cache. For in-memory or Hazelcast cache consider using a small value to avoid persisting too much data.
Distributed: This indicates if a cache will be shared between different nodes of an API deployment target, especially for multi-worker CloudHub applications and clustered deployment on-premise servers. To use Object Store V2 for CloudHub APIs the object store v2 checkbox must be checked in Runtime Manager deployment property.
Persist Cache: This indicates if a cache is runtime restart proof. Depending on the API’s deployment target, a different object store is selected
- CloudHub: Object Store V2 (To use Object Store V2 for CloudHub APIs, the object store v2 checkbox must be checked in the runtime manager deployment property)
- Hybrid: File-based store
- Runtime Fabric: File-based store
Follow HTTP Caching Directives: This policy implemented some of the HTTP directives from the RFC-7234. The HTTP headers can be extremely useful for cache skipping. For example:
no-cache: The response isn’t searched for in the cache, but is stored in the cache.
curl -X GET http://myapp.cloudhub.io/requestPath -H 'cache-control: no-cache' -H 'key: CR12
no-store: The response isn’t stored in the cache, but if it is already present in the cache the policy returns the response.
curl -X GET http://myapp.cloudhub.io/requestPath -H 'cache-control: no-store' -H 'key: CR12
Invalidation Header: This header can be used to invalidate a single entry or purge the entire cache. The header name is considered as a sensitive data and masked in the UI. The acceptable values are “invalidate” and “invalidate-all.”
Conditional Request/Response Caching Expression: This policy supports dynamic conditional caching based on request-response using DataWeave expressions. For example:
To cache only GET and HEAD requests, the expression will be the following:
#[attributes.method == 'GET' or attributes.method == 'HEAD']
Caching based on RFC recommended response status codes
- #[[200, 203, 204, 206, 300, 301, 404, 405, 410, 414, 501] contains attributes.statusCode]
Policy in action
Now that we have the necessary context, let’s define two hypothetical scenarios for our use case and then show the impact of applying a caching policy. Last week, a retail company started having some performance issues with their Salesforce instance/organization due to unexpected load. Let’s take a look at the technical and business scenarios.
Scenario 1: Technical Scenario: The response time from their API is erratic and may spike up to 6 seconds to retrieve all the leads. Since customer leads do not change that often, the team at this retail company can apply a caching layer. (Remember that to add caching, some critical conditions are required, the most important of which is that data should not change often).
Scenario 2: Business Scenario: Salesforce APIs have daily rate limits according to an SLA assigned. Once you hit the limit, you cannot call their API for a specific period. One way to solve this problem is to pay more and get a bigger SLA, or another inexpensive solution is to reduce the API calls to Salesforce by adding a caching layer on top of your API, that way you can serve most of the content from the cache without spending on unnecessary API calls.
Below is the response returned from the Salesforce leads API without any caching, note that response time is just over 6 seconds.

Now let’s add caching policy into the mix.
1. Log into Anypoint Platform: anypoint.mulesoft.com.
2. Go to the API Manager page, select the API of your interest and navigate to the policies tab.
3. You will see a policy called “HTTP Caching,” which is under Quality of Service.
4. Click on apply and configure the policy.

5. Once you apply the policy, wait for a few seconds to receive the policy details to the gateway. As with any cache mechanism, you won’t notice any difference in the first request called because the cache needs to be populated first (cache miss).
6. Try the same API call again with the same key, and you will see that the response headers now contain a new header called “age.” This means that the cache is handling the response, and the amount shown is the time that the value has been present in the cache and the request wasn’t sent to Salesforce. After a period of time, the number of entries in a cache can grow and a probability of “cache hit” is higher.

As you can see, API caching has made a huge difference in the response time. The same API is responding in 900ms (<1 sec) which is more than 60% improvement in the performance. This is a pretty sizable impact that was achieved by simply adding caching to the API.
How can I purge the entire cache?
The policy accepts an invalidation header, let’s say the header name is configured as “x-agw-invalidate,” then this request will purge the contents.
curl -X GET http://salesforce-lead.cloudhub.io/salesforce-api -H 'key: 00Q610000050CNyET8' -H 'x-agw-invalidate: invalidate-all'
Viewing your Object Store V2 cached data in Anypoint Runtime Manager
Once you have data inside Object Store v2, you can easily view it in Anypoint Runtime Manager by clicking on the “Application Data” tab of a CloudHub application. From there, you’ll be able to view, search, and edit “httpCachingPolicyObjectStore-xxx” created by the policy.
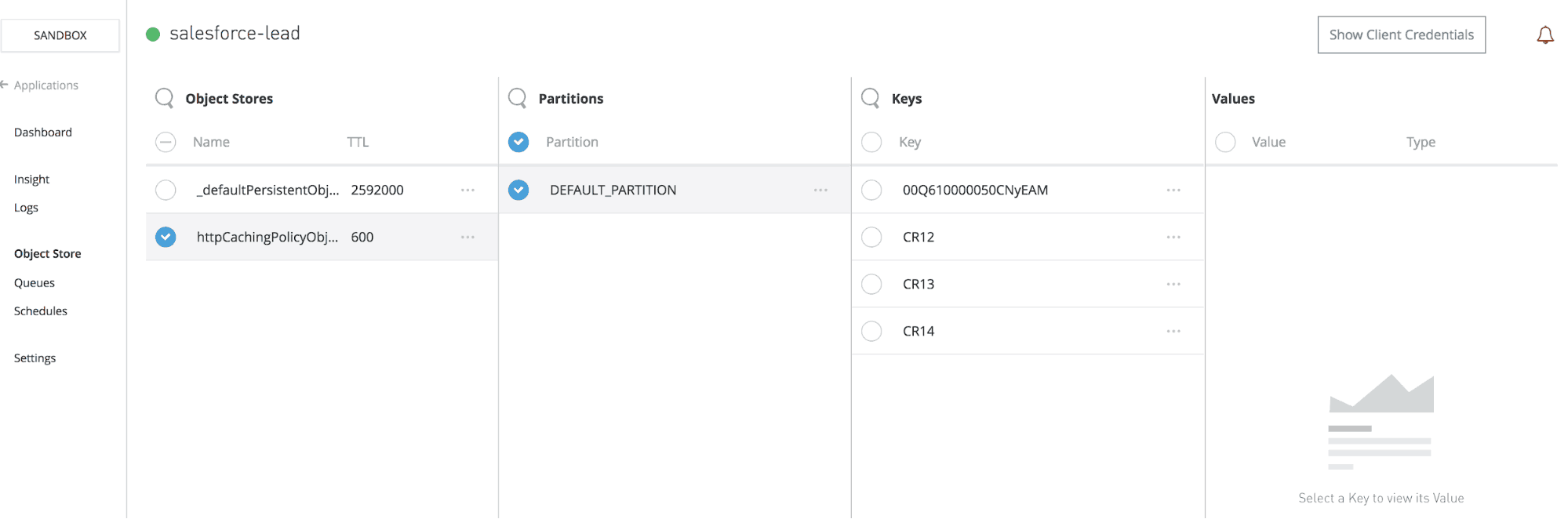
The maximum cached value is 1mb and values in Runtime Manager are shown in a binary format. Object Store doesn’t replace an actual database and is not suitable for every use case, such as cases when ACID semantics are needed or situations in which you expect the same cache key-value being updated in parallel.
Defining your stores using a custom policy
In some cases, you may need to write a custom policy for a service callout to an external resource. For example, consider a use case involving a JWT access token. Without caching, the custom policy issues a new token (JWT) with every request, even though the user credentials did not change. The CPU overhead for cryptographic signing of JWT can be costly. You can cache the signed JWT in a custom policy using caching extensions, which can increase performance dramatically. Here’s a quick pseudo sample of using a custom policy with object store caching extensions:
<object name="myObjectStore" class="com.mulesoft.anypoint.http.caching.CloudObjectStoreWrapper">
<property key="entryTtl" value="60000"/>
<property key="name" value="oauthTokenStore"/>
</object>
<http:request-config name="requestConfig">
<http:request-connection host="externaljwtservice.cloudhub.io" port="80"/>
</http:request-config>
<http-policy:proxy name="caching">
<http-policy:source>
<try>
<!-- Checking Cache for already stored value -->
<os:retrieve key="jwtToken" target="myVar" objectStore="myObjectStore"/>
<logger message="Value found in OSv2" />
<error-handler>
<on-error-continue type="OS:KEY_NOT_FOUND" logException="false">
<!-- If value not found, then retrieve it from the external system. -->
<http:request config-ref="requestConfig"
method="GET"
path="/"
target="myVar"/>
<logger message="Storing a new value in OSv2" />
<!-- After retrieving a fresh value, store it in the cache -->
<os:store key="jwtToken" objectStore="myObjectStore">
<os:value>
#[vars.myVar]
</os:value>
</os:store>
</on-error-continue>
</error-handler>
</try>
<!-- Use the retrieved value to add a new header -->
<http-transform:add-headers outputType="request">
<http-transform:headers>
[{'new-custom-header': vars.myVar}]
</http-transform:headers>
</http-transform:add-headers>
<logger message="#[vars.myVar]" />
<http-policy:execute-next/>
</http-policy:source>
</http-policy:proxy>
Java Code:
package com.mulesoft.anypoint.http.caching;
import static com.mulesoft.objectstore.cloud.api.ObjectStorePluginConstants.CLOUD_OBJECT_STORE_MANAGER;
import static org.slf4j.LoggerFactory.getLogger;
import org.mule.runtime.api.lifecycle.Disposable;
import org.mule.runtime.api.lifecycle.Initialisable;
import org.mule.runtime.api.lifecycle.InitialisationException;
import org.mule.runtime.api.store.ObjectStore;
import org.mule.runtime.api.store.ObjectStoreException;
import org.mule.runtime.api.store.ObjectStoreManager;
import org.mule.runtime.api.store.ObjectStoreSettings;
import java.io.Serializable;
import java.util.List;
import java.util.Map;
import javax.inject.Inject;
import javax.inject.Named;
import org.slf4j.Logger;
public class CloudObjectStoreWrapper implements ObjectStore, Initialisable, Disposable {
@Inject
@Named(CLOUD_OBJECT_STORE_MANAGER)
private ObjectStoreManager cloudObjectStoreManager;
private String name;
private Long entryTtl;
private ObjectStore delegate;
@Override
public boolean contains(String s) throws ObjectStoreException {
return delegate.contains(s);
}
@Override
public void store(String s, Serializable serializable) throws ObjectStoreException {
delegate.store(s, serializable);
}
@Override
public Serializable retrieve(String s) throws ObjectStoreException {
return delegate.retrieve(s);
}
@Override
public Serializable remove(String s) throws ObjectStoreException {
return delegate.remove(s);
}
@Override
public boolean isPersistent() {
return true;
}
@Override
public void clear() throws ObjectStoreException {
delegate.clear();
}
@Override
public void open() throws ObjectStoreException {
delegate.open();
}
@Override
public void close() throws ObjectStoreException {
delegate.close();
}
@Override
public List<String> allKeys() throws ObjectStoreException {
return delegate.allKeys();
}
@Override
public Map retrieveAll() throws ObjectStoreException {
return delegate.retrieveAll();
}
@Override
public void initialise() throws InitialisationException {
ObjectStoreSettings settings = ObjectStoreSettings.builder()
.entryTtl(entryTtl)
.persistent(true)
.build();
delegate = cloudObjectStoreManager.getOrCreateObjectStore(name, settings);
}
@Override
public void dispose() {
}
public void setEntryTtl(Long entryTtl) {
this.entryTtl = entryTtl;
}
public void setName(String name) {
this.name = name;
}
}
Benefits
So what are the benefits of an API caching policy? The key highlights of this policy include:
- Easy configuration
- Unified implementation – there is one policy which populates, invalidates, and implements lookups.
- Support for all deployment targets: CloudHub, Hybrid environments, and Runtime Fabric
- Ability to cache APIs dynamically using DataWeave expressions
- Easily skip and purge cache dynamically using header control
- Extensions that are fully supported by Custom policies
Key takeaways
Caching can be incredibly powerful, and it is necessary to ensure you are delivering the best experience for your customers, as well as managing the costs of your API. Caching can also make access to data less expensive. This can mean savings in either:
- Monetary costs, such as paying for bandwidth or volume of data sent; or
- Opportunity costs, like processing time that could be used for other purposes
Which use case are you planning to use this policy for? Let us know in the comments! You can also find more information about other API policies.



