
MuleSoft is happy to announce the upcoming release of distributed tracing – the latest update to Anypoint Platform’s monitoring capabilities.
As technology stacks become increasingly interconnected, it can be a challenge for IT teams to diagnose where cracks are forming in their integration pipelines.
Logging has been the traditional approach to solving issues; an application breaks, and you comb through the logs to decipher a fix.
But as your technology footprint begins to expand, logs themselves can create a bottleneck. They’re disjointed and have an application specific format; in order to get the full picture, you need to stitch them together and craft a solution.
This is easier said than done when you’re working with dozens or hundreds of applications.
Distributed tracing on the other hand, is focused around the requests being processed – not the disruption events being generated. They act as a header to each request that’s parsed from node to node. Think of it as injecting dye in a plumbing system to diagnose where you have leakage as opposed to looking for a geyser.
Operating in this way provides a holistic view of your technology stack and a more succinct understanding of the flow of data through it.
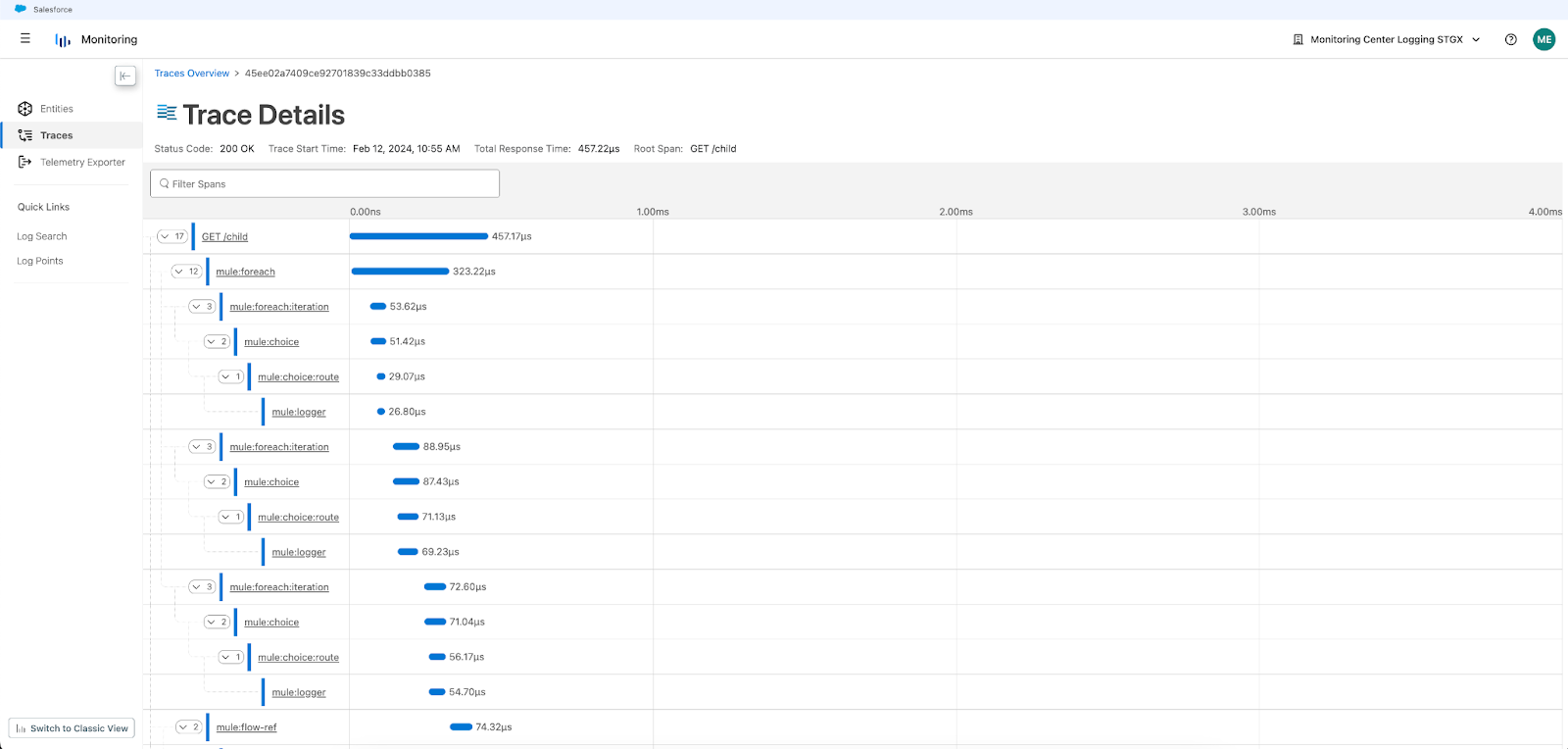
Follow that trace: What is distributed tracing?
Distributed tracing is the practice of appending what’s referred to as a “trace,” i.e. tracking metadata stored in a request header – to a subset of requests as they move across your application ecosystem.
The value of this approach is quicker diagnosis and remediation of errors due to contextual data from your whole application stack, as opposed to the slower, segmented analysis provided by individual application logs.
With the launch of distributed tracing in Anypoint Monitoring, users can now visualize how their requests are being executed across the MuleSoft ecosystem and perform root cause analysis much faster with a global search of the application nodes that their trace passed through.
At the time of writing, traces are only appended to a subset of requests. There is some flexibility in the percentage of requests that are traced, depending on the performance thresholds required by users.
This feature will be only available for users who have their applications deployed via Runtime Fabric or CloudHub 2.0.
Why it’s time to start with distributed tracing
Logs will always have their place as a technical support tool. But the near-exponential growth of technology stacks across the enterprise means that getting started with distributed tracing now ensures you’re set up for success as you continue to scale.
Leveraging this feature as part of the MuleSoft ecosystem negates the implementation headaches traditionally associated with adoption; distributed tracing is now firmly baked into Anypoint Platform. We’re committed to continuing to expand this functionality as part of the wider vision for the underlying MuleSoft platform.
Here’s something else to consider: the advent of AI in the world of monitoring.
Across the industry, distributed tracing functions by sampling a set of traces in order to diagnose recurrent issues. This is due to the challenge of capturing and analyzing the sheer amount of data generated when working with trace data spread across a broad application stack. It’s not infeasible that in the near future, LLMs will empower distributed tracing to focus exclusively on erroneous data by digesting and diagnosing the erroneous data near instantaneously.
Expanding the scope of AI’s impact even further, distributed tracing could potentially move beyond the realm of performance and provide insight into all issues and errors being thrown across your tech outlay.
If and when these changes happen, the benefit to organizations already mature in their understanding of the approach will reap the benefit to match the growing rate of their application footprint. So why not get started with Anypoint Monitoring today?
Distributed tracing for CloudHub 2.0 and RTF is currently in a public, opt-in beta.



