
LLMs are powerful. Since 2022, we’ve seen these AI models do things we would’ve never thought a computer could do.
They’ve passed the bar exam, sat for college entrance exams and even passed the Turing test. These models bring a tremendous amount of math and computational ability to bear on business problems, but how do we make sure they’re being used correctly? How do we make sure users aren’t abusing the LLMs to generate toxic content or “backdoor” their way into internal business systems? How do we protect ourselves from the enormous costs that can be generated by improper LLM use?
Ultimately, what does a well-managed LLM look like in a business in the first place? We intend to answer these important questions as we explore how MuleSoft can play a role in securing and governing your LLMs.
Let’s set the groundwork for what good LLM implementation looks like with a few guiding principles.
Principles of LLM security and governance
LLMs should be secured effectively. This likely doesn’t come as a surprise, at least at a high level, since securing business systems is one of the most important things an IT organization does. However, LLMs have some additional security considerations that need to be acknowledged and put into action.
Beware of prompt injection
If you plan to allow user input to go into a model as a part of a prompt, you open yourself up to prompt injection. This terminology borrows from its older brother, SQL injection, in which a user puts malicious SQL code into an input on a website and when that data makes it to the database it causes catastrophic consequences.
Prompt injection looks very similar. For instance, a user can get your LLM to behave a certain way by injecting malicious prompts into their messages with the model. In late 2023, a user “tricked” a car dealership’s LLM chatbot into selling a car to him for $1 because of how he phrased the prompt.
This type of attack can also extend into getting the LLM to expose what you’ve added to the prompt. Without getting too far into the weeds, if you’re adding internal business knowledge article data to your LLM prompts alongside user input, someone could potentially gain access to that internal data by prompting the model to return it to them.
LLMs can be prompted to produce malicious or violent content with relatively little effort. There are many online communities dedicated to jailbreaking these models to get them to behave in a way that is contrary to their filters and the intentions of their owners.
Control costs
In addition to security controls, LLMs should be cost controlled as well. LLMs are extremely expensive to run. If you’ve used any of the models, you know how quickly you can rack up a sizable cloud bill. This presents another attack vector, similar to a DDoS attack.
Where the goal with DDoS was to take down a business’s systems, this type of LLM attack is dedicated to driving up the cost associated with LLMs. It’s quite easy to accidentally make successive calls to LLMs that aren’t malicious. This can happen with a business developer working on a new LLM integration or a legitimate user making multiple high-cost requests. These costs rack up per token.
Keep LLM interfaces agnostic
LLM interfaces should be agnostic to the underlying model. Business developers or users shouldn’t know which model they’re interacting with. If users don’t know which model they’re interacting with, it makes jailbreaking the model more challenging. Jailbreaks are specific to the LLM in question, so obfuscating that is always helpful.
Making the interfaces agnostic also allows a business to leverage multiple models in a “mixture of experts” approach. If all your models accept the same input format and return the same output format, developers don’t have to program their apps specifically for each model. They can instead program to the abstracted interface.
MuleSoft UAPIM and AI
When we talk about managing these LLMs, what we’re really talking about is managing their APIs. Most businesses aren’t running their own in-house LLMs due to cost constraints, but even those who do interact with them via an API. Where there’s an API, MuleSoft can help manage it. In this case, we have a few API policies that might be of interest.
MuleSoft can help secure LLM prompts with a handful of policies aimed at policing what content makes it through to the model. Our Prompt Decorator policy for Flex Gateway allows you to specify additional messages that should be prepended or appended to the user prompt. This can allow you to inject system level prompts to prevent the model from exposing internal data.
Our Prompt Template policy allows you to restrict the prompts a user submits to a small set of controlled prompts. In this policy, users submit only the data that fills in the prompt, and not the actual prompt itself. This is useful if you don’t want users to be able to prompt the model on their own, and you just want a “fill-in-the-blank” prompt.
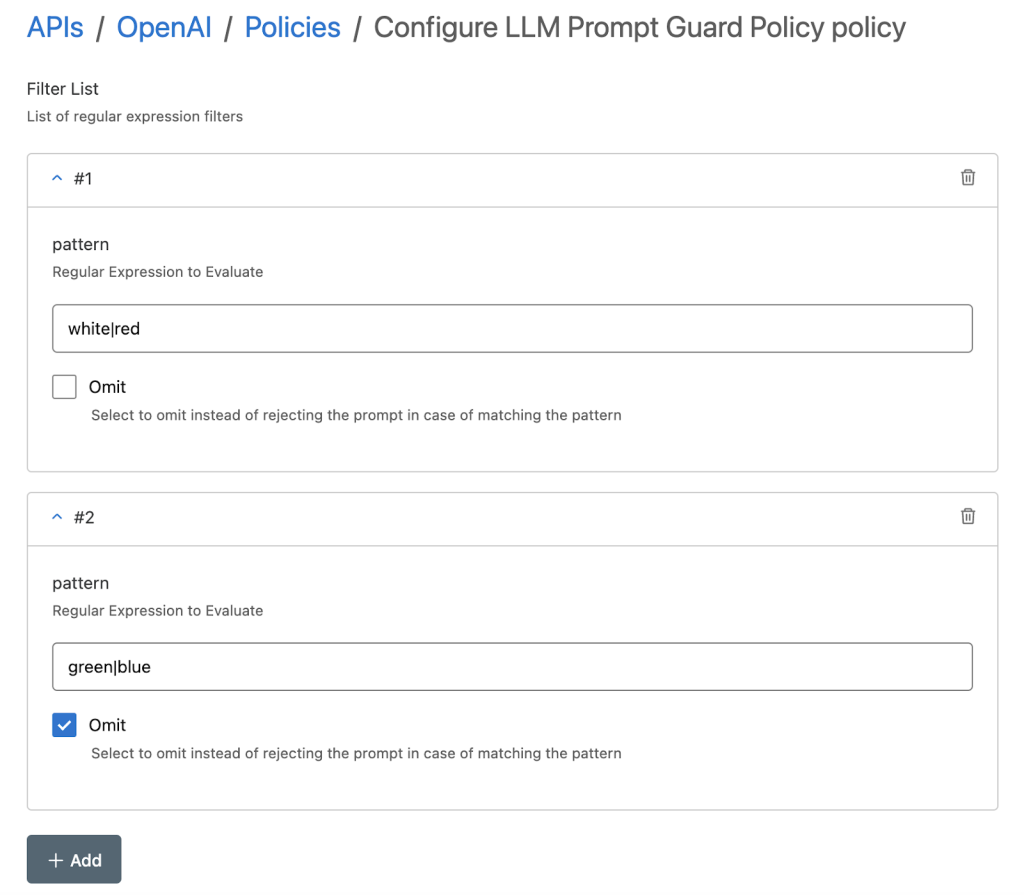
Additionally, our Prompt Guard policy allows you to set up block/allow lists for user input to prevent toxic language from reaching the model or being returned by the model. This also helps prevent models from being jailbroken to produce harmful content.
We help cost control your LLMs with our Token-Based Rate Limiting policy. Much like normal rate-limiting is effective in preventing traditional DDoS attacks or severe overuse, this policy allows you to specify how many LLM tokens should be allowed to pass through the model for a given period of time and rejects any requests beyond that.
All of these policies will be made available as sample policies for you to take and modify as necessary.
Secure, govern, and excel with MuleSoft UAPIM
MuleSoft is with you every step of the way on your journey to adopt AI. As you begin down this road, we can help you secure and govern your LLMs with UAPIM so that you can safely implement these powerful models in your business.



