
With data at the forefront of every business consideration, organizations constantly integrate massive volumes of data across systems – especially when feeding high-performance warehouses.
One of the most powerful tools for handling such integrations is MuleSoft, with its API-led approach and robust ETL (Extract Transform Load) capabilities. That said, optimizing data ingestion for complex, high-volume, and interdependent datasets still presents a challenge.
What we'll cover in this article: We’ll discuss how combining a unified Tuple Script approach with parallel pagination can boost ingestion speed, ensure atomicity, and simplify maintenance, especially with interdependent datasets like employee data.
What is a Tuple Script?
In databases, a tuple represents a single, complete record in a relational table – often referred to as a row. It is an ordered set of attribute values where each value corresponds to a specific column defined by the table schema. For example, a tuple in a table of employee information might consist of an employee’s ID, name, and salary grouped as one cohesive unit. Uniqueness is typically enforced via a primary key, maintaining data integrity.
In the context of this article, a Tuple Script refers to a dynamically generated SQL script that generates, inserts, manipulates, or processes tuples across multiple tables as a single, unified transaction.
MuleSoft’s DataWeave is an ideal tool for this, as its powerful transformation capabilities allow it to dynamically generate complex SQL strings.
A Tuple Script is used to:
- Insert multiple tuples into a table
- Generate test data or seed records
- Process query results row by row
- Slice datasets for parallel or batch operations
While “tuple” is the formal term from relational algebra, and “row” is its physical implementation, a Tuple Script operates directly on these units of data, serving as a foundational tool for many database operations, especially in ETL pipelines, testing, or performance-tuning scenarios.
Example in action: Employee data ingestion
At first glance, employee data ingestion may seem straightforward, but it involves complex relationships spread across multiple systems and tables: personal details, roles, job titles, payroll, benefits, and more. Missing a single element can lead to access issues, payroll delays, or compliance risks.
To better understand the complexity of employee data ingestion and why atomicity is crucial, take a look at the following Entity-Relationship (ER) diagram. It shows the interlinked nature of employee-related data spanning multiple tables including EMPLOYEE, POSITION, JOB, COMMUNICATION, PERSON, REMUNERATION, and more. These dependencies highlight why traditional one-table-at-a-time ingestion can easily lead to inconsistencies and partial records – especially when onboarding new employees or syncing HR systems.
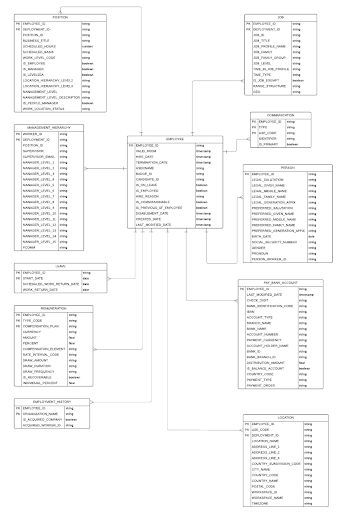
How atomic transactions help avoid data gaps
Consider a scenario of onboarding a new employee. Their information (e.g. personal details, job assignment, payroll setup, and system access) must be ingested completely and accurately. If any part of the process fails, partial data can lead to operational disruptions and compliance issues.
This is where transaction-scoped tuple execution becomes critical. It ensures that all related records are inserted, updated, or deleted as part of a single atomic transaction. If any step fails, the entire transaction is rolled back, which guarantees data consistency and prevents incomplete or inconsistent records from entering your systems.
Traditional vs. Tuple-based ingestion
| Aspect | Traditional ingestion (One table at a time) | Tuple-based ingestion (Unified transaction) |
|---|---|---|
| Execution model | Sequential inserts/updates for each table | All related data is processed in a single tuple script |
| Performance | Slower due to multiple round trips | Faster due to batching and reduced network overhead |
| Atomicity | No built in atomicity across tables | Full atomicity (all or nothing execution) |
| Risk of partial ingestion | High – failures can leave inconsistent records | Low – failures roll back the entire transaction |
| Complexity | Complex rollback logic if failures occur mid-process | Simple rollback via transaction scope |
| Error handling | Table-specific error handling needed | Centralized failure handling and fallback strategy |
| Maintainability | Harder to debug; multiple scripts and flows | Easier to audit and maintain; unified script per entity |
| Data integrity | Prone to mismatches or orphaned records | Guaranteed consistency across related tables |
| Scalability | Limited – hard to scale due to serialized operations | Highly scalable with parallel pagination and batch execution |
| Use case fit | Suitable for small or independent datasets | Ideal for complex, interdependent data (e.g. employee data) |
Engineering the solution: A step-by-step breakdown
This modern integration pattern hinges on three core technical components:
1. Parallel pagination for scalability
Instead of loading all records at once, we break them into batches using pagination and process them in parallel. This approach is ideal for handling millions of records with speed and efficiency.
%dw 2.0
output application/json
---
do {
var batches = (0 to floor((payload[0].TOTAL_RECORDS default 0) / Mule::p('snowflake.worker.updates.raw.query.limit')))
var lastBatchItem = batches[-1]
---
batches map (item, index) -> {
offset: if(index == 0) 0 else (item * Mule::p('snowflake.worker.updates.raw.query.limit')),
isLastBatch: (item == lastBatchItem)
}
} <foreach doc:name="publish batches">
<vm:publish ...>
<!-- Batch payload with offset and limit -->
</vm:publish>
</foreach><flow name="process-records" maxConcurrency="5">
<vm:listener ... />
<!-- Each batch is processed in parallel -->
</flow>2. Tuple script construction with DataWeave
The heart of the approach is dynamically generating a single, unified SQL script that operates on multiple tables as a single unit using MuleSoft’s powerful transformation language, DataWeave. The DataWeave script dynamically constructs INSERT, DELETE, and UPDATE statements by iterating through the data, ensuring perfect schema mapping and reducing ingestion failures.
%dw 2.0
output application/json
fun nullCheck(value) = if(isEmpty(value)) "null" else "'" ++ (value replace "'" with "''") ++ "'"
fun getValues(data) = (data map (rec) -> (
"(" ++ ((valuesOf(rec) map (item) -> nullCheck(item)) joinBy ",") ++ ")"
)) joinBy ","
// For each table, generate INSERT, DELETE, and UPDATE statements as needed
flatten((tableNames map (tableName) -> (do {
var creates = orderFields(createItems[tableName].fieldValues)
var deletes = orderFields(deleteItems[tableName].compositeKey)
var updates = orderFields(updateItems[tableName].fieldValues)
var stmts = []
---
(stmts + (
if(!isEmpty(creates))
"INSERT INTO " ++ tableName ++ " (" ++ (getKeys(creates) joinBy ",") ++ ") VALUES " ++ getValues(creates) ++ ";"
else ""
) + (
if(!isEmpty(deletes))
"DELETE FROM " ++ tableName ++ " WHERE (" ++ (getKeys((deletes map ($ filterObject ((value, key) -> !isEmpty(value))))) joinBy " || '_' || ") ++ ") IN (" ++ (deleteValues joinBy ", ") ++ ");"
else ""
) + (
if(!isEmpty(updates))
"UPDATE " ++ tableName ++ " as TGT SET " ++ getUpdateFieldAssignments(updates) ++ " FROM (SELECT " ++ getUpdateKeys(updates) ++
" FROM VALUES " ++ getValues(updates) ++ "
) SRC WHERE " ++ getPrimaryKeyCondition(vars.entityTableSummaries[tableName].keys) ++ ";"
else ""
)) filter !isEmpty($)
})) filter !isEmpty($))3. Transactional execution in MuleSoft
MuleSoft executes the generated tuple script inside a transaction scope, ensuring atomicity. If any batch fails, the system is configured to roll back the entire transaction, guaranteeing data consistency. To ensure continuity without compromising data integrity, a fallback mechanism can be implemented to process records one by one in parallel if a batch fails.
<flow name="execute-transaction-based-bulk-tuple">
<try transactionalAction="ALWAYS_BEGIN">
<set-variable value='#[vars.sqlScripts joinBy "\n"]' variableName="script" />
<flow-ref name="execute-script" />
<!-- Success/failure handling -->
</try>
</flow>Uncovering practical gains from tuple-based data ingestion
By combining Tuple scripts with MuleSoft’s DataWeave and parallel processing, organizations can transform their data ingestion pipelines. The result is:
- Guaranteed data integrity: All related employee data is written atomically
- High performance: Parallel pagination handles millions of records with speed
- Reduced errors: DataWeave ensures perfect schema mapping, reducing ingestion failures
- Simplified debugging: A single script per employee/entity makes issues easier to trace and fix
From brittle to scalable: A new era for enterprise data ingestion
Traditional ETL approaches are becoming outdated; they can’t keep up with the complexity and performance demands of robust modern enterprise environments. These methods often lead to inconsistencies and are difficult to maintain and debug due to their sequential nature. The lack of built-in atomicity across tables results in a high risk of partial ingestion failures, which can leave systems with inconsistent records.
By adopting a modern integration pattern that combines tuple scripting, transaction-scoped execution, and parallel pagination, organizations can transform their data pipelines. This approach guarantees data integrity because all related records for an entity are handled within a single atomic transaction. Any failure automatically triggers a rollback, ensuring data consistency and preventing incomplete records from entering the system. This method moves data ingestion from a brittle and slow process to one that is robust, scalable, and highly efficient.



