
Data is the fuel for artificial intelligence. Knowing this, most integration architectures remain app-centric, focused on connecting systems rather than enabling meaningful access to data.
This approach limits the potential of AI, which needs clean, connected, context-rich data to reason, respond, and act. To support AI-first initiatives, organizations must shift to a data-centric integration architecture.
What we'll cover in this article: We’ll explore the foundational areas that help you evolve toward a data-centric architecture, tailored to meet the needs of today’s AI-driven enterprise, including semantic and design; governance and quality; and enablement and delivery.
Before we get started, we’ve defined the following terms to help you:
- Semantic and design: Creating shared meaning with taxonomies, ontologies, and data modeling contracts
- Governance and quality: Ensuring trusted, compliant data for both humans and machines
- Enablement and delivery: Tracking how data flows, enabling reuse, and observing consumption patterns to continuously improve
From app-centric to data-centric integrations
Traditional integration strategies focus on connecting applications for specific use cases, e.g. syncing CRM with billing or pulling data from ERP into analytics platforms. While this has worked in the past, it often results in redundant data flows, tight coupling, and inconsistent semantics across systems.
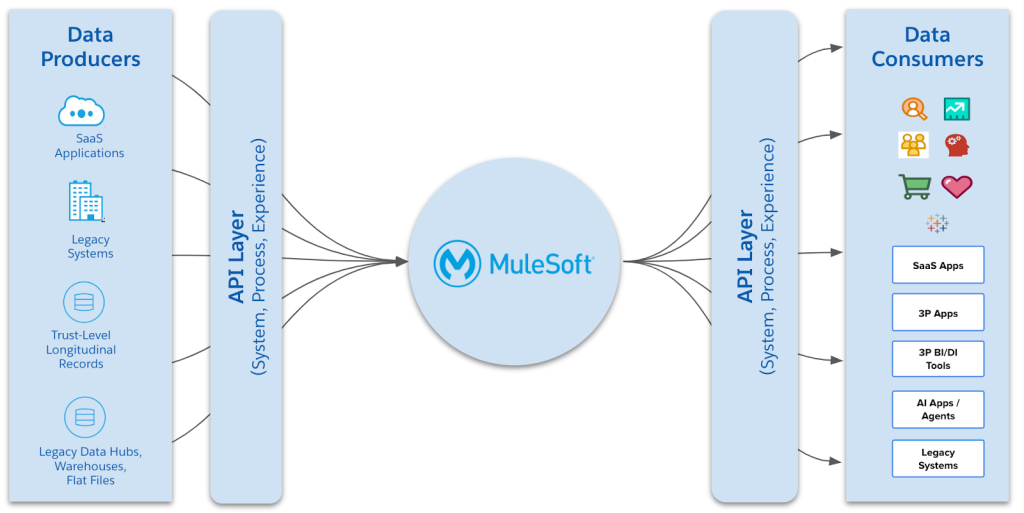
In an AI-first world, this approach is too brittle. Generative AI tools and intelligent agents depend on a broader, deeper understanding of enterprise data. They need to ask what the data means, whether the information is trustworthy, where the data came from, and what the latest version of the data is.
These questions require an architecture that treats data as a first-class citizen, not just a byproduct of app-to-app integration. A data-centric integration architecture addresses this gap by organizing around the meaning, availability, and trustworthiness of data. It promotes:
- Shared understanding through taxonomies, ontologies, and abstraction via data modeling contracts
- Consistent delivery via metadata-driven APIs and data fabrics
- Transparency and control through observability and governance
With MuleSoft’s rich ecosystem spanning APIs, integration, DataGraph, and governance, users are well-positioned to make this shift a reality.
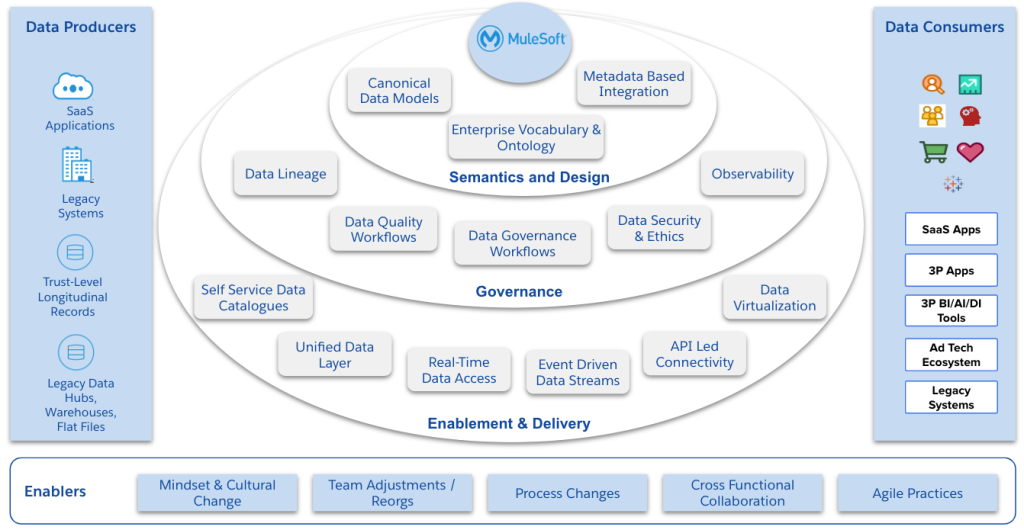
Practical steps to realize data-centric integrations in MuleSoft
To move from concept to implementation, organizations need a practical roadmap for embedding data-centric principles into their integration architecture. By aligning these data-centric principles with MuleSoft’s tools and patterns, teams can build integrations that treat data as a product, ensure consistency and trust, and support development of AI-driven use cases that rely on well defined, trusted and readily available data.
1. Semantics and design
| Canonical data model | – Define canonical data objects in Anypoint DataGraph or RAML DataTypes in the design center – Use reusable data types, API fragments, and reusable libraries in Anypoint Exchange for schema versioning, discovery and reuse – Enforce contracts with API policies and schema validation processors |
| Enterprise vocabulary and ontology | – Define a business glossary using Salesforce Data Cloud semantic layer or integrate with Collibra/Alation via API – Use custom annotations in RAML to tag APIs with business terms – Encourage common taxonomy use across domains via templates and governance |
| Metadata-based integration | – Design API-led integration layers (System, Process, Experience) to expose metadata-rich APIs – Store API metadata in Anypoint Exchange and use it for automated documentation and discovery – Enable policy-based routing and dynamic transformations using DataWeave based on metadata |
2. Governance
| Data lineage | – Use API naming standards and Exchange metadata to trace flows – Document integration flows visually in Anypoint Design Center – Tag logs and transactions with correlation IDs for traceability via Anypoint Monitoring |
| Data quality workflows | – Define data quality rules based on age, consistency, duplicationneeds – Use DataWeave to implement validations, cleansing, and standardization – Create reusable quality enforcement policies via API Manager – Route failed validations to queues or manual review workflows |
| Data governance workflows | – Integrate APIs with workflow engines for governance approvals – Embed policies into APIs to enforce governance at runtime – Track data access and updates via Audit Logging policies |
| Data security and ethics | – Enforce RBAC, OAuth2, and IP whitelisting via Anypoint API Manager – Mask or tokenize sensitive fields using custom DataWeave transformations – Log and audit data access for compliance purposes |
| Data observability | – Monitor latency, error rates, and throughput via Anypoint Monitoring and Runtime Manager – Enable log forwarding to SIEM/observability platforms – Create alerts and dashboards based on anomalies and performance thresholds. |
3. Data delivery and access layer
| Self-service data catalogs | – Use Anypoint Exchange as a central metadata catalog for APIs and data models – Integrate with third-party catalogs via connectors/APIs – Use the Developer Portal features to expose APIs with documentation, SDKs, and try-out tools |
| Unified data layer | – Use the Process API layer to abstract and unify data across systems – Use AnyPoint DataGraph to develop and expose unified, queryable data graph and compose multiple APIs into one logical schema with single endpoint – Enable access to Lakehouse type infrastructure via APIs or proprietary query mechanisms |
| Real-time data sharing | – Use Experience APIs with low-latency design for real-time access – Enable WebSockets or streaming APIs where needed – Use API Gateway policies to support QoS, throttling, and SLA tracking |
| Event-driven data streams | – Use MuleSoft’s support for JMS, Kafka, and AMQP for pub/sub messaging – Create event-triggered APIs using the “Listener” pattern with Anypoint MQ – Implement event enrichment and transformation using Mule event processors |
| API-led connectivity | – Design APIs in layers of System, Process, and Experience APIs with clear separation of duties for each API – Utilize Anypoint platform tools (API Designer, Exchange, Runtime Manager, and API Manager) to design, publish, and manage APIs efficiently – Enforce API policies, versioning, and deployment with automated pipelines to ensure security, consistency, and agility |
| Data virtualization | – Combine real-time APIs with on-demand querying using DataWeave transformations – Connect to diverse data sources (DBs, SaaS, legacy) using data virtualization platform connectors (REST or OData APIs) without replicating data – Enable data federation patterns using API composition |
Reimagining integration for the AI-first era
As organizations embrace AI and intelligent automation, the shift from traditional app-centric to data-centric integration is essential. In this new paradigm, data is not just a byproduct of applications but the fuel for innovation, personalization, and decision intelligence.
By rethinking integration through the lens of data, anchored in semantics and design, strengthened by governance and enablement, and brought to life through delivery, enterprises can unlock agility, trust, and reuse at scale. MuleSoft offers a powerful foundation to orchestrate these capabilities, bridging the gap between application connectivity and data accessibility.
The journey to data-centric integration is not a one-time migration, but a strategic evolution. It demands a shift in mindset, method, and tooling, but the reward is a more adaptive, AI-ready enterprise architecture. Now is the time to lead this transformation with a data-first approach that makes any API an agent-ready asset with MuleSoft.



