
So far, in this series, we have covered Migration, Broadcast, Bi-Directional Sync, and today we are going to cover a new integration pattern: Correlation. In an effort to avoid repeating myself, for those who are reading through the whole series, I will omit a lot of relevant information which is shared between the patterns that I have previously covered. I urge you to read at least the previous post about bi-directional sync as correlation can be viewed as a variation of bi-directional sync. Also, note that this is the only one of the five patterns that we have not released any templates around, this was done in the interest of time, and due to the belief that this may be the least common pattern for Salesforce to Salesforce integration. We are however looking to create and release templates using the correlation pattern in the next few months.
Pattern 4: Correlation
What is it?
The correlation pattern is a design that identifies the intersection of two data sets and does a bi-directional synchronization of that scoped dataset only if that item occurs in both systems naturally. Similar to how the bi-directional pattern synchronizes the union of the scoped dataset, correlation synchronizes the intersection. Notice in the diagram below that the only items which will be meet the scope and synchronized are the items that match the filter criteria and are found in both systems. Whereas with the bi-directional sync will capture items that exist either in one or both of the systems and synchronize. In the case of the correlation pattern, those items that reside in both systems may have been manually created in each of those systems, like two sales representatives entering same contact in both CRM systems. Or they may have been brought in as part of a different integration. The correlation pattern will not care where those objects came from, it will agnostically synchronize them as long as they are found in both systems. Another way to think about Correlation is that is like a bi-directional sync that only does updates existing matches, rather than creates or updates.
Why is it valuable?
Correlation is useful in the case where you have two groups or systems that want to share data only if they both have a record representing the same item/person in reality. For example, lets say you are a hospital group with two hospitals in the same city. You may think something like “Hey, lets share data between the two hospital so if a patient uses either hospital, we will have a up to date record of what treatment they received at both hospitals.” To accomplish an integration like this, you may decide to create two broadcast pattern integrations, one from Hospital A to Hospital B, and one from Hospital B to Hospital A. This will ensure that the data is synchronized, however you will have two integration applications to manage. To alleviate the need to manage two applications, you can just use the bi-directional synchronization pattern between Hospital A and B. But then you may think “Man, I wish there was a way to only bring the patient record from the other hospital if I create a record for the same person in this hospital.” Meaning that the synchronization should not bring the records of patients of Hospital B if those patients have no association with Hospital A and it should bring it in real time as soon as the patient’s record is created. The correlation pattern is valuable because it only bi-directionally synchronizes the objects on a “Need to know” basis rather than always moving the full scope of the dataset in both directions.
When is it useful?
The correlation pattern is most useful when having the extra data is more costly than beneficial because it allows you to scope out the “unnecessary” data. For example, if you are a university, part of a larger university system, and you are looking to generate reports across your students. You probably don’t want a bunch of students in those reports that never attended your university. But you may want to include the units that those students completed at other universities in your university system. Here, the correlation pattern would save you a lot of effort either on the integration or the report generation side because it would allow you to synchronize only the information for the students that attended both universities. Or if you are a sales organization, you may want to synchronize data about accounts with other organizations, but you only want to do it for accounts that you both have, and you don’t want to send other accounts to each other. You could not do this automatically without knowing which accounts the other organization has without employing a similar pattern of thought.
What are the key things to keep in mind when building applications using the correlation pattern?
Given that the correlation pattern is almost the same as the bi-directional sync, the same considerations apply, so I would again recommend that post to understand it better. The main difference is in the impact of how you define the Same.
Definition of Same:
The main thing to be careful about is how you define “same” for the records. This will differ by industry and use case and the degree to which it is harmful will also differ by industry and use case. Below is a table which shows what happens when you do it just right and if your filter is stricter or looser than it should be. You will notice that both correlation and bi-directional sync differ in what they do when the criteria is just right or too strict, but they are both susceptible to merging incorrect records if you don’t properly define what “same” means.
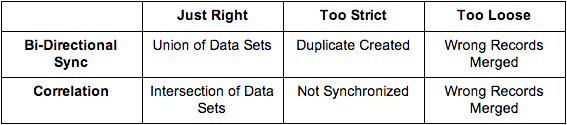
Lets for a moment imagine what could be the outcome of incorrectly defining the criteria which evaluates if two records in two different systems are the same. Lets imagine an innocent case at first where we are running an ecommerce site and our criteria for someone being the same customer is the first and last name of one customer being the same as someone else. And lets say that we use that data to send recommendations to this person via email. We may have a system that stores the purchase history and one that saves the emails. We would end up with an error where both people receive the union of their recommendation, so it may or may not end up looking completely funky to the users once their receive the emails. This has the potential to be completely benign or can really upset one of the two if they start receiving recommendations for products that don’t match their style. Now lets imagine a much more dangerous situation where we are running a hospital and via our synchronization we find out that this person “John Wayne” was recently treated for leukemia, when in reality that is information from someone else’s record. This could result in a lot of fatalities. Hence it needs to be something much more unique like a hash generated from name, last name, social security number, birth date, and city of birth to increase the degree of uniqueness. But imagine that two babies are born in the same hospital the day after Star Wars came out, named “Luke”, by two families with the last name “Johnson”, and that their SSN numbers are only 1 number off. Given that they probably will live in the same city, chances are that they will visit the same clinics and hospitals. And so they are only apart even in that hash by 1 wrong key strike when they fill in their information. So being very careful to pick the right definition of unique is very important when dealing with high sensitivity information.
In summary, we took a look at the 4th pattern that we will be using for templates: Correlation. Although this one is not yet used in any of the templates that we have shipped, it will be added in the near future. Correlation is the intersection of datasets as opposed to bi-directional sync which is the union of the datasets. In the next post we will talk about the fifth pattern which is Aggregation – stay tuned!
Check out our Anypoint Templates for Salesforce Integration!



