
APIs weren’t built for machines that think. They were built for developers, dashboards, and UI components – tools that ask, fetch, and render. However, autonomous agents want answers, not a list of records or an error code. If your APIs only expose data, you’re feeding intelligence with noise. To stay relevant in the world of agentic AI, your APIs must evolve from endpoints to reasoning frameworks.
In traditional systems, APIs served as simple data gateways that retrieved records, executed commands, and updated enterprise systems. But that model is no longer sufficient. Today’s agents are not just consumers of data – they are consumers of meaning. They require clarity, context, and semantic understanding to function effectively.
Consider the foundational differences between traditional APIs and what agentic systems demand:
| Aspect | Traditional API design | Agentic API design |
|---|---|---|
| Purpose | Expose operations or data | Enable autonomous decisions |
| Interface granularity | Fine-grained (CRUD-style) | Goal-oriented, task-centric |
| Data output | Raw, record-level JSON | Semantically enriched, structured meaning |
| Consumer | Human developer or UI | Autonomous agent or LLM |
| Integration Flow | Compositional, service chaining | Declarative, knowledge-driven |
| Architecture dependency | Microservice orchestration | Semantic layers and contextual services |
The real challenge is transforming your APIs, not just scaling them, which begs the question: Are your APIs built to enable autonomous reasoning, or are they still just plumbing for data?
What we'll cover in this article: We’ll explore how API design must transform to support agentic architectures and why a microservice-heavy approach can become a hindrance when building for AI-native systems.
The microservices trap: Why granularity hinders intelligence
Over the past decade, microservices have emerged as a cornerstone of modern, scalable software architecture. They offer modularity, independent deployment, and developer autonomy. Each service handles a specific business capability and exposes APIs for external interaction usually through REST or gRPC.
In conventional application ecosystems, this model works well. But in the agentic AI world, where autonomous agents need to make decisions, act across systems, and optimize outcomes, microservices alone fall short. Why?
- Fragmentation of logic: Microservices are intentionally narrow in scope. While this benefits code maintainability, it forces agents to compose meaning from multiple scattered endpoints, increasing cognitive load.
- Lack of semantic cohesion: While there are protocols like Model Context Protocol (MCP) that offer a promising way to wrap APIs with structured context, the effectiveness of MCP still relies heavily on the clarity and coherence of the underlying APIs. If APIs return fragmented or overly granular data, MCP must do additional work to stitch together meaning, compensating for architectural complexity rather than leveraging semantically rich interfaces. Even with microservices in place, semantic cohesion at the API layer is critical to reduce reasoning overhead and enable intelligent agent behavior.
- Brittle integration paths: Chaining low-level services increases fragility. An agent making five to eight API calls to construct a basic task risks failure at every step and loses clarity with each hop.
In cluttered environments with fragmented services, brittle data flows, and inconsistent integrations, agents struggle. Microservices give you modularity, but they don’t give agents the clarity they need to reason. An architecture built only on microservices is dense, inconsistent, and hard to navigate for agents. They need clarity, context, and semantic consistency to perform tasks autonomously, rather than wrestling with endless endpoints.
3 things your APIs must provide for AI agents
Because agents are autonomous workers, planners, and collaborators, they occasionally need to assess situations and understand goals and intent without human input. But to do that, they need three critical things: clarity, context, and semantic consistency. Let’s take a look at each in more detail.
1. Clarity
Agents should not need to reverse-engineer logic from multiple microservices. Instead, expose high-level endpoints that align with business intents. Imagine an agent trying to determine whether a customer is eligible for a personalized credit offer. In a traditional microservices setup, the agent might need to call:
- GET /customerProfile
- GET /accountStatus
- GET /paymentHistory
- GET /offerEligibilityRules
Then stitch these responses together to evaluate eligibility. This is not only inefficient, but burdens the agent with orchestration logic.
What agents really want is a single, context-rich endpoint like GET /customerEligibilityStatus that encapsulates all the logic and returns a semantically meaningful, complete response in one go, allowing them to act, not analyze. Agents shouldn’t be burdened with orchestrating fragmented business logic across multiple services.
For AI agents to work effectively, APIs should encapsulate the domain’s intent and surface only what’s relevant. When you abstract away internal complexity and design with business goals in mind, you create clarity for both humans and agents.
2. Context
Most microservices or APIs return flat or unstructured data. Even when an agent receives the right data, it still needs help understanding what that data means. Agents need relationships, data causality, and domain understanding embedded in the response.
This is where contextual enrichment becomes essential. Let’s revisit the Customer Eligibility Status example. When an agent calls GET /customerEligibilityStatus, the response like one below isn’t very helpful to AI agents.
{
"creditScore": 688,
"missedPaymentsLast90Days": 2,
"accountStatus": "Active"
}An enriched response that includes semantic tags and metadata would look more like:
{
"eligibility": "Pre-approved",
"confidenceScore": 0.92,
"rationale": "Credit score above threshold; minor payment delays within acceptable range"
}This contextual enrichment where the API doesn’t just expose raw data but provides meaningful insights gives the agent both the data and the reasoning needed to take intelligent action without reverse-engineering logic from raw numbers.
Contextual enrichment of API responses enables a complete understanding for AI agents with interpretation and domain logic, thus reducing cognitive load and enabling intelligent automation.
3. Semantic consistency
Agents rely on stable data contracts and consistent domain schemas to reason and act effectively. However, in microservice driven environments, frequent changes to service interfaces or data structures can break integrations and disrupt agent workflows. To support agentic behavior, APIs must offer consistent, predictable outputs that remain robust even as underlying services evolve.
This becomes especially critical in automation pipelines, where even a small change in schema can lead to downstream failures or misinterpretation by agents. Consistent, well-governed APIs foster trust, reduce cognitive overhead, and enable scalable reuse – paving the way for agents to operate autonomously and accurately.
For AI agents to be able to scale, your broader architecture must connect systems and actively support reasoning. That shift starts with how you structure your integration, domain data, and semantic layers.
Architecting for agent-ready API Ecosystem
In an agentic system, your API is powering a thinking machine. The interface must provide everything that machine needs to reason and respond intelligently. So how do you design APIs that agents can think with?
Integration layer
Adopt an integration layer built on composable architecture as your scalable, reliable backbone. This streamlines connectivity, reduces complexity, and ensures each service is purpose-built and reusable. By decoupling capabilities into well-defined, interoperable components, the architecture can evolve into modular services providing agents with predictable, well-governed API endpoints that are easy to discover and consume.
MuleSoft’s Anypoint Platform supports this by providing unified API design, development, and management capabilities, enabling you to build and govern reusable, discoverable API products across teams and environments.
Domain data layer
Implement a domain data layer based on data mesh principles to abstract complexity, delivering clean, domain-specific data products that align with your organization’s “digital vocabulary,” e.g. the nouns (customers, orders) and verbs (create, cancel). This approach empowers teams with domain ownership, self-service capabilities, and federated governance.
This layer holds the data products federated by domain teams with the goal of serving analytical aspects, while the API layers serve the transactional aspects of the organization.
These data products are no longer split into centralized buckets but are designed to be cross-functional. Data products with analytical foundations enrich the semantics so agents can interpret historical patterns, suggest actions today, and help plan the future. They’re also a key enabler for the semantic layer, since agents cannot derive meaningful insights by relying only on operational and transactional data.
With MuleSoft, organizations can use integration templates, connectors, and API-led connectivity patterns to expose data as governed, domain-specific products, while ensuring compliance and governance policies are enforced automatically.
Semantic layer
The Semantic Layer adds meaning and context to the data exposed by APIs. It connects individual data points with business logic, relationships, and intent – helping agents interpret not just what the data is, but why it matters. This layer is crucial for enabling agents to reason and make informed decisions rather than merely executing calls.
MuleSoft’s support for Model Context Protocol (MCP) to add API semantics in a machine-readable way, positions it as a powerful platform for operationalizing the Semantic Layer. By allowing developers to enrich APIs with contextual metadata and intent, MuleSoft ensures that APIs aren’t just technical endpoints, but meaningful interfaces agents can understand and act upon.
To help illustrate this shift visually, the following diagram compares a traditional microservices approach with a MuleSoft-powered architecture. It captures how each paradigm approaches integration, data exposure, and semantic layering—and why the MuleSoft approach better equips you to support intelligent agents.
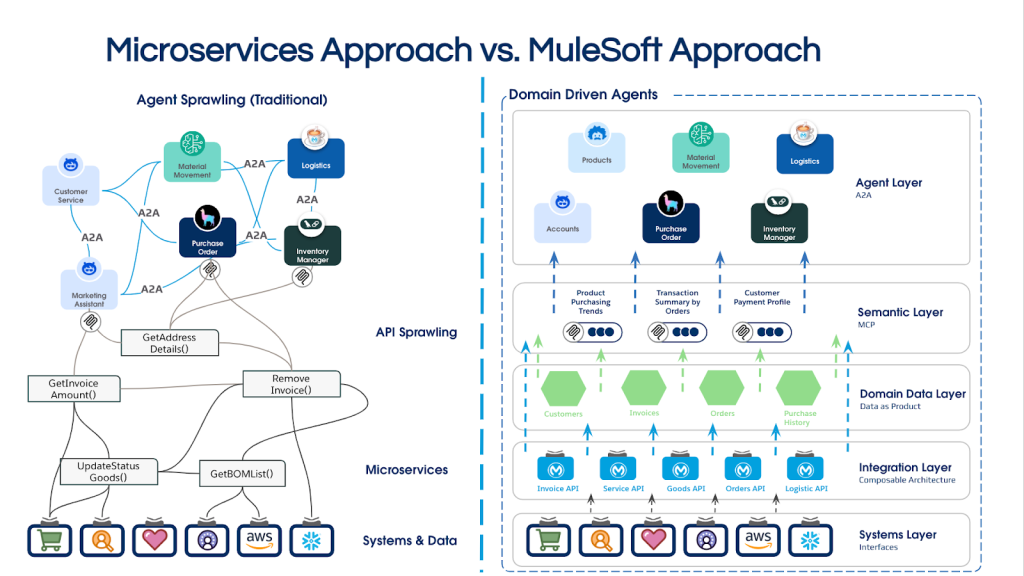
Before you add AI agents, simplify the terrain
Many organizations are eager to plug intelligent agents into their architecture. However, if your current enterprise environment is a dense jungle of microservices, fragmented databases, and inconsistent APIs, adding agents will only expose these flaws faster. Don’t drop agents into a system that isn’t ready to support reasoning.
Start by simplifying:
- Rationalize microservice sprawl
- Consolidate APIs around domain-centric interfaces
- Standardize contracts and schema governance
Only then can agents operate with confidence and your architecture evolve into a truly intelligent system.
Design for understanding, not just access
APIs can no longer be viewed as simple data gateways. They must evolve into meaningful interfaces that deliver knowledge. Here’s what that means for your design philosophy:
- Treat APIs as cognitive building blocks
- Prioritize semantics over syntax
- Expose business intent alongside business data
- Enable agents to act with context, not just code
Agents want understanding. People who redesign their APIs for intelligence will define the future of agentic interaction. In an era where machines interpret and act on meaning, your APIs need to be decision frameworks.

