
When surfacing data from systems of record, one of the concerns designers and developers need to address is the potential of retrieving an enormous number of results in a single load session. This requires significant processing power on both the client and server sides and network traffic, and can degrade the overall data consumption and experience.
There are different approaches to address this concern, but one of the most widely used is the concept of pagination. Pagination is a term commonly used to describe the process of a sequential division of the contents (fetched data) into separate pages. This relieves the pressure on both sides of communication and its channel.
In most cases, systems of record (databases) offer out-of-the-box features to enable pagination — in this post this will be referred to as “simple pagination.” However, that’s not always the case, since APIs can choreograph calls to each other to collect and combine results that provides a paged result set to the consumers. It’s often up to application designers and developers to come up with a suitable solution.
In this post, we are going to explore how to deal with single and composite result sets. You’ll learn how to retrieve data out of a single data source as well as how to paginate results from two or more source systems.
Single/simple pagination
Simple pagination describes the technique and support of systems of record to provide paginated results without too much additional logic or complex implementation. Databases (relational or NoSQL/Cache) are great examples of systems of records that support simple pagination by allowing developers to write commands to query paginated data. They require an OFFSET and a LIMIT, which determine where to start from and the maximum number of rows to be fetched.
Some APIs allow consumers to provide an OFFSET and a LIMIT for the purpose of getting paginated payloads, either by using query parameters or headers as part of the HTTP request. Another option is limiting the number of records per page at an API level — so that instead of consumers specifying an OFFSET and a LIMIT, they only specify what page they want to get. While this approach is less flexible on the consumer side, it increases the levels of control on the API side.
Composite/complex pagination
Composite or complex pagination describes an approach and a technique implemented in Anypoint Platform to allow Mule applications to consolidate data from two or more different (paged) result-sets. This provides a simple pagination experience, where the server is responsible for keeping track of the appropriate OFFSET and LIMIT to the different data sources. From an API consumer’s perspective, there is only one data-set.
Though there are many options, the goal is to give consumers the experience of paginating results as if this was coming from a single result set while leveraging what is available out-of-the-box in Mule. By leveraging ObjectStore and some DataWeave code, we can build a logic that maintains the OFFSET and LIMIT to each data-set source while merging them into a single result-set.
Let’s see it in practice now, starting with API design, followed by implementation and finishing with a consumer.
API pagination example
We are going to put the above concepts into practice by implementing a simple RESTful API with two resources, and a consumer that outputs CSV files and delivers them to a local directory. In this example, we demonstrate simple pagination by implementing an API with two endpoints:
- /products
- This endpoint exposes product information, surfacing data from an H2 in-memory “Products” database as a single resultset (simple pagination).
- /contacts
- This endpoint exposes contact information, surfacing data from two different H2 in-memory databases: “Customers” and “Suppliers,” merged as a single resultset (complex pagination).
API design
In Anypoint Platform Design Center, start designing a new API named “mulesoft-pagination-api,” which will be extremely simple, compact and use the following RAML:
#%RAML 1.0
title: MuleSoft Pagination API
mediaType:
- application/json
version: 1.0.0
protocols:
- HTTP
/products:
get:
queryParameters:
offset:
example: 1
type: number
format: int
limit:
example: 20
type: number
format: int
responses:
"200":
body:
type: object
properties:
nextOffset: integer
morePages: boolean
results:
type: array
items:
properties:
id: integer
name: string
/contacts:
get:
queryParameters:
offset:
example: 1
type: number
format: int
limit:
example: 20
type: number
format: int
responses:
"200":
body:
type: object
properties:
nextOffset: integer
morePages: boolean
results:
type: array
items:
properties:
id: integer
name: string
When this is done, publish the API definition to Exchange and switch to Anypoint Studio to start implementing the API.
API implementation
From Anypoint Studio, create a new Mule application based on the API definition that we have put in place before. After the project is created, add all required application dependencies and configuration files.
Dependencies and configuration (POM, YAML, Mule-artifact)
In terms of application dependencies and configuration, the POM file should be modified by adding Mule DB Connector and H2 Database as dependencies.
. . .
<dependency>
<groupId>org.mule.connectors</groupId>
<artifactId>mule-db-connector</artifactId>
<version>1.5.5</version>
<classifier>mule-plugin</classifier>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
<scope>compile</scope>
</dependency>
. . .
A YAML file should be created and its contents should be details of each database connection including URL, driver, username, and password.
. . .
api:
database:
driver: org.h2.Driver
products:
url: "jdbc:h2:mem:products;INIT=RUNSCRIPT FROM 'classpath:database/products-db.sql'"
user: eduardo.ponzoni
password: Mu13.D4t@C0m
customers:
url: "jdbc:h2:mem:customers;INIT=RUNSCRIPT FROM 'classpath:database/customers-db.sql'"
user: eduardo-ponzoni
password: Mu13-D4t@C0m
suppliers:
url: "jdbc:h2:mem:suppliers;INIT=RUNSCRIPT FROM 'classpath:database/suppliers-db.sql'"
user: eduardoponzoni
password: Mu13D4t@C0m
. . .
The Mule-artifact JSON file should have a description for class loading containing three SQL files as exported resources: products-db.sql, customers-db.sql, suppliers-db.sql.
{
"configs": [
"mulesoft-pagination-api.xml",
],
"minMuleVersion": "4.2.2-hf2",
"name": "mulesoft-pagination-api",
"classLoaderModelLoaderDescriptor": {
"id": "mule",
"attributes": {
"exportedResources": [
"database/products-db.sql",
"database/customers-db.sql",
"database/suppliers-db.sql",
]
}
}
}
In-memory databases
We start by creating the structure of the three in-memory databases. The engine and driver are going to use the H2 database. Each of the in-memory databases have the same structure, so that we have a simple model to apply the pagination logic to. Each database consists of a single table. Corresponding SQL scripts to create and populate tables will be contained within the API resources directory.
Scripts
products-db.sql
CREATE TABLE products (
id INT NOT NULL
name VARCHAR(100) NOT NULL
);
INSERT INTO products VALUES (1, 'Official Brazil Football Supporters Jersey');
INSERT INTO products VALUES (2, 'Official All Whites Supporters Jersey');
INSERT INTO products VALUES (3, 'Official All Blacks Supporters Jersey');
. . .
customers-db.sql
CREATE TABLE customers (
id INT NOT NULL
name VARCHAR(100) NOT NULL
);
INSERT INTO customers VALUES (1, 'John Smith');
INSERT INTO customers VALUES (2, 'Anthony Taylor');
INSERT INTO customers VALUES (3, 'Peter McDonald');
. . .
suppliers-db.sql
CREATE TABLE suppliers (
id INT NOT NULL
name VARCHAR(100) NOT NULL
);
INSERT INTO suppliers VALUES (1, 'New Zealand Power');
INSERT INTO suppliers VALUES (2, 'Kiwi Light');
INSERT INTO suppliers VALUES (3, 'Aotearoa Energy');
. . .
When this is done, create a new Configuration Properties (Global Element) in the application configuration file (XML) pointing to the corresponding YAML file and the implementation flows for both resources can be implemented, starting with /products (simple pagination).
Simple pagination
When it comes to implementing simple pagination, all we have to do is connect the in-memory “products” database and run a SQL query against the “products” table using the OFFSET and LIMIT.
Pagination happens naturally and organically using query parameters as the initial position of the result set and the maximum records to be fetched per page.
Complex pagination
This solution has to adhere to the principles that guarantee that we only use MuleSoft (flows, transformations, Object Store) to cater for the pagination requirements, and that returned pages will always contain a ratio of 50% records from each result set (since we have two). If a third result set would come into the picture, the ratio would be down to 33.33% and continue to decrease as we add some more.
The diagram below illustrates how the logic applies to achieve this:
Once a request is received, a hash of the request attributes needs to be generated, which is used as a key to an object cached in the ObjectStore. Check if the object exists — and if it does, we get the value for that key. This will tell us the specific OFFSETs of the two data sources. If there is nothing, generate a default one using the parameters (OFFSET and LIMIT) received from the HTTP request.
Next, using scatter-and-gather make two calls to the underlying systems of record (consumers and suppliers databases in this example) and use DataWeave to merge and transform the paged results. This guarantees that we have the appropriate portion of records from each result set, so that the page consists of the number of records requested by the user and that the combined result set always contains data from both sources.
Finally, we generate a key to ObjectStore to be associated with a value (JSON) that contains the OFFSET to retrieve the next page (latest OFFSET) and the corresponding OFFSET for each of the data sources (latest OFFSET). This way, when a request for the next page is received, the API already knows what the actual OFFSET to query the two different databases.
To shed some more light on the above, let’s suppose that the user has requested a maximum of two rows (LIMIT) starting from position four (OFFSET). After fetching the records from each data source, we have got the following contents:
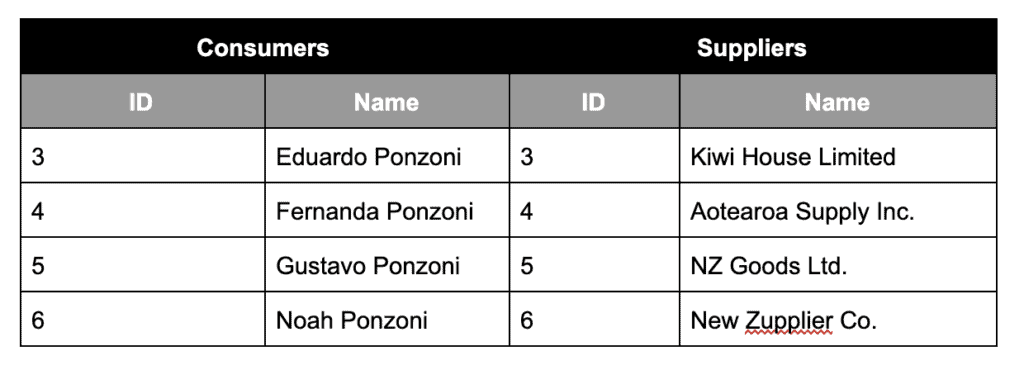
The logic will guarantee that the output (merged/paged contents) will look like:
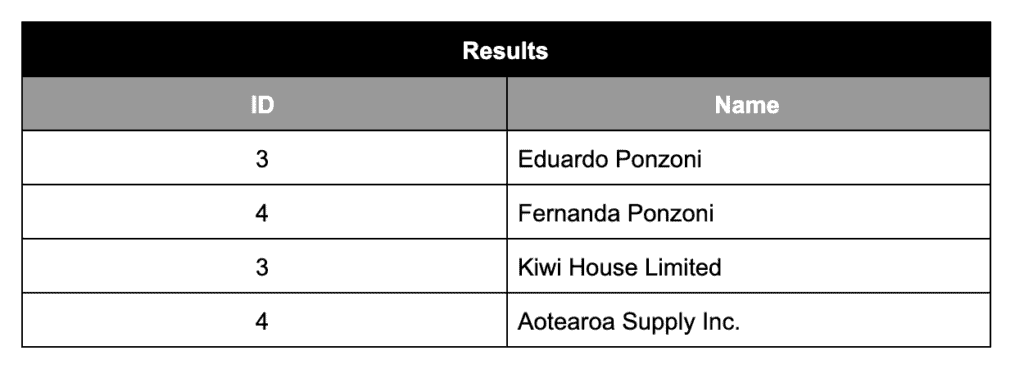
Suppose the pagination goes even further and the user requests another page using LIMIT 4 and starting position 20. The results fetched from both databases looks like this:
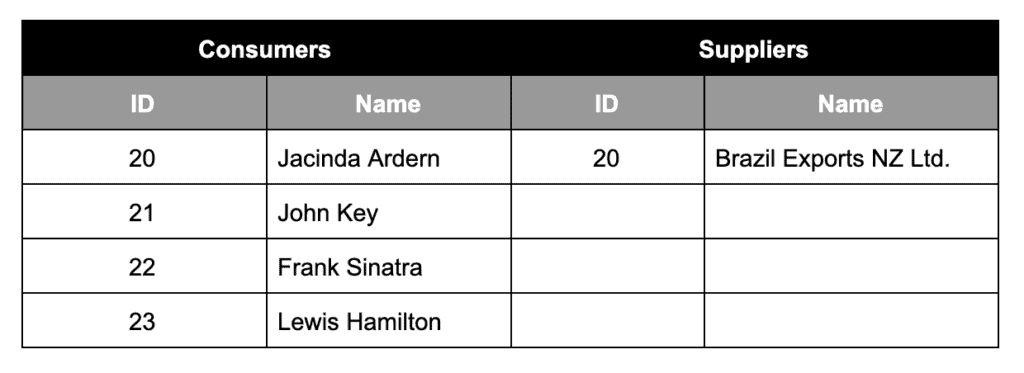
After applying our merging logic/paging logic, this will be the output:
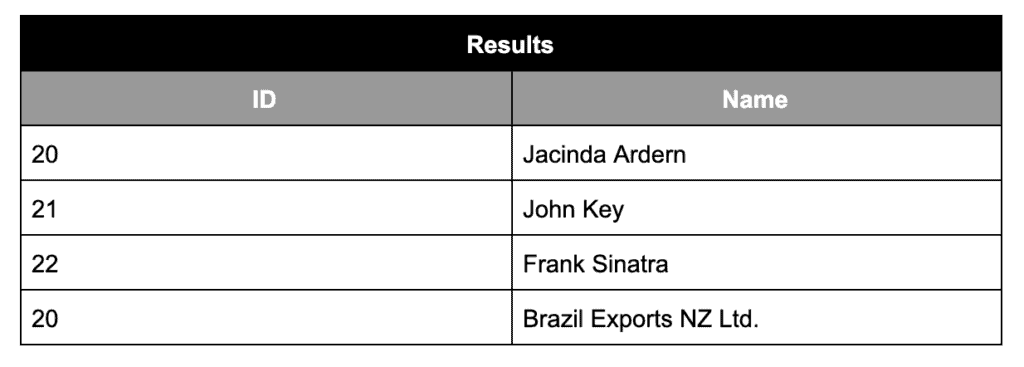
The logic caters for balancing the right amount of rows returned from either result sets. Now, turning back to Mule flow, when implementation is finished, it should look like this:
In the database SELECT statements, we use the OFFSET for customers and suppliers that was previously retrieved from ObjectStore as part of the SQL statement, like in /products. The DataWeave code that slices and merges the contents of the result sets to match what the API consumer has been requested. This is what it looks like using a default page size of 20 records per page:
To explain this code, it starts at line five by defining the half limit, so that it’s possible to determine how many rows from each of the datasets are meant to be taken.
At lines six and seven, we calculate what is the actual size of each collection when sliced. At lines eight and nine, we determine what is the actual limit for each of the lists and the next lines effectively determine what the output collections would be for customers and suppliers, given the limits and at line 12 the results are merged.
Lastly, the standard JSON output begins at line 19 onwards, where we determine if there are more records to be fetched (next page) as well as pre-emptively determine what the next page would be — the actual OFFSET for both lists of customers and suppliers. That will be used and stored as the next page’s OFFSET Control in ObjectStore, so when an API consumer requests the next page, we know that the real OFFSET of customers and suppliers.
Conclusion
This same approach can be modified in many ways and tailored to what your application needs, still maintaining the core and surfacing data in a paged fashion. For more tutorials and guides using Anypoint Platform, check out our developer tutorials.



