
Currently, Mule relies on plain old java serialization in order to store objects to files or to replicate them through a Mule cluster. That imposes limitations on:
- The types of objects we can store: They need to implement the Serializable interface and provide proper constructors. Besides, it’s not enough with the class being Serializable, all its composed objects have to be as well.
- Performance: Java’s serializer is far from being the fastest in town
If you’re a frequent user of the Batch Module, then you already know that in Batch we already solved this problem using the Kryo framework, which allows serializing a wider range of objects at a faster pace than Java’s default. However, until the release of Mule 3.7.0 the Kryo capability was exclusive of the Batch module. What if you want to use it on a persistent ObjectStore? And what about a distributed VM queue? Even more: why can’t I choose to serialize using whatever framework I choose? We solved this questions in Mule 3.7.0 by:
- Creating a Serialization API, to allow any Java developer to contribute and use his own serializer.
- We created a Kryo based implementation of that Serialization API which ships with the EE distribution and can be easily configured
Serialization API
We tackled this from the ground up, starting by creating a Serialization API which decouples Mule and its extensions from the actual serialization mechanism to be used, also allowing users to configure which mechanism they want to use and even provide their own.
Mule relies on serialization each time that:
- You read/write from a persistent ObjectStore
- You read/write from a persistent VM or JMS queue
- An object is distributed through a Mule cluster
- You read/write an object from a file
Changing the serialization mechanism used for such tasks can greatly improve functionality and performance.
The serialization API is mainly defined with the following interface:
The main concept of this contract is that:
- It serializes to and from a byte[] as well as streams
- It’s thread safe
- When serializing, streaming is supported by passing an OutputStream
- When deserializing, streaming is supported by allowing an InputStream as an input source
- When deserializing, you can specify which classloader to use. By default, the current execution one is used.
- When deserializing, if the obtained object implements the DeserializationPostInitialisable interface, the serializer will be responsible for properly initializing the object before returning it.
Configuration
By default, Mule will continue to use Java serialization as it always has, no change comes out of the box. However, each application will be able to configure the ObjectSerializer it wants to use using Mule’s <configuration> tag:
NOTE: The only component which behavior will not be affected by this component is the batch module, which for its own functionality reasons needs to work using Kryo no matter what.
Obtaining the configured ObjectSerializer
There’re many ways to obtain an ObjectSerializer. Recommended approach is through dependency injection. The following shows how to get the ObjectSerializer that has been configured as the default:
Instead, if you want a specific named serializer (whether it’s the default or not) you can also do it like this:
Finally, you can always pull it from the muleContext although dependency injection is preferred:
Kryo serializer
For EE users, we’ll also provide a second implementation of ObjectSerializer which relies on the Kryo framework. Using Kryo provides:
- Better performance. Kryo is way faster than Java serialization
- Support for a wider range on Java types. Kryo is not bounded by most of the limitations that Java serialization imposes like requiring to implement the Serializable interface, having a default constructor, etc. (this does not mean it can serialize ANYTHING)
- Support for compression: You can use either Deflate or GZip compression algorithms
A new Kryo namespace has been added to configure this serializer:
The configuration above sets the default serializer to a Kryo based one. Additionally, you can also configure compression like this:
Performance when using Kryo
Using Kryo will provide performance improvements when using the following components:
- Persistent or clustered object stores
- Persistent or distributed VM queues
- JMS transport
Because no improvement is such until you measure it, we asked the mighty Luciano Gandini from the performance team to do some tests. He ran some tests to compare the transactions per second (TPS) of persistent/distributed VM queues and ObjectStores when using the standard Java serializer and different settings of Kryo. Here’re some results…
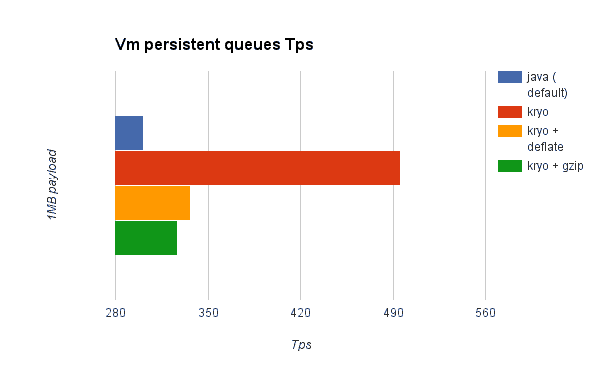
Persistent VM Queues
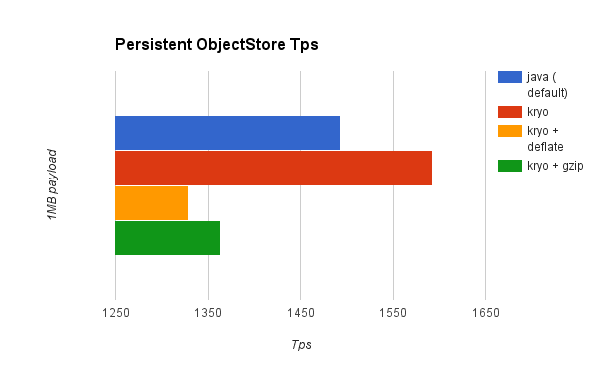
Persistent Object Stores
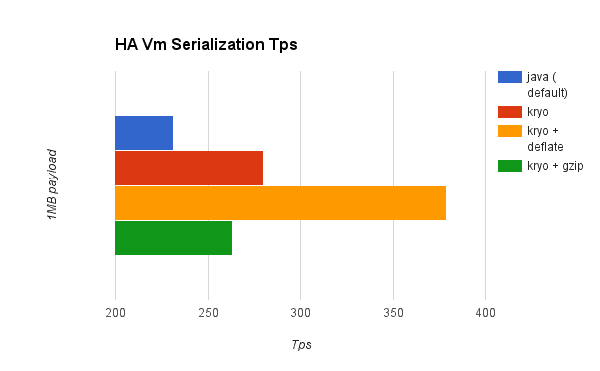
Distributed VM queues (HA)
Distributed ObjectStore (HA)

Regarding compression
As you can see on the charts above, Kryo without compression is significantly faster than the standard serializer in all cases. However, the compression mode only provides an actual improvement on the HA cases. Why is that? The environment in which these tests were performed has some really good IO speed. For the compression to be worthy, the amount of time the CPU spends compressing-decompressing has to be significantly lower than the amount of IO time saved by reducing the payload size. Because network operations are slower than disk operations (at least on our environment) and because HA clustering requires node replication (which translates to more traffic), only in the HA case the compression paid off. Is this a universal constant? ABSOLUTELY NOT! You might be running mule on machines with slower disks or higher IO demands in which compression might be worthy on any case. Also, these tests were performed with 1MB payloads, but the larger the data stream, the more worthy becomes the compression.
Performance Summary
Simply put, these were the results of the performance:
|
% improvement |
Vm persistent |
Os persistent |
Vm HA |
Os HA |
|
Kryo |
64.71% |
6.64% |
21.09% |
24.79% |
|
Kryo + Deflate |
11.84% |
-11.01% |
63.77% |
77.13% |
|
Kryo + Gzip |
8.53% |
-8.69% |
13.93% |
23.96% |
The conclusions from table above are that:
- you can get up to a 77.13% improvement in performance when using distributed ObjectStores, 63.77% when using distributed VM queues and 64.71% when using local persistent VM queues.
- Although local object stores don’t show much improvement (they are actually slower when using compression), there’s no use case in which you don’t get some level of gain when using Kryo.
As always, remember that performance results are always to be taken as a guideline rather than an absolute fact. Depending on your application, environment, payload size, etc., the actual output in each individual case might vary.
Limitations and considerations
As good as this is, this is still no silver bullet. Please account for the following considerations:
Changing serializers requires a clean slate
Serializers are not interoperable nor interchangeable (at least the ones we ship OOTB). That means that if you decide to change the serializer your application uses, you need to make sure that all messages in VM/JMS queues have been consumed and that those queues are empty by the time the new serializer kicks in. This is because Kryo serializer won’t be able to read datagrams written by the Java one and vice-versa. The same thing applies to persistent ObjectStores. If you try to read an entry generated with a different serializer, you’ll find yourself out of luck.
Serialization in a shared VM connector
Version 3.5.0 of the Mule ESB introduced the concept of domains as a way to shared resources between applications. For example, you can define a VM connector on a domain to allow inter-app communication through VM message queues. However, serializers can only be configured at an application level, they cannot be configured at a domain. So what happens if two applications (A and B) communicate with each other through a VM connector defined on a domain to which both belong, but A serializes using Java and B using Kryo? The answer is: it just works. Whenever either app tries to write to an endpoint which uses the shared connector, that particular message will not be serialized with the application’s serializer but the one the VM connector is using. So this is good right? Yes, it’s good from the point of view of the plug&play experience. But notice that you won’t be able to tell that shared VM connector to use Kryo and get a performance improvement out of it.
Why is there little to none improvement on the local persistent ObjectStore case?
Unlike the other cases, the local persistent ObjectStore doesn’t show much improvement. That’s because of high contention on the ObjectStore implementation which pretty much absorbes all the gain. We will be tackling that separately in future releases.
Why is there no chart showing the improvement in JMS?
Per the JMS API, the queues don’t work with raw payload objects. Instead, you have to provide an instance of the javax.jms.Message class. The broker client is then responsible for serializing it, not mule. Therefore, the impact of Kryo in such an scenario is minimum. The only performance gain of using Kryo with JMS is that Mule serializes the MuleSession and puts it as a header in Base64 format. Serializing the MuleSession with Kryo can give you up to 10% performance speed, but we don’t consider it as an example use case since the big part of the serialization is up to the JMS broker instead of mule.
Problematic types
Although Kryo is capable is serializing objects that don’t implement the Serializable interface, setting Kryo as the default serializer doesn’t mean that components such as the VM transport, ObjectSerializer or Cluster will be able to handle objects which don’t implement such interface. That’s because even though Kryo can deal with those objects, the Java APIs behind those components still expect instances of Serializable in their method signatures. Note however, that whereas standard serialization will fail with an object that implements the Serializable interface but contains another one which doesn’t, Kryo is likely (but not guaranteed) to succeed. A typical case would be a Pojo containing an org.apache.xerces.jaxp.datatype.XMLGregorianCalendarImpl like the NetSuite or MS Dynamic Cloud connectors do
Wrapping up
When we set to do this improvement we knew this would have a big impact, but to be honest, our expectations were greatly exceeded. I personally wasn’t expecting an improvement over 30% on the best case. To see a peak of 77% improvement on the best case and 64% on the most usual one, has just made me happy. I hope it makes you happy as well.
As always, please don’t hold off on feedback on how to keep improving this.
Cheers!



