
Murphy’s Law doesn’t mean that something bad will happen. What it means is whatever can happen will happen. How we moved beyond theoretical reliability and embedded resilience testing into our engineering workflows. Embedding chaos engineering directly into our engineering workflows allowed us to move beyond purely theoretical reliability.
What is chaos engineering?
Chaos engineering is the disciplined practice of deliberately introducing controlled failures into applications to verify that they remain resilient, fault-tolerant, and reliable under real-world failure conditions.
In an enterprise using MuleSoft, integrations connect critical systems (ERP, CRM, databases, SaaS apps). If one dependency fails, the entire business flow can be impacted. Chaos engineering ensures the integration layer can handle such failures gracefully and are resilient.
What do we mean by a single point of failure?
These are critical vulnerabilities in a system that can be taken down by a single fault. This could manifest as services that are unprovisioned, lack replication or redundancy, or suffer from distribution imbalance. By deliberately introducing controlled “chaos,” the resilience engineering team is focused on rooting out these weaknesses, ensuring our services are robust, highly available, and are resilient in an event of failure.
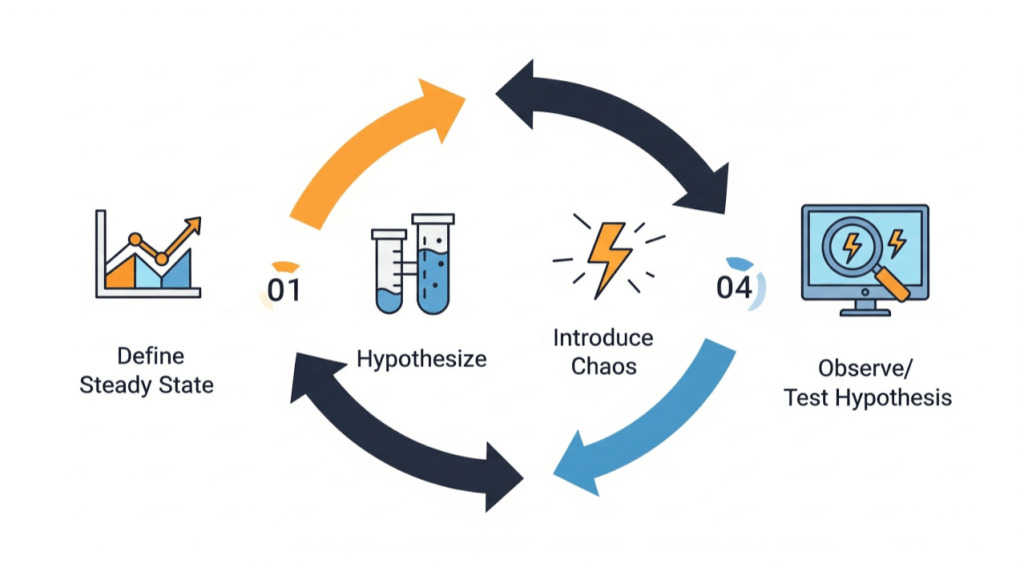
To introduce controlled chaos, we follow this four step methodology:
- Define steady state: This is your baseline
- Hypothesize steady state continuity: Control/experiment groups
- Introduce chaos: Simulate failure
- Observe: Test hypothesis
When do we test for resilience?
Resilience can be tested in any part of DevOps lifecycle. Our experience suggests that chaos engineering experiments are best conducted when a measurable impact is observed under production-like load, typically during performance engineering exercises in the early development cycles.
Examples of chaos
The following are some examples of chaos in distributed/containerized deployments, also known as faults, attacks, or experiments. These include:
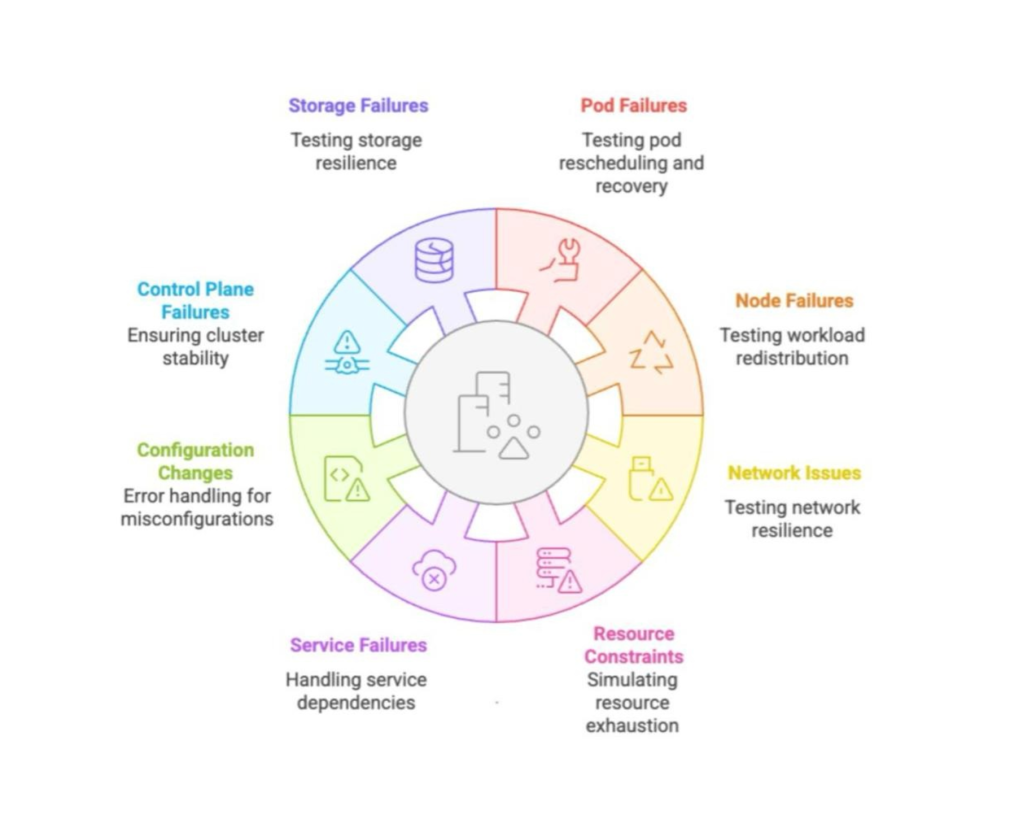
Pod failures (Application-level)
- Pod kill/container kill: Terminate specific pods or containers to observe the system’s behavior and ability to reschedule workloads
- Resource starvation: Simulate high resource usage (CPU, memory) for specific pods to test autoscaling and resource management
- Application crash: Cause application processes to crash to evaluate recovery mechanisms
- Network latency or errors (Service-to-Service): Introduce artificial delays, packet loss, or dropped connections between microservices to test fault tolerance
Node failures
- Node drain: Simulate the removal of a node from the cluster to test pod rescheduling and workload balancing
- Node shutdown or restart: Mimic a node crash or reboot to evaluate system recovery and redundancy
- Resource exhaustion: Consume CPU, memory, or disk on a node to test how it handles resource contention and impacts cluster workloads
Network issues
- Latency injection: Introduce delays in network communication between services, pods, or external systems
- Packet loss or corruption: Drop or corrupt network packets to evaluate the robustness of communication protocols
- Partitioning: Simulate network partitions (e.g. splitting a cluster into isolated segments) to test how the system maintains consistency and availability
- DNS failures: Simulate DNS resolution failures or delays to test how services handle name resolution issues
Storage failures
- Disk fill: Simulate full disk usage on a node or pod to evaluate how the system reacts to storage exhaustion
- I/O latency: Introduce latency in disk operations to test the application’s tolerance to slow storage
- Data corruption: Corrupt files or data to evaluate the system’s ability to detect and recover
- Volume detachment: Simulate detachment of persistent storage volumes to test how workloads handle storage unavailability
Control plane failures (e.g. Kubernetes)
- API server unavailability: Simulate API server downtime to observe how the cluster operates without the control plane
- Scheduler failures: Test how the system handles scenarios where the Kubernetes scheduler is unavailable or under heavy load
- ETCD failures: Introduce faults in the ETCD datastore to test the system’s tolerance to data unavailability or corruption
Configuration failures
- Misconfigured secrets: Provide incorrect secrets or configurations to test how the system handles authentication and authorization failures
- Certificate expiry or revocation: Simulate expired or revoked SSL/TLS certificates to evaluate the system’s response
- Unauthorized access attempts: Mimic unauthorized access or privilege escalation attempts to test the security measures in place
Service failures
- Failed deployments: Introduce faulty configurations or code to test rollback and recovery mechanisms
- Rolling update failures: Interrupt rolling updates to evaluate the system’s ability to maintain consistency and recover
- Image pull errors: Simulate errors when pulling container images (e.g. using non-existent or unavailable images)
Resource constraints
- Load spikes: Simulate sudden spikes in traffic to test autoscaling and load balancing mechanisms
- Invalid requests: Send malformed or unauthorized requests to evaluate the system’s response and error handling
- Request timeouts: Simulate timeouts in request processing to test the behavior of retries and circuit breakers
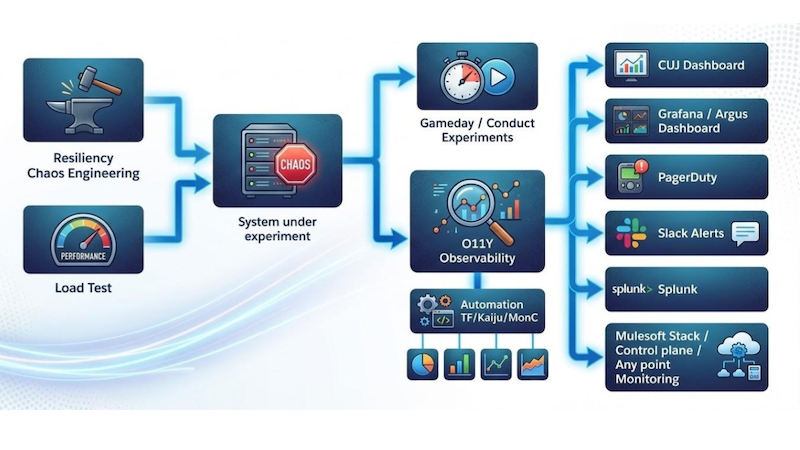
How do we plan to create chaos and observe?
- Define the blast radius: Start by clearly identifying your System Under Test (SUT) and the specific failure mode you intend to inject. Precision here ensures you are testing a single variable at a time
- Simulate realistic traffic: A test in a vacuum is rarely telling. Ensure your environment is subjected to production-like load; simulating real-world traffic is the only way to accurately observe how the system handles stress under pressure
- Monitor via internal observability: Use your organization’s standard observability stack to monitor the experiment in real-time. This validates whether your telemetry provides the necessary visibility when things actually go wrong
- Validate the alerting pipeline: Beyond just “seeing” the failure, verify that the expected alert notifications are triggered. A resilient system is one that successfully tells you when it’s struggling
Availability zone failure example (chaos experiment)
Before injecting failure, we must establish our steady-state hypothesis. In this scenario, that means a healthy Kubernetes cluster where workloads are balanced across multiple replicas and intelligently partitioned between AZ1 and AZ2 for maximum redundancy.
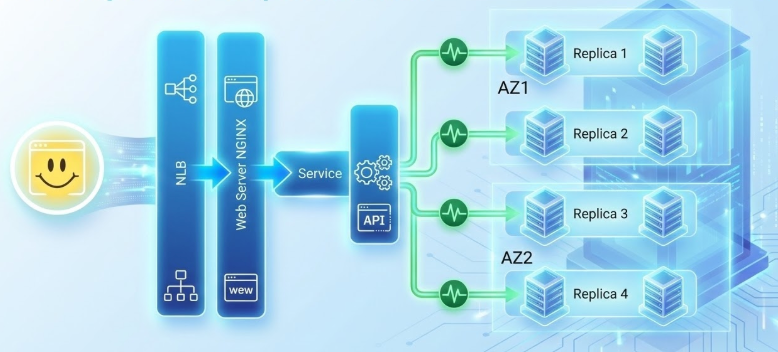
When we triggered the AZ outage, we observed a service experiencing HTTP 503 errors. The experiment revealed a gap in our automated failover logic – traffic was still being routed into the impacted zone.
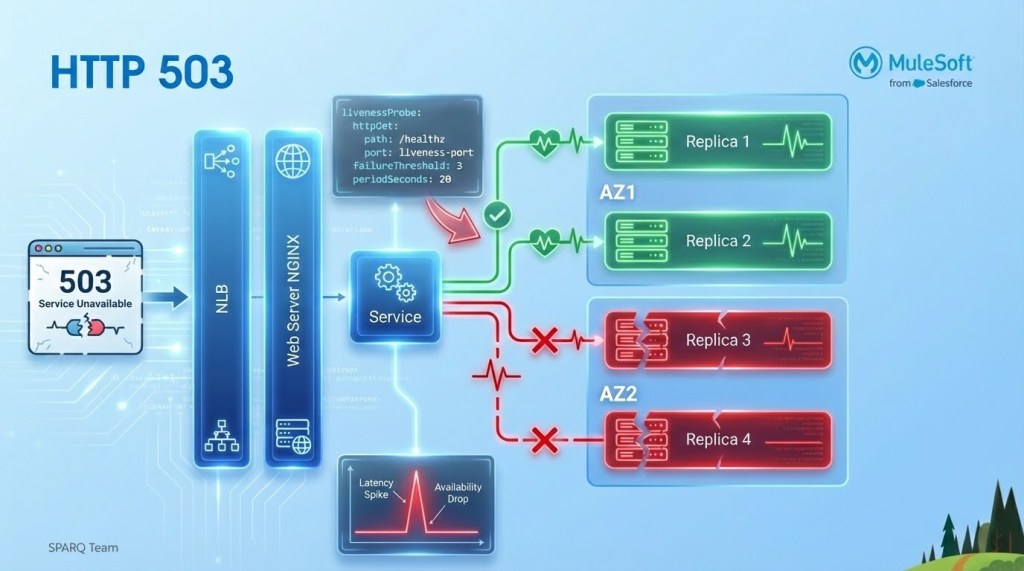
By fine-tuning our LivenessProbe thresholds, we significantly reduced the time to detection. This aggressive health check configuration ensures that during an AZ failure, traffic is immediately diverted away from ‘zombie’ replicas and routed only to healthy nodes, effectively minimizing the impact on services.
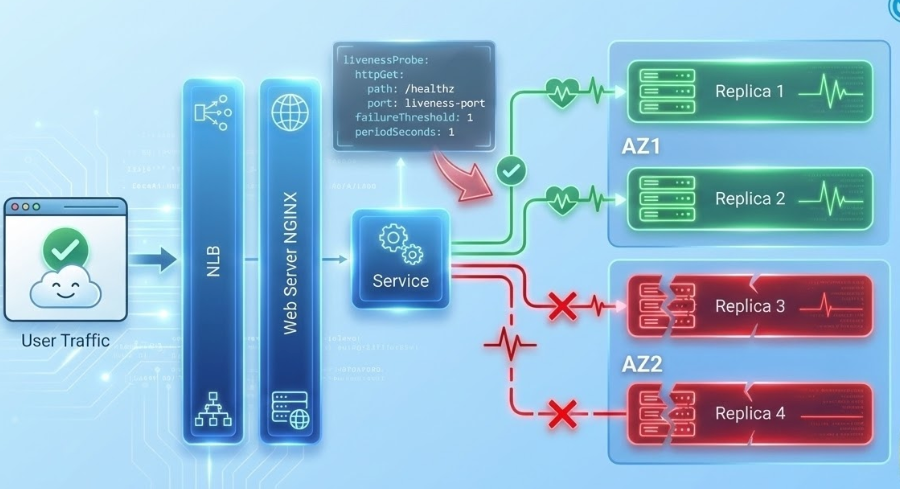
Here’s another chaos experiment example for k8s stateful services shared in CNCF 2022 Spinnaker Summit: Lightning Talk: A Culture of Resiliency Through Chaos, Scott Glaser and Prakash Ramesh, Salesforce.
Chaos testing: Engineering practice for testing integration resilience
For organizations relying on MuleSoft to connect critical systems and data, resilience is paramount. Chaos engineering offers a safe, structured way to test how integration apps respond to real-world failures like API outages or network latency.
By intentionally introducing controlled failures, teams gain crucial visibility into retry policies, error handling, and circuit breakers before a real incident. This results in faster recovery, clearer operational runbooks, and unshakable confidence in your business-critical integrations.
Beyond the technical benefits, this practice strengthens collaboration and shifts the focus from reactive incident response to proactive learning and continuous design improvement. Ultimately, chaos experiments transform uncertainty into insight, ensuring your MuleSoft-powered ecosystem doesn’t just work when everything is healthy, but continues to perform when it matters most.
This practice becomes even more vital in an agentic enterprise where autonomous agents make real-time decisions. The focus moves from system reliability (is the system up?) to trustworthiness (is the agent acting correctly and safely?). Instead of asking: “What if the service goes down?,” we now ask: “What if the agent makes a bad decision or acts in an incomplete context?”



