
Looking at the global trends in the IT industry and how the sector has evolved in the last few decades, mergers and acquisitions (M&A) are trending as the most widely used strategies for corporate makeovers.
One common technical challenge is the integration of multiple source platforms that hold process-centric data like accounts, contacts, for various business processes within the company.
With high demand for the fastest-growing segment of SaaS platforms that majorly prevents direct data store access, there is an additional challenge of dynamic data retrieval and real-time data access. Within a company itself, IT teams either need to support the transition period from one platform to another, or upgrade to new technology stacks as a part of IT maturity/growth, which can create this scenario.
As the saying goes, every problem has a solution – it just takes a right perspective to find one.
Data integrity, atomicity and consistency are of the utmost importance, as Data is what drives everything to begin with.
The solutions we suggest for all of the use-cases is the Pub-Sub design pattern using MuleSoft, which uses off-the-shelf connectors to achieve this in the simplest of fashion. As a result, you’ll get a seamless, dynamic, real-time data sync solution.
Use cases
Use-case: Company A uses Salesforce as its central platform, and Company B has its own home-grown database-centric system as their central platforms for their source of data. Say Company A acquires Company B; now there will be two instances of data: Salesforce and the database. But Company A must function as one unit and can’t have two systems coexist for the same data. Not only is this inefficient for the functioning of the company, but managing segregated business-centric data is IT’s worst nightmare.
A straightforward solution is to copy all the data from one system to the other, decommission one of the systems, and continue with the other. But as we all know in an actively functioning business model, that’s easier said than done. There also might be parts of the business processes which are more efficient in one system than the other, and simply unplugging a system would not be the right choice. Another idea would be to copy-paste all the data from one system to the other every so often.
So, what now? Here’s our functional requirement: sync the common definitive data required between the two systems dynamically, in real-time, reliably, continuously, and as an atomic operation. But how? We can’t access the data stores directly, especially for SaaS platforms.
The solution is the event sourcing/publisher-subscriber design pattern
Your first thought might be: this is a lot of in-house work starting from exposing a publisher for both the systems, managing multiple queues, coding listeners for all the systems, coding multiple syncs, managing the various duplicate events scenario, and more…but that’s where the magic of MuleSoft can help.
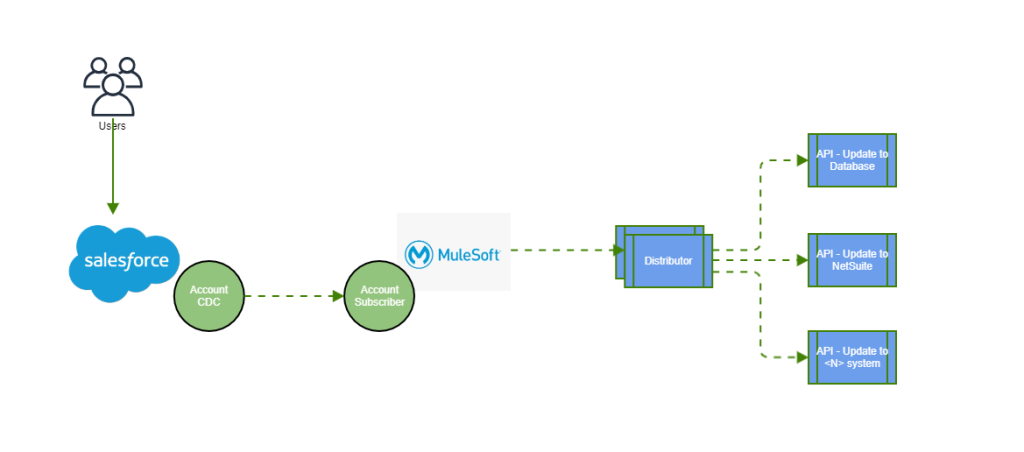
From Salesforce to database
Solution diagram:
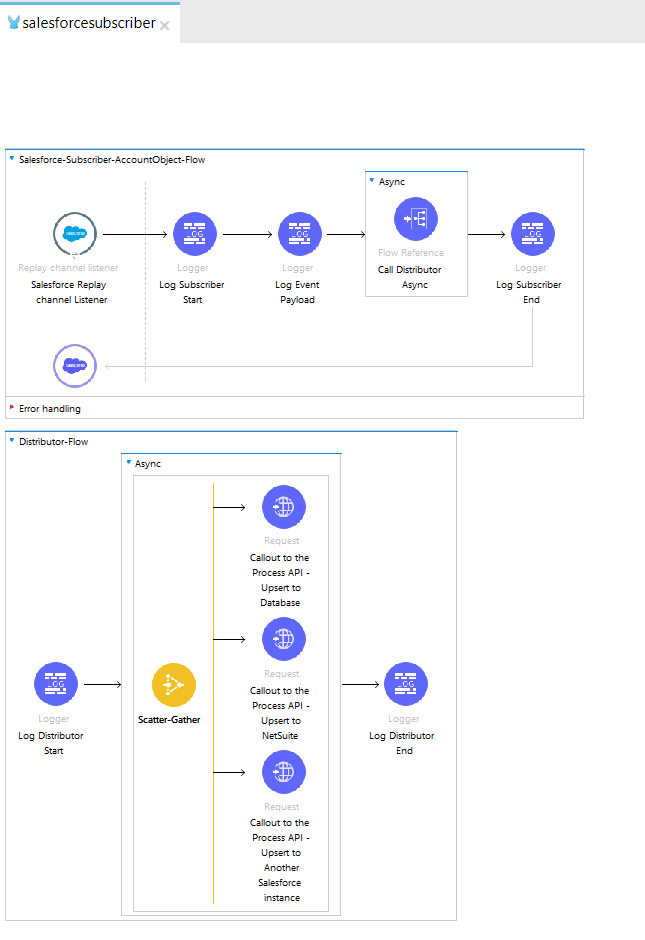
MuleSoft code flow:
MuleSoft code xml:
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns:salesforce="http://www.mulesoft.org/schema/mule/salesforce"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/salesforce http://www.mulesoft.org/schema/mule/salesforce/current/mule-salesforce.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd">
<salesforce:sfdc-config name="Salesforce_Config" doc:name="Salesforce Config" doc:id="725d3d4f-e4e8-4fb3-b9a7-4c2df3944613" >
<salesforce:basic-connection />
</salesforce:sfdc-config>
<http:request-config name="HTTP_Request_configuration" doc:name="HTTP Request configuration" doc:id="8d3e298c-3b37-4cb9-8a56-b5bd999c8625" />
<flow name="Salesforce-Subscriber-AccountObject-Flow" doc:id="c1e7285d-d064-4cd1-9270-1772976f2c68" >
<salesforce:replay-channel-listener doc:name="Salesforce Replay channel Listener" doc:id="2a1bf200-cea1-4fe1-b795-ce74582df1c9" config-ref="Salesforce_Config" streamingChannel="Account" replayOption="ONLY_NEW"/>
<logger level="INFO" doc:name="Log Subscriber Start" doc:id="54f78357-639b-43c1-a713-3a6317f6db10" message="Log Subscriber Start"/>
<logger level="INFO" doc:name="Log Event Payload" doc:id="e1c06b36-495e-48f7-8fcb-f0ae0c6bd743" message="#[payload]"/>
<async doc:name="Async" doc:id="d89b856e-e4af-417a-9cd9-69d32a0879eb" >
<flow-ref doc:name="Call Distributor Async" doc:id="7c01aeff-ca72-4ced-ba40-9af85af35eda" name="Distributor-Flow"/>
</async>
<logger level="INFO" doc:name="Log Subscriber End" doc:id="e3a60c3c-f205-49a2-b1a2-cab258d234dd" message="Log Subscriber Start"/>
</flow>
<sub-flow name="Distributor-Flow" doc:id="0789cd5a-46c4-4b61-bd02-ffd983881326" >
<logger level="INFO" doc:name="Log Distributor Start" doc:id="f574777a-4cf6-418d-99d1-c1068f99beae" message="Log Distributor Start"/>
<async doc:name="Async" doc:id="67a022d1-a1c7-4327-ae2e-53941f1046ae" >
<scatter-gather doc:name="Scatter-Gather" doc:id="4e6d6183-ce66-4a0c-9045-664bd8cdb814">
<route>
<http:request method="POST" doc:name="Callout to the Process API - Upsert to Database" doc:id="3bcff856-7a04-4d56-984c-8f3504ccaa86" config-ref="HTTP_Request_configuration" path="/db/account"/>
</route>
<route>
<http:request method="POST" doc:name="Callout to the Process API - Upsert to NetSuite" doc:id="d7a588e2-728f-40e1-9754-131f71413330" path="/ns/account" config-ref="HTTP_Request_configuration"/>
</route>
<route>
<http:request method="POST" doc:name="Callout to the Process API - Upsert to Another Salesforce instance" doc:id="eadfd889-227e-4841-b36c-daa190b27278" path="/sftest/account" config-ref="HTTP_Request_configuration"/>
</route>
</scatter-gather>
</async>
<logger level="INFO" doc:name="Log Distributor End" doc:id="863c59ba-b66f-4ac0-969c-4bea21da1473" message="Log Distributor Start"/>
</sub-flow>
</mule>
Steps:
- Expose the Publisher in Salesforce (CDC for Account)
- MuleSoft Anypoint Platform code
- The very first thing you need to do is with the good old RAML approach, code your API, which takes a list of Ids, gets required data from the source system (here Salesforce), and transforms the data and upserts it to the Database.
- The Subscriber:
- Subscriber (Process Events with Salesforce Connector 10.14)
- Read the event payload
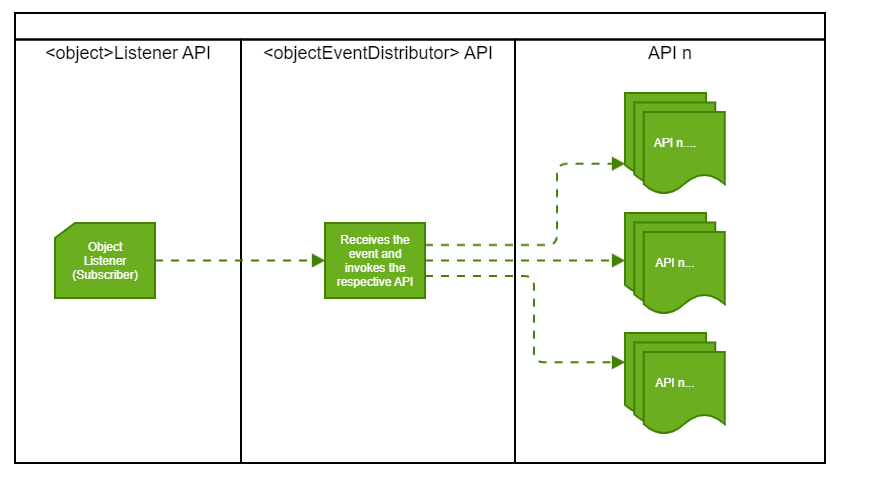
- ASync passes it to a distributor (it’s a terminology I am using to distribute the payload to any API which needs to DO something with this payload).
- The distributor invokes the API you coded in
Why a distributor? Because right now, the use case might be just syncing the data to a database, but say you have another use case in the future that needs this event and payload for something else (e.g. sync it to NetSuite), all you need to do is develop your new API and just plug it into your distributor.
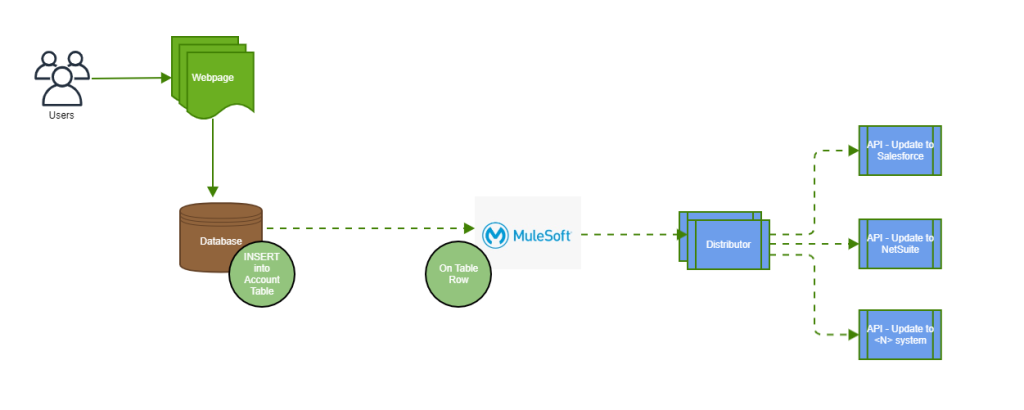
This took care of syncing the data from Salesforce to the database for our use case. What about the other way? Just use the database on the table row connector and sync the data from DB to Salesforce.
From database to Salesforce
Solution diagram:
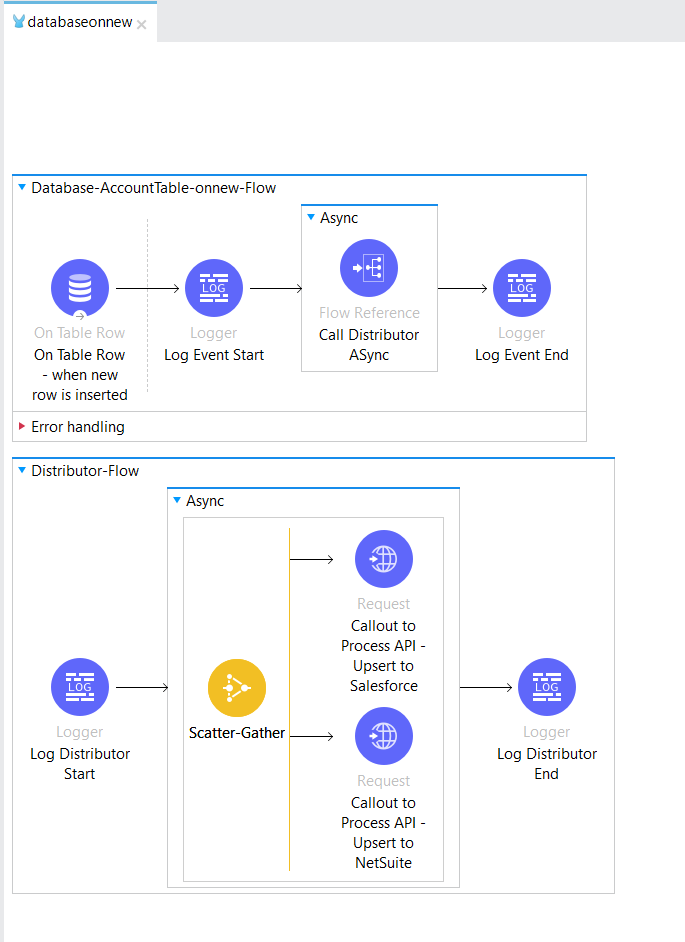
MuleSoft code flow:
MuleSoft code xml:
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns:db="http://www.mulesoft.org/schema/mule/db"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/db http://www.mulesoft.org/schema/mule/db/current/mule-db.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd">
<db:config name="Database_Config" doc:name="Database Config" doc:id="f7bafb67-0942-4f74-b482-e22e6a21c797" >
<db:data-source-connection />
</db:config>
<http:request-config name="HTTP_Request_configuration" doc:name="HTTP Request configuration" doc:id="1a5e3253-f43a-40bb-8b19-732dc337cca8" />
<flow name="Database-AccountTable-onnew-Flow" doc:id="3109b017-05a8-41d0-a361-3816c61f5a5a" >
<db:listener doc:name="On Table Row - when new row is inserted" doc:id="76ef1f6d-656f-4900-a15d-e1301b1c5955" config-ref="Database_Config" table="Account">
<scheduling-strategy >
<fixed-frequency />
</scheduling-strategy>
</db:listener>
<logger level="INFO" doc:name="Log Event Start" doc:id="7bbe55e9-d7ef-49c1-817b-80d64637eeb2" message="Log Event Start"/>
<async doc:name="Async" doc:id="c9d841e3-3bcb-4470-92be-8be1bb49706a" >
<flow-ref doc:name="Call Distributor ASync" doc:id="8b3cc62f-96bd-4037-95ca-5e46ed0a89cd" name="Distributor-Flow"/>
</async>
<logger level="INFO" doc:name="Log Event End" doc:id="3758dab9-75ca-4595-9f4d-cab72430d670" message="Log Event End"/>
</flow>
<sub-flow name="Distributor-Flow" doc:id="feb80eae-05c0-4ec4-b373-355198f36b5d" >
<logger level="INFO" doc:name="Log Distributor Start" doc:id="296f8997-3126-4bac-a1af-7ed717047d49" message="Log Distributor Start"/>
<async doc:name="Async" doc:id="d8961ca5-a275-4b0c-865d-a073f861fc07" >
<scatter-gather doc:name="Scatter-Gather" doc:id="5e29b37f-bb55-4dec-a6e2-c7184f801e42">
<route >
<http:request method="POST" doc:name="Callout to Process API - Upsert to Salesforce" doc:id="aa63583c-5c7b-4dbc-b3e5-d083a26b6c1a" config-ref="HTTP_Request_configuration" path="/sf/account"/>
</route>
<route >
<http:request method="POST" doc:name="Callout to Process API - Upsert to NetSuite" doc:id="56da5a06-1de8-4c85-87c1-5ac9c7bbbebf" config-ref="HTTP_Request_configuration" path="/ns/account"/>
</route>
</scatter-gather>
</async>
<logger level="INFO" doc:name="Log Distributor End" doc:id="c699c491-2e2f-47e8-a482-125c35ed79ec" message="Log Distributor End"/>
</sub-flow>
</mule>
This design can be easily extended to any source and destination systems. The only change is instead of using the Salesforce Connector subscriber, you might have to use the MuleSoft VM Connector Pub-Sub off-the-shelf MuleSoft Connector. Either way, it’s all readily available for your use.
Essentially, this is what we did for both systems:
The benefits of the above
To conclude, we just avoided a huge amount of coding! That in itself is the biggest benefit. Why reinvent the wheel? We maintained the integrity of the data in real time. Note the Replay ID, the size of the queue, the retention period, database event, and so many other features are available off the bat as configurable items. The design is highly scalable, manageable, and extendable.
The only upfront maintenance it would need is upgrading the connector version when available. The only changes you will need to make is punching in your connection details for the source and destination systems.
Something to keep in mind when you work with pub-sub is looping deadlocks. If your source and destination systems are the same and you are inserting into the same object that you are listening to, you will end up in a continuous loop, or a deadlock. One simple way to avoid this is in your subscriber/listener, you can check who the owner of the change is that generated the – or you can use the mutex approach.



