
As application deployment evolves, the IT industry is increasingly gravitating toward containerized deployment models. Containers offer a lightweight, infrastructure-agnostic solution, making it easier to manage applications and services. This shift has heightened the need for efficient scaling solutions.
Horizontal autoscaling allows applications to scale out by adding more instances of the application, as opposed to vertical scaling, which involves adding more compute resources to a single instance.
Understanding horizontal pod autoscaling (HPA)
Horizontal pod autoscaling (HPA) is a form of Kubernetes-based autoscaling that automatically adjusts the number of pod replicas in a deployment based on current workload demands.
CloudHub 2.0 autoscaling is based on HPA. It works through monitoring specific metrics, such as CPU usage, and adjusting the number of pod replicas accordingly. For example, if the CPU usage of your application exceeds a certain threshold for a sustained period, the number of pods will automatically be scaled up. Conversely, if the CPU usage drops below this threshold for a set duration, the number of pods will be scaled down.
Key parameters of HPA include:
- CPU usage monitoring: The primary metric for triggering scaling actions.
- Thresholds and cooldown periods: To prevent constant scaling actions, thresholds and cool-down periods are set.
- Max/min replicas: Limits to ensure that the number of replicas stays within a specified range.
Why is horizontal autoscaling beneficial?
HPA offers a number of advantages when deploying integrations:
- Eliminates guesswork: You don’t need to guess the required capacity upfront.
- Handles unpredictable spikes: Easily manage unpredictable utilization spikes.
- No oversizing: No need to allocate one large instance; instead, you can deploy multiple smaller instances.
- Flexibility at time of deployment: You don’t need to determine capacity requirements at the time of deployment.
Which applications are good candidates for horizontal autoscaling?
Not all applications are ideal for HPA. Good candidates typically include stateless applications, which can run multiple instances simultaneously without issues. Characteristics of such applications include:
- CPU utilization-based: Applications where CPU usage is a primary performance indicator.
- Parallelism: Able to run on multiple nodes concurrently, often seen in HTTP-based or API call-based services
- Real-time processing: Applications requiring high throughput and low latency
- Compute-heavy tasks: Examples include data transformation tasks like DataWeave transformations
On the other hand, applications with slow backend data sources or high latency generally don’t see performance gains with HPA.
What does HPA look like in action?
To illustrate how HPA enables seamless scaling, let’s consider a case study. The graph below shows application traffic increasing over time on the X-axis and CPU utilization on the Y-axis, highlighting the scale-ups triggered by HPA.
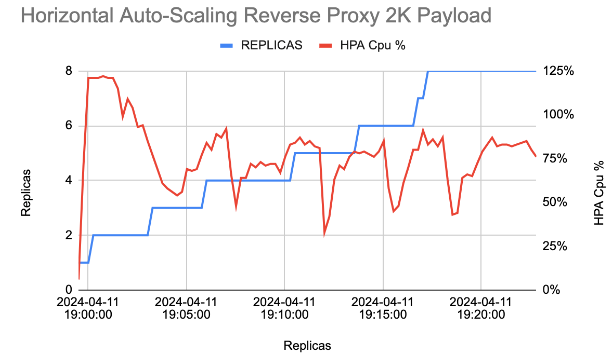
As traffic to the application continues to increase over time, overall CPU utilization stays within a consistent range, without requiring increased resources to just one instance, or pre-deployment of infrastructure.
Modern app deployment requires the right tool
Horizontal pod autoscaling is a crucial tool for modern application deployment, offering dynamic scaling, and the ability to handle unpredictable spikes in demand. By leveraging horizontal autoscaling in CloudHub 2.0, you can ensure your applications run smoothly and efficiently, adapting to changing workloads with ease.
Horizontal autoscaling is only available for customers on the new usage-based pricing model in CloudHub 2.0. Want to keep learning? Read the CloudHub 2.0 documentation pages for more information.



