
An application network enables organizations to connect applications, data, and devices through APIs which expose their assets and data to other systems on the network. As an application network grows the more reusability it will provide. Reusing APIs goes hand in hand with a high-degree of dependency between APIs. Therefore, a high degree of dependency between your APIs means that failures during the invocation of an API will affect other API implementations and the services they offer to the application network. As long as everything follows the happy path nothing will happen. But as soon as something goes wrong during an API invocation — and at some point something will go wrong — failures will propagate transitively through your application network and cause downstream failures of other dependent APIs. For this reason, making your API invocations fault-tolerant is critical for a successful application network.
Whether you’re building up your first APIs or already have a huge application network, learn how you can make your application network more fault-tolerant.
How to achieve fault-tolerance within an application network
An API client is an application component that accesses a service by invoking an API of that service. An example of this could be calling an experience API from a web app. But with API-led connectivity, this could be calling a process API from within an experience API, or calling a system API from a process API.
A fault-tolerant API invocation is a call from an API client to an API implementation where a failure of the invocation does not lead to a failure of the client. Because the client itself is typically an API implementation, the API provided by that API implementation does not cause its clients to experience failures.
The number one priority of making API invocations fault-tolerant is to break transitive failure propagation.

Steps for implementing fault-tolerant API invocations:
1. Timeout
The first step to apply fault-tolerance to your application network is to set up a timeout for your requests. This will reduce the risk of breaking the SLA of the API client even if the API invocation ultimately succeeds. It will also reduce the higher-than-usual probability of it failing anyways without timeout. For these two reasons, timeouts for API invocations should be set carefully — as low as possible — and in accordance with the SLA of the API client.
API clients that have been implemented as Mule apps and are executing on Mule runtime engine offer different options for configuring timeouts. You can configure it at the level of your HTTP request, for the entire transaction, or as part of control constructs (e.g. Scatter-Gather).
Once an API invocation has failed, it might succeed when trying to call that API again. But this approach will only be successful if the failure was transient rather than permanent. Usually it’s difficult for an API client to detect without doubt that a failure, which occurred during an API call, was of a transient nature. This is why the default approach is often to retry all failed API calls.
With REST APIs, a response code within the range of 4xx signifies a client error which is mostly permanent, and therefore should not be retried. This does not apply to HTTP response codes “408 Request Timeout,” “423 Locked,” and “429 Too Many Requests,” which should be treated as transient failures. HTTP response codes in the range of 5xx should always be expected to signify a failure of transient nature. Additionally, only idempotent HTTP methods (GET, HEAD, OPTIONS, PUT, and DELETE) may be retried without causing unwanted duplicate processing.
Within Mule applications you can use the HTTP Request Connector and Until Successful Scope for configuring retries of API calls. The HTTP Request Connector provides the capability for interpreting certain HTTP response status codes as failures.

However, as a timed-out API invocation is equivalent to a failed one, setting a timeout with a retry strategy is only the first step to achieve fault-tolerance.
2. Fallback invocation
In case an API invocation fails — even after a certain number of retries — it might be adequate to invoke a different API as a fallback. A fallback API, by definition, will never be ideal for the purpose of the API client, otherwise it would be the primary API.
Here are some examples for fallback APIs:
- An old, deprecated version of the same API.
- An alternative endpoint of the same API and version (e.g. API in another CloudHub region).
- An API doing more than required, and therefore not as performant as the primary API.
- An API doing less than required and therefore forcing the API Client to offer a degraded service — which is still better than no service at all.
API clients implemented as Mule applications offer the ‘Until Successful Scope and Exception’ strategies at their disposal, which together allow configuring fallback actions such as a fallback API invocation.
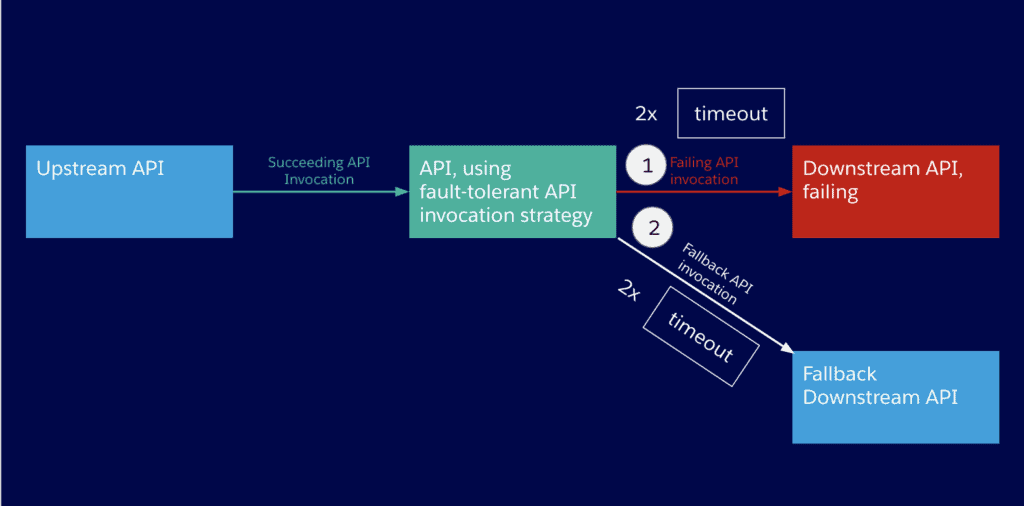
In case the primary API and the fallback API both timeout — let’s add another strategy to make our application network more fault-tolerant.
3. Client-side cache
This strategy will use a result from a previous API invocation. The API client needs to implement client-side caching, where the results of API invocations are preserved indexed by the input. The result of an API invocation can then be found in the cache by the input to the API invocation that has just failed. Only results from safe HTTP methods like GET, HEAD, or OPTIONS should be cached.
However, caching increases the memory footprint of the API client and adds processing overhead for populating the cache after every successful API invocation.
API clients implemented as Mule applications have the Cache Scope and Object Store Connector available, which both support client-side caching.
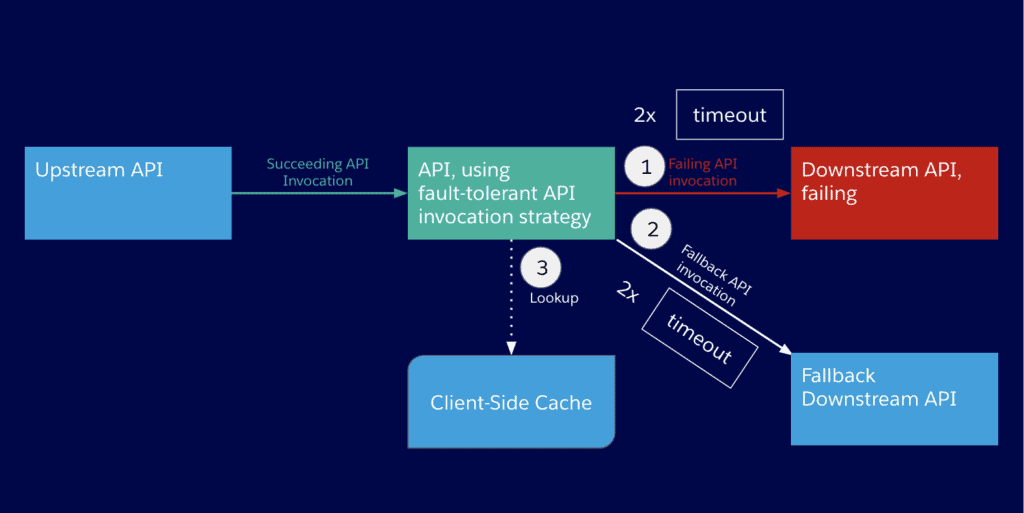
In case you don’t have client-side caching implemented or there simply is no cached result, let’s take a look at our final fault-tolerance strategy.
4. Fallback result
The ultima ratio to avoid failures propagating transitively through your application network is to provide your API client with a static result. This strategy works best for APIs that return results related to reference data like countries, states, currencies, or products. It might not be the ideal result for your API client, but it may be the better option than not returning a result. The principle is to prefer a degraded service to no service at all.
API clients implemented as Mule applications have many options available for storing and loading static results. One of those options is to use properties which can be updated via Anypoint Runtime Manager using either the Web UI or platform APIs, in case the Mule application is deployed to CloudHub.

Making your application network fault-tolerant gets more and more important the bigger your application network grows. If you want to learn more about how to successfully build application networks check out the Anypoint Platform Architecture: Application Networks course.



