
Veera Gopalakrishnan, a System Integration Engineer, and Swarnim Ranjitkar, a Sr. Software Engineer, at University of California, San Francisco (UCSF) both have more than five years of MuleSoft experience. Veera presented a UCSF and MuleSoft use case during our Developer Meetup at MuleSoft CONNECT Digital Americas. Here, Veera and Swarnim provide an in-depth explanation of how UCSF uses dynamic DataWeave scripts and the Salesforce platform for secure access to Electronic Health Record (EHR) data through APIs.
The history of EHR technology
EHR technology uses a number of different standards and frameworks for developers that have evolved over the years. The HL7 organization created the HL7 v2.x messaging standard for electronic data exchange in the clinical domain. Unfortunately for new developers, the structure is difficult to understand unless they’ve worked in the healthcare industry for many years because the data is hard to decipher. As Representational State Transfer (REST) became popular and widely used across many industries, the HL7 organization created the Fast Healthcare Interoperability Resources (FHIR) standard.
FHIR is based on REST resource models, meaning the clinical information is represented as different resources such as “patient resource,” “lab results resource,” or “allergy resource.” Using this FHIR data exchange model, HL7 organizations adopted a standard framework called the Substitutable Medical Applications and Reusable Technologies (SMART) on FHIR to easily integrate third-party applications within the EHR system. This aims to help clinicians make informed decisions at the point of care.
Challenges posed by EHR vendor APIs
At UCSF, we experienced quite a few limitations and challenges with this new EHR framework, hindering our ability to offer the best patient experience. Specifically, when EHR vendors started developing APIs, it did not offer the desired level of security for exposing our data through APIs. At UCSF, we use our EHR to store patient data from affiliated hospitals and we don’t want to expose these patients’ data through the EHR APIs, rather, we only want to expose UCSF patient data. This meant we needed to add additional security on top of what the EHR provided.
To do so, we had to create processes and logic to filter the non-UCSF patients through these APIs. This posed a challenge, however, as in addition to FHIR, the vendor also had an older set of APIs that were developed over long periods of time and by many different developers. Thus, they lacked the standardization and the security UCSF required. This caused us to spend additional time in securing and publishing the EHR vendor APIs through the proxy.
UCSF’s initial proxy approach
Using MuleSoft, we developed proxies for the EHR technology. We built three different proxies to expose the EHR APIs:
- FHIR APIs proxy
- Non-FHIR APIs proxy
- Custom APIs proxy (for the APIs developed at UCSF to expose the EHR data that isn’t available in the vendor APIs)
Our custom APIs were developed on Anypoint Platform, allowing us to add all the needed security for our organization in the proxy. The reason we built all three of these proxies was to encapsulate additional security, include data validation and redaction, and have API analytics for UCSF.
Without going into too much detail, we wanted to share with you three different apps; NEWT (SMART on FHIR App), Luma (patient self-scheduling app), and Eureka (research app using system-to-system integration) that exemplify the applications and systems we need to integrate with the EHR system using the EHR API proxies. However, this initial approach did have limitations.
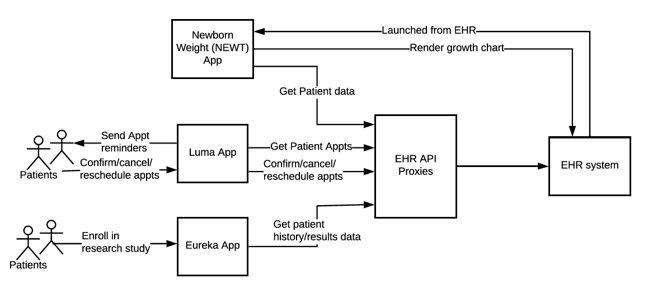
Challenges with initial proxy approach
At first, we installed and incorporated all of the validation and redaction rules written in the Mule flow to our APIs. However, when we wanted to add more apps, there were different requirements for the data validation and redaction that varied by client. Furthermore, most of the APIs were limited in scope and didn’t have data filtering or validation which UCSF requires. We had to manually incorporate the logic within the proxy flow. However, since we included it within the flow, adding any new requirements or making any changes to the flow itself, was extremely challenging. As a result, we experienced these limitations:
- Limited ability to make changes because it took so long.
- All of the changes in our first API proxy were manual and required lots of coding changes per requirements of each API client.
- There was high demand and many pain points which led to unhappy and frustrated API clients.
- It was extremely difficult to maintain.
We started to think “Why can’t we extract all of those logic data validation rules and data extraction rules into separate tables or files that can help us make changes easily?” Ultimately, we created dynamic proxies using DataWeave and Salesforce Custom Metadata tables to solve these pressing integration issues.
Externalizing DataWeave scripts and Salesforce Custom Metadata tables
As part of this effort, we created a dynamic proxy. The flowchart below shows how incoming requests are checked, the validation process using externalized DataWeave scripts or MEL expressions, how calls to the EHR API are made, and lastly, the data redaction process.

We begin by extracting the DataWeave scripts and storing them in a Salesforce Custom Metadata table. Data validation is included to help us define different requirements for each API client and we can redact any sensitive data for specific clients. Now, we can make changes on the fly and it’s easier to maintain. Additionally, the system reads these configurations and loads them into memories so we don’t have to go to Salesforce every time we process API requests, thereby creating a dynamic look-up system. Overall, our performance improves, we can make changes in real-time, and we can enable/disable scripts when needed. The image below is an example of DataWeave scripts and validation checks:

Here is a snippet of sample code used to perform validation checks:

Example Response Redaction Script:

Based on whether the API response need to be redacted for a specific API client, as per the configuration stored in the external table, we can apply a data reduction rule by using code such as below:

Furthermore, you can see how we stored the external DataWeave scripts in Salesforce Custom Metadata tables: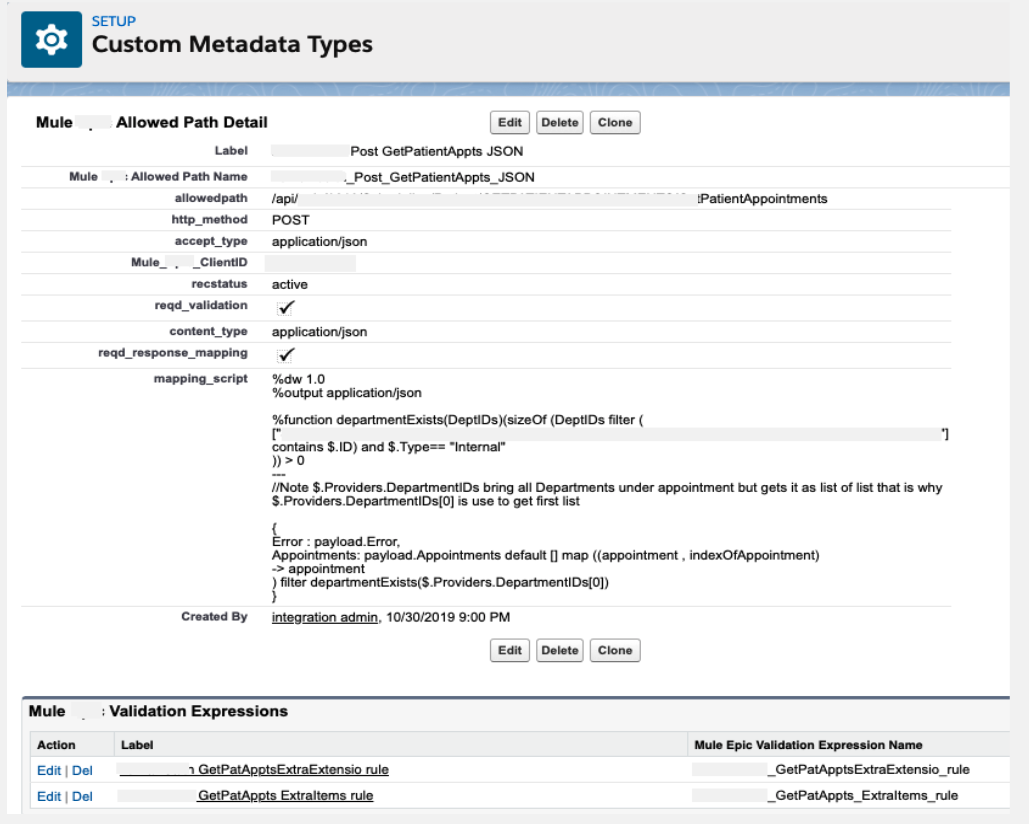
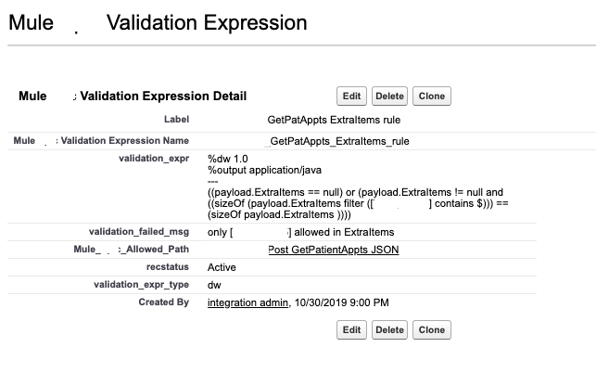
We store validation expressions so that we can determine whether we can check for extra items, such as if it’s a null. Using this method, we can check all of the validation rules for a specific client when the call comes through the Mule flow.
Benefits of dynamic DataWeave
By storing our DataWeave scripts in the external table, we can make changes faster and without needing help from other developers. Now, it’s very easy for us to make changes to the data validation and redaction rules. This provides flexibility and we can onboard new apps that want to use these Mule proxies much faster. Additionally, we have a faster turnaround for our API clients. It costs us less and our team is more efficient as we can focus on other important work, rather than, spending effort on changing these proxy flows. Our flows are easier to maintain and application developers who want to use these APIs are happier and able to be more productive. By utilizing Anypoint Platform, UCSF can ensure proper access and security of our patient data while continuing to better our patients’ experiences.
If you would like to watch my presentation at the Developer Meetup at MuleSoft CONNECT Digital Americas, you can find the recording and recap here!



