
Onboarding new employees in an organization has become a major headache for IT teams in every industry. With the advent of cheap cloud applications and decentralized software procurement decisions, users have access to an ever-growing number of applications to help them in their daily activities.
But the responsibility over user provisioning still rests in the hands of IT operations, who must ensure that users only have access to applications appropriate to their function. And on an ongoing basis, they must modify access for some users as new software is introduced for their team. They must also re-provision users when they move from one team to another, and deprovision them when they eventually leave the organization.
Even at a company the size of MuleSoft, this problem quickly became very significant for our own IT team. There are between 10 and 30 applications used by each worker (workers include employees and outside temporary staff). In this blog I explore the solution architecture I designed to automate user provisioning and deprovisioning for our worker populations throughout the entire lifecycle of each individual, from onboarding to team-change events and eventual retirement.
Users and their assignment to groups, applications, and roles
We do well to define our terms here:
- User: Uniform concept of a worker as opposed to their multiple application specific digital identities.
- Group: The team or department where a worker is employed. Ad-hoc groups can also be established, which are cross-functional in nature. Hence, a user can belong to multiple groups. This is sometimes synonymous to “role” from an organization perspective, but my definition of role doesn’t include this.
- Application: any application or backend system to which a user needs access.
- Role: A single application’s set of access control privileges. Users belonging to a single group may each be assigned different roles for a particular application. The role assigned is determined by information in the user profile.
- Entitlement: Mapping of a group to a set of applications.
User provisioning lifecycle
The worker population at MuleSoft constantly grows in size, though the number of teams is relatively static. As the company grows, employees switch teams; at the same time, the number of applications used across our teams continues to grow. As a result, one of the main challenges involves keeping track of the growing number of applications and the groups of users who should have access to them.
Based on the above challenge, I defined the future solution in these terms:
Worker onboarding is automated when, from their employment start date to their end date, users are provisioned in each application pertinent to their group(s) with the correct role for that application. As life-changing events occur to the worker (e.g. reassignment to different or additional groups), they are automatically added to and removed from all relevant applications. This includes final deprovisioning from all applications upon departure.
Capturing conceptual change
When I mused over the design of user-provisioning automation for MuleSoft, I focused on which parts of the problem incorporate a significant degree of change. The Gang of Four pointed out years ago that a central theme of many software design patterns is encapsulating the concept that varies so that change can occur without redesign. This is the spirit behind the design-to-interface principle. API consumers should know as little as possible about the implementation details. And, as a benefit of this decoupling, API consumers should continue to consume the API without being impacted by changes to the implementation. Applying this principle to the world of integration, we can affirm that the following implementation details are among those we should hide from consumers:
- API composition (invocation of other APIs through orchestration or choreography)
- The systems of record that are integrated
- The data models of those systems
- The security constraints of those systems
So what changes in our problem domain? Obviously, the growing population of workers represents change that –– without automation –– is a cause of major headache for our IT team. But the growing number of users and groups doesn’t change the concepts of users and groups. These are static concepts. They don’t change.
What does change as a concept is user-provisioning. The behavior of user-provisioning changes from application to application. Very different implementations are required between provisioning a user to Salesforce and provisioning a user to Google Apps, for example. And this kind of change is ongoing. The addition of new applications and entitlements to access them will require new user-provisioning implementations for each application.
Designing APIs with the “encapsulate what varies” principle in mind means aligning the interface to static concepts and hiding any variations behind it. Thus, a model solution to our problem should capture the user, group, and entitlement concepts in API definitions, and hide the variance in user-provisioning in multiple implementations.
The ongoing addition of new implementations can be automated by storing their endpoints in a database. Blind iteration through these can drive all user-provisioning.
Solution architecture
The SCIM standard
The System for Cross-domain Identity Management (SCIM) is a standard that addresses interoperability of identity information in the REST API world. It has two core specifications: one for a standard and extensible data model for users and groups, and one for the protocol governing the interactions of the REST API.
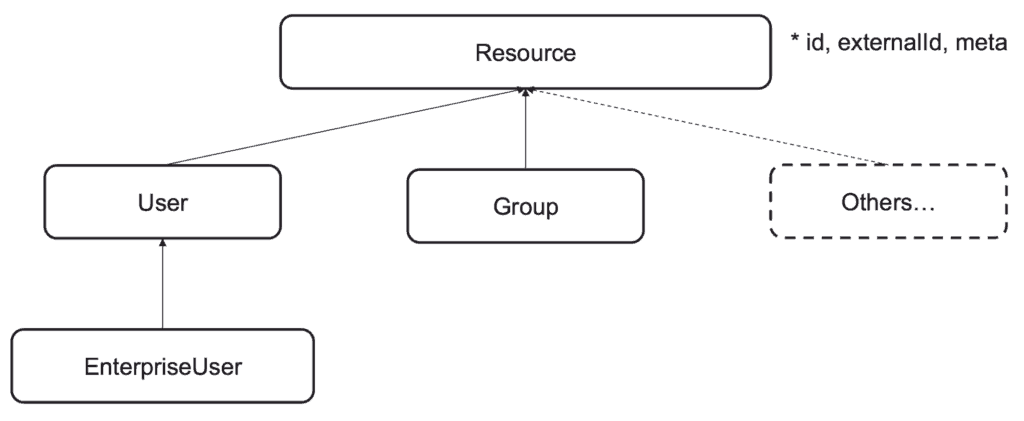
I chose this standard because it gave me a convenient industry-wide data model for users and groups. And I could exploit its extensibility to model the concept of entitlement. SCIM interoperability allows you to implement an API that you know can be consumed by any third-party software that conforms to the standard. Though our IT team are not currently using third-party software that needs to consume SCIM APIs I considered interoperability a key enabler of adding more entitlements. The IT team is not the only team at MuleSoft who develop Mule applications for internal purposes –– right now the training department are participating in the development of this architecture. They have built their own application provisioning Mule apps conformant to the SCIM API. Interoperability and federation of the development effort work well together.
Overview of the solution
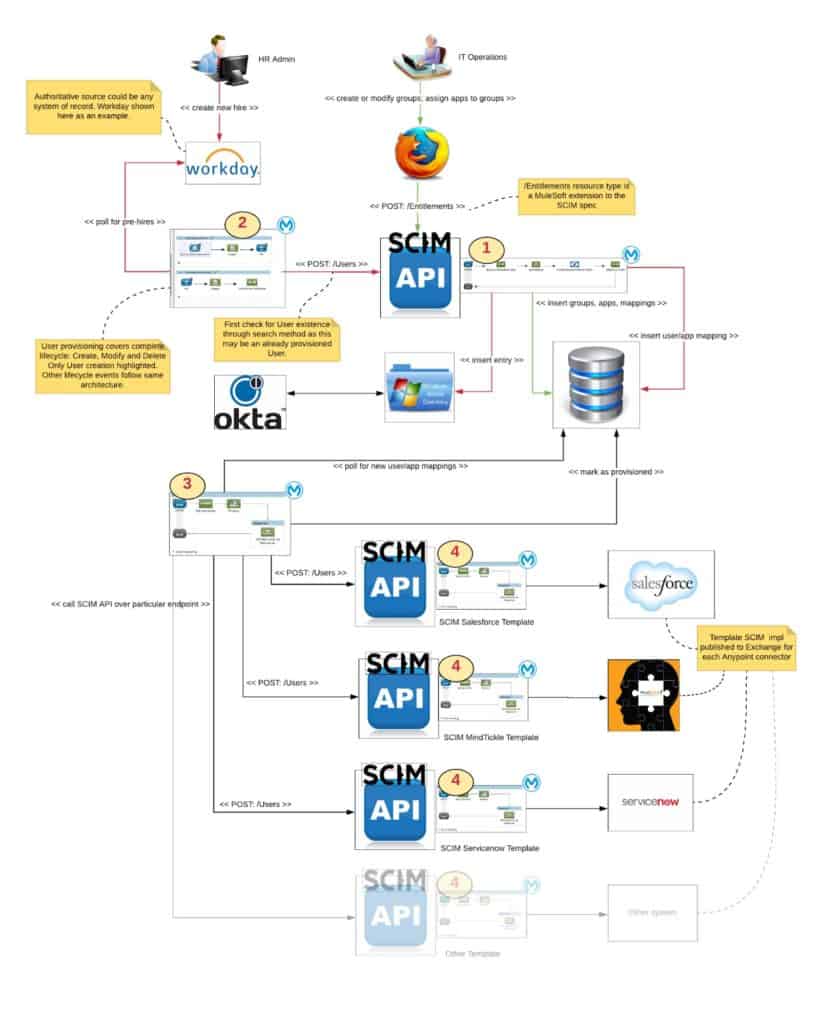
The overall architecture has four main parts:
- Entitlement administration: this Mule app with SCIM API is consumed by an application in the hands of our Operations team. They are charged with setting up groups that exist at MuleSoft, applications, and application <-> group mappings. When it is consumed by the User Event Handling app, it creates new provisioning / deprovisioning records for each application.
- User event handling: this Mule app polls Workday, which is the authoritative source for worker data at MuleSoft, for new hires and for changes to group assignments to users. It posts the batch of relevant users to the Entitlement Administration API.
- Provisioning orchestration: this Mule app polls the administration database for new provisioning / deprovisioning records and iterates through their endpoints, uniformly invoking the Application Provisioning SCIM API at that endpoint.
- Application provisioning: this Mule app with SCIM API is specific to an application to which a user must be provisioned. There is a separate Mule app implementing the SCIM API for each application with the specific requirements for that application.
User provisioning scenarios
Our IT team has set up the entitlements database by populating records with information about applications and groups as well as the entitlements that correlate which groups can use which applications. The User Event Handling Mule app is constantly polling Workday for user events. The Provisioning Orchestration Mule app is constantly polling the administration database for new provisioning records.
Worker starts
User Event Handling picks up new user information from Workday. Then, it transforms the data and passes it to the SCIM User resource in the Entitlement Administration API. This checks the user’s group and creates a separate pending provisioning record for that user for each entitlement associated with the user’s group. The Provisioning Orchestration app pulls those records and blindly iterates through them––invoking the set of APIs that correspond to the new applications to be provisioned.
Worker switches teams
The provisioning records may intersect with what was already provisioned for this existing user. Those applications, which do not pertain to the worker’s new team, will be deprovisioned for the user. Those which intersect may have their role assignment changed and e new applications will be provisioned.
IT Team creates a new entitlement
The Entitlement Administration API creates provisioning records for all users of the same group already provisioned for other entitlements. The Provisioning Orchestration app pulls those records and blindly iterates through them––invoking the set of APIs that correspond to the new applications to be provisioned.
Worker leaves
A deprovisioning record will be created for every application previously provisioned for the user.
Summary
This is a technical angle on a subject that interests me a lot: catering to ongoing business change by capturing in APIs what is common in the problem domain. To dive deeper into this topic, I refer you to my colleague Paul Henry’s blog series for more information on the implementation details.



