
A high-reliability application (one that has zero tolerance for message loss) not only requires the underlying ESB to be reliable, but that reliability needs to extend to individual connections. If your application uses a transactional transport such as JMS, VM, or DB, reliable messaging is ensured by the built-in support for transactions in the transport. This means, for example, that you can configure a transaction on a JMS inbound endpoint that makes sure messages are only removed from the JMS server when the transaction is committed. By doing this, you ensure that if an error occurs while processing the message, it will still be available for reprocessing.
In other words, the transactional support in these transports ensures that messages are delivered reliably from an inbound endpoint to an outbound endpoint or between processors within a flow.
A reliability pattern is a design that results in reliable messaging for an application even if the application receives messages from a non-transactional transport. A reliability pattern couples a reliable acquisition flow with an application logic flow, as shown in the following diagram.
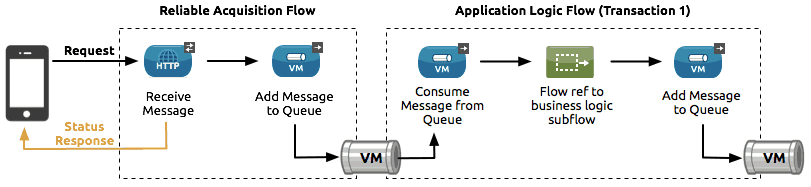
The reliable acquisition flow (that is, the left-hand part of the diagram) delivers a message reliably from an inbound endpoint to an outbound endpoint, even though the inbound endpoint is for a non-transactional transport. The outbound endpoint can be any type of transactional endpoint such as VM or JMS. If the reliable acquisition flow cannot deliver the message, it ensures that the message isn’t lost.
Up to this point, I haven’t said anything which isn’t already explained in the Reliability Patterns article of our developers documentation. So, why am I writing this? What’s new? Let’s consider this other example:
The above flow polls a sftp folder and processes the obtained files through a flow called “myErrorProneBusinessLogic“. If everything goes ok, the files are moved to an archiveDir so that they’re not reprocessed. But what happens if the business logic fails? After all, the flow is called “myErrorProneBusinessLogic“.
Reliability for the win!
On Mule versions prior to the 3.7 release, a failure scenario would have been a problem because the sftp wasn’t in the list of connectors which support reliable acquisition, meaning that upon failure, the file gets moved to archiveDir . In that case I’m sorry to say that the information in the file would be lost, because the file gets moved to a file on which we’re not polling.
But fear not! We fixed this for the 3.7 release and now you can do the same as follows:
Let’s analyse the above:
- An idempotent-redelivery-policy is now supported for the sftp connector. What this component does is to control how many times can each individual message be redelivered. It acts as a way of controlling how many times are we going to retry.
- The idExpression is a MEL expression used to give each message a unique id, so that we can quickly identified each message (needed for the idempotent part) without consuming the payload or performing CPU expensive computations.
- The maxRedeliveryCount is pretty descriptive, it’s up to how many times are we willing to retry a failing message. Note that in the worst case scenario, the message is processed maxRedeliveryCount+1 times (+1 is the original attempt)
- There’s a dead-letter-queue in the redelivery policy, which is the place where the message gets sent if the give up condition is met.
- Also not that the flow’s processing strategy was set to synchronous. That’s because if processing is asynchronous, the thread that’s polling (and owns the redelivery policy) does not get any potential exceptions raised by the business logic flow.
With the configuration above, reliable acquisition is achieved because if the file can’t be successfully processed, it gets send to the dead-letter-queue so that it can be appropriately handled, while on the sftp folder, the file is still removed because it makes no sense to keep trying. At the same time, the redelivery policy is of great help in the cases in which the error is caused by a short timed glitch, such as a network timeout, a DB being temporarily exhausted, etc.
Exception strategies
Although it is only supported for sftp since the 3.7 release, the idempotent-redelivery-policy component is not new to the Mule ESB, chances are you’re already familiar with that guy. You’re probably also familiar with the rollback-exception-strategy construct:
This alternate configurations works in a pretty similar way but using an exception strategy, which unlike the dead-letter-queue allows more than just one outbound endpoint, there’s more complex logic you can use in this case. Notice however that in this case, the reliable acquisition part is up to you! You could choose to simply write a few lines to the log without saving the message in any persistent manner, in which all that you built was a retry mechanism.
Wrapping up
The reliable acquisition pattern is important when dealing with non transactional endpoints. Although it can always be implemented manually (as shown on the first figure), we keep trying to make it simpler by supporting OOTB it in more and more components. Whether we automatically support it or you do it by manually, remember that what any world class integration should see is:




