
Roughly two years ago, MuleSoft announced the next generation of the managed integration platform, CloudHub 2.0.
The shift to CloudHub 2.0 isn’t just an upgrade – it’s a complete reimagining of how applications are deployed and managed in the cloud, leveraging the robustness of a Kubernetes-based architecture.
To briefly summarize the benefits, CloudHub 2.0 offers:
- Simplified deployments: A streamlined experience for running MuleSoft applications in the cloud
- Enhanced reliability: Applications are containerized and deployed across different availability zones as replicas, ensuring redundancy and reliability
- Flexible scaling: The platform provides more granular replica size options, allowing for precise scaling
- Load balancing (made easy!): With a built-in ingress load balancer that features auto-scaling capabilities in private space, there’s no longer a need to manage a dedicated load balancer
How does CloudHub 2.0 differ from CloudHub 1.0?
CloudHub 2.0 is a fully managed integration platform layer that revolutionizes the deployment of applications as containers in the cloud. This Kubernetes-based architecture significantly enhances application performance and scalability. With lightweight containers, applications can be scaled effortlessly to meet demand.
New technology also heralds change, and one of the major changes between CloudHub 1.0 and CloudHub 2.0 is the transition away from persistent VM queues.
We understand that some customers have investments in such queues. if a VM is utilized for parallel executions and a message is published before the listener subscribes, any app crash and subsequent restart would result in the loss of those messages. This is a critical issue for scenarios requiring message persistence, rendering persistent VM queue in CH2.0 an unsuitable option.
We want to offer a viable alternative, and this post aims to do exactly that; we’ll delve into the rationale behind this transition and explore alternatives to VM Queues that ensure reliable processing, efficient application deployment and message persistence.
Persistent VM Queue alternatives
To address this limitation, it’s essential to look towards actual message brokers such as Anypoint MQ, JMS, IBM, RabbitMQ, or Kafka. This document focuses on Anypoint MQ and Kafka (MSK) for VM Queue, ensuring the same functionality as the persistent VM queue in CH 1.0 for applications deployed to CH 2.0.
Below are the snippets of a utility app for both Anypoint MQ and Kafka with a scheduler which acts as the initial trigger for the entire data flow process. Upon activation, the scheduler initiates a query to the database, retrieving records that are then individually published as messages.
These messages are directed either to Anypoint MQ or a Kafka topic, depending on the configuration
As soon as a message is published to Anypoint MQ or the Kafka topic, a subscriber within the application is already configured to read and process that message. This ensures a near-instantaneous transfer of data from publication to subscription.
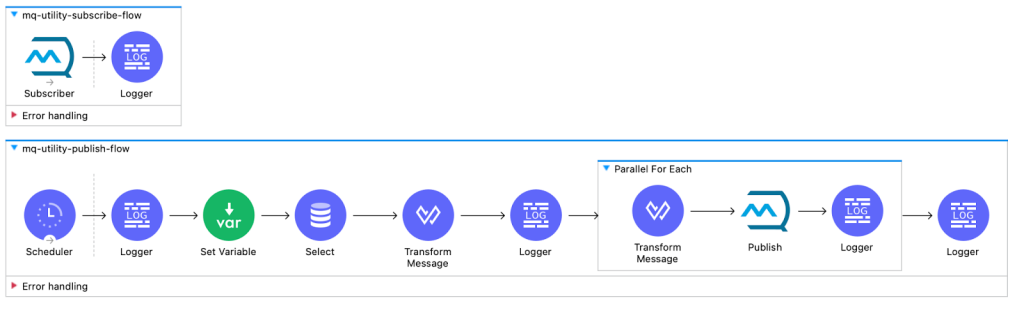
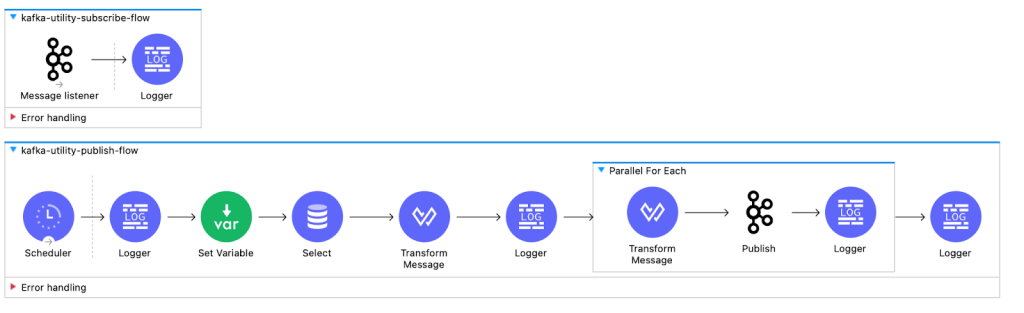
Deployment of this utility app is robust and scalable, thanks to CloudHub 2.0. We’ve deployed eight replicas of the application, all operating in a runtime cluster mode to ensure high availability and fault tolerance. The scheduler is configured to run on-demand, ensuring that the records retrieved from the database are published without delay to the designated Anypoint MQ or Kafka topic. Subsequently, these messages are immediately picked up by the subscribe flow.
One of the most impressive features of this application is its intelligent distribution of tasks among the replicas. Each replica is designed to subscribe to and process each message, ensuring that the workload is evenly distributed and that no message goes unattended.
We’ve rigorously tested the application with various record sizes, ranging from 500 to a substantial 50,000 records. During these tests, one replica is dynamically elected as the primary node, which exclusively triggers the scheduler. This ensures that there is no duplication in message processing, as all replicas, including the primary, are designed to subscribe to messages from the queue.
Implementing Concurrent Processing with Scheduler as a source trigger
When deploying a Mule application to CH 2.0, enabling clustering mode is imperative for concurrent processing when a scheduler is a source trigger. This setup is non-negotiable, as failure to enable clustering can lead to duplicate processing of records. In a CH 2.0 environment, each application is packaged and deployed as a container. The replicas, or pods, cannot share memory, which means that schedulers within the Mule app would trigger across all replicas if clustering is not active.
Enabling Runtime Cluster Mode
To activate runtime cluster mode during deployment, select the “Run in Runtime Cluster mode” option in the Runtime Options. This ensures that when an app is deployed across multiple replicas, only the primary node, designated in the backend, will trigger the scheduler. This mechanism is crucial for maintaining the integrity of the execution process and preventing the duplication of tasks
Note: To deploy the mule app with cluster mode, it requires at least two replicas

Conclusion
To recognize the array of benefits from CH 2.0 around simplified deployments, enhanced reliability, flexible scaling and simplified load balancing, it is necessary to reevaluate the tools and methods used for asynchronous execution. By adopting robust message brokers, and ensuring proper clustering configurations, applications can achieve the desired level of persistence and reliability that was once provided by VM Queue. As we embrace these new technologies, we pave the way for more efficient and resilient application architectures.



