
Etymology of net (n.): Old English net “open textile fabric tied or woven with a mesh for catching fish, birds, or wild animals alive; network; spider web.”
Source, emphasis from the author
For the last year and a half, data integration strategy has been top of mind for many of the enterprise technology leaders I’ve been working with. In the first blog of this series about capitalizing on data economics, I explored the reasons why data is so valuable. In part two, I introduced the concept of data liquidity and how APIs can be used to liquefy data. In this third and final blog, I will look at the emerging data mesh approach that has come up in many of my conversations, examining its implications on distributed data access in the enterprise, and how it fits into a recommended approach for dealing with the intersection of the analytics and application realms.
The data mesh concept was introduced in early 2019 by Zhamak Dehghani on Martin Fowler’s bliki. It aims to solve issues typically found in enterprise data analytics. To take advantage of the rapid pace of technological innovation in the big data realm, data platforms – and by association, the data stored on them – have typically been owned and run by centralized teams of technology experts. This monolithic approach causes bottlenecks, and the lack of business domain expertise in the centralized team has led to data ownership and quality issues. I was already familiar with Dehghani’s work, as she had given some of the most practical talks I had seen on microservice architecture and domain-driven design (DDD), so it’s no surprise that data mesh is founded on these techniques that have been used to deal with similar problems in the user-facing application world.
Data mesh was originally defined with three principles. The first is to use a distributed domain-driven architectural approach with the data to have business-aligned data and establish appropriate ownership. This is intended to help improve data quality and organizational scalability. The second principle is to take a product thinking approach to manage the domain data. It is about having the domain teams who own the data ensure their data is made discoverable, addressable, trustworthy, self-describing, interoperable, and secure. This set of attributes extends the FAIR data principles that are becoming increasingly popular. In addition to the attributes, product thinking also implies that organizations should be made up primarily of cross-functional product teams, synonymous with the “stream-aligned teams” found in the excellent book, Team Topologies. The third principle is to adopt a self-serve approach to the data platform, to free up the centralized data engineering team from being the overall data and platform owners to focusing on designing, maintaining, and governing a multi-tenant platform. Notably, this matches the “platform team” idea from Team Topologies. This principle is intended to help the domain teams work as independently as possible to remove bottlenecks and positively impact quality by having the teams producing the data be closer to the data consumers. The three principles are summarized in the image below.

Now that we understand what data mesh is and what it’s intended to do, I would like to briefly talk about what it is not. We tend to overload terms in technology, and the dizzying array of buzzwords we encounter can lead people to make assumptions. Remember how much people obsessed over how big a microservice should be when that was never the point? I illustrated the synonymy between the words “network,” “web,” “mesh,” and “fabric” in the etymology example I included as the prologue to this blog. Well, there is in fact a separate concept known as “data fabric” that has been in the industry for several years. It was originally used to describe the idea of amalgamating all tools in the data analytics lifecycle in one platform, but Gartner has recently used the term to define a concept more focused on metadata associated with an organization’s data landscape. Either way, data fabric does not equal data mesh.
Another popular concept in the distributed application realm is “service mesh.” It may be tempting to think of data mesh as a “service mesh for data.” This would be wrong. In my experience, “service mesh” is much more a distributed implementation approach to inter-service communication in a container-based application paradigm. A better analogy is to think of data mesh as the application of microservice architectural principles to the data analytics paradigm. Ultimately though, I encourage you to resist analogical thinking and be as open-minded as possible. An important lesson I’ve learned in the last year is that although the analytics world is a big part of the software engineering landscape, it is very different from the world of user-facing, real-time applications that I’ve grown up in. Many different considerations change how you should optimize and what architectural decisions you should make, some of which I covered in my previous blog entitled, “Composable data for the composable enterprise.”
That experience of taking the beginner’s mind to analytics leads me to point out a few areas where I think the data mesh concept will be challenged as organizations strive to adopt it. Firstly, fundamental forces are driving the centralization of data. In part one of this blog series, I demonstrated that the economics of data prove that correlating data, sometimes even serendipitously, can lead to the exponential growth of its value. Zhamak Dehghani addresses this need for aggregates and correlated data, but in my opinion, the centralization forces will be even more difficult to overcome than the gravity of the monolith in the application world (which was hard enough). Secondly, the way data mesh is proposed, I believe there will be a tendency to “start at the back” and try to break up the producer domains and have aligned product teams for each. Even though this fits with a purist architectural approach, I think this could be a misstep for organizations. To instill a product mentality, you first need to focus on value exchange. It is consumers who are capturing value in the data mesh scenario, so I think the first place to introduce product thinking is on the data products being consumed, not the underlying domain building blocks. We’ve observed in designing APIs as products, it’s always best to start with the consumer and work backward. My last concern about enterprises implementing data mesh is that there are many factors to consider–especially sound statistical methods–when it comes to data quality, and data mesh won’t solve them all. As with all new approaches, it’s important to get the context right.
Despite these concerns, I am very excited about the data mesh concept overall, and Dehghani has done a superb job of articulating it through her blogs as well as in an upcoming O’Reilly book. Of course, the focus on decomposing data into reusable components is perfectly aligned with the theory of complex systems, the inspiration behind API-led connectivity. In fact, Dehghani was partly inspired by the way user-facing applications have been decomposed using APIs. In the seminal blog, she notes that organizations now “provide these capabilities as APIs to the rest of the developers in the organization, as building blocks of creating higher-order value and functionality.” She further talks about how API product owners emphasize developer experience through areas such as “API documentation, API test sandboxes, and closely tracked quality and adoption KPIs,” and suggest data domain product owners do the same.
Another aspect of data mesh I see as positive is the emphasis on the business value and meaning of data, rather than on the enabling technologies. In Dehghani’s words, “The main shift is to treat domain data product as a first-class concern, and data lake tooling and pipeline as a second-class concern – an implementation detail.” In the first blog of this series, I made the case for viewing data as a form of digital capital, exchangeable for other “currencies” such as money, products, services, and even time-to-market or market access. Thinking about how specific data domains can be productized takes this mindset even further and should drive better outcomes for data mesh adopters.
Additionally, the notion of applying software engineering best practices to data engineering is a great direction. Similar to operational automation, groundbreaking analytics technologies like Apache Spark and machine learning have been introduced to organizations rapidly. Putting the new approaches through the lens of software architecture and software engineering will help to introduce rigor that should lead to improved quality, consistency, and efficiency. This is exactly what has happened to software deployment and operational automation as a result of the DevOps movement.
The final aspect of data mesh I want to highlight is the one I find most intriguing, and it’s right there in the name. When looking at their data strategies, many organizations focus on where to put the data. Data warehouses, data lakes, and cloud data platforms all contain an inherent reference to the location of the data itself. When it comes to the number-crunching of analytics, there are good reasons for collocation. However, if we look at the world of data from the consumer’s point of view, the location of the data is secondary to their ability to access it at the point of use. In essence, consumers don’t care about a data platform, but what they need is a data network. And data mesh is designed with a network mentality.
In a follow-up blog post to her first, Zhamak Dehghani explores data mesh principles using a fictional implementation example but also uses the network concept of “planes” to illustrate the flexibility of the approach. In the blog, she also adds a fourth data mesh principle: federated computational governance.

Federated computational governance focuses on maintaining the balance between data domain independence and the interoperability of data domains. Left ungoverned, these two goals work against each other. To achieve this balance, she proposes a federated governance model co-led by the domain data owner and the platform team. During a talk at the Spark+AI Summit 2020 event, data engineer Max Schultze describes his experiences implementing data mesh at Zalando, a leading European retailer. He specifically calls out this governance approach of having distributed data ownership while maintaining centralized governance as a key benefit area.
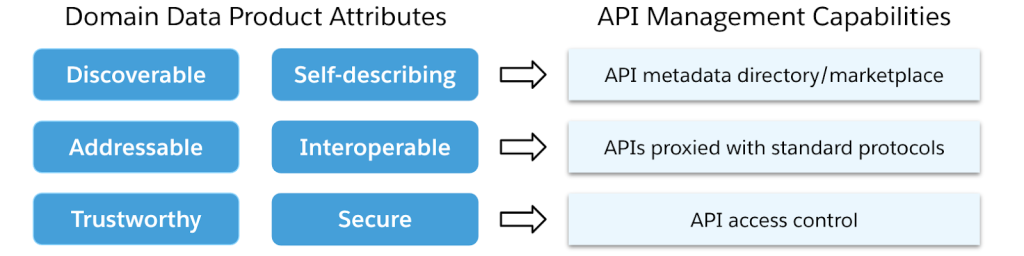
Network thinking is core to this fourth principle of data mesh. Regarding federated computational governance, Dehghani states that, “ultimately global decisions have one purpose, creating interoperability and a compounding network effect through discovery and composition of data products.” To achieve this governance approach, emphasis needs to be placed on the product attributes Dehghani cited in her first blog. These are listed in the image below.

What strikes me about this list is how all of these attributes are also attributes we in the API community have been touting for well-designed API products. One of the key benefits APIs have provided in the world of user-facing applications is to decouple API consumers and providers through network abstraction: a “data plane” of business capabilities and a “control plane” of API management. As illustrated in the image below, the data product attributes listed in the definition of data mesh align directly with API management capabilities. This suggests that a data mesh approach would be ideal for exposing data from the analytics world into the applications world. For instance, consider how data mesh could help consistently deliver a set of ML-generated, personalized offers to individual customers via multiple channels of engagement. This is but one example.
To conclude this blog series, I would like to bring several ideas together. As per my first blog on the economics of data, there are essential reasons why data needs to be centralized to maximize its value. However, as per my second blog on data liquidity, that data also needs to be decomposed and distributed to points of consumption in the application realm. I articulated an approach I called “API-led data connectivity” to address this need. In this blog, we can see how well-aligned the data mesh approach is with API product best practices and API management. I will now close with three thoughts:
Thought #1 – Analytics data that needs to be consumed by user-facing applications should do so through domain data products as per the data mesh approach. This thought follows from the fact that applications consuming data need it to be in some decomposed form to optimize for real-time distribution.
Thought #2 – These domain data products should be exposed to the application realm through APIs and governed by API management. This thought follows from the practical alignment of API products and API management with data mesh principles.
Thought #3 – Organizations wanting to introduce data mesh should start by focusing on the consumption of analytics data by the application realm. If organizations start applying data mesh first at the supply side, they could end up fighting with the centralized gravity of data economics I mentioned above. In focusing data mesh on the boundary with the distributed applications world, they will benefit from the composable, network-oriented mindset that is embedded in that realm’s culture. Will these hypotheses prove true?
Time will tell if these thoughts are proven true. There is more to explore on the intersection of analytics and applications through APIs. If you would like to learn more about MuleSoft’s offerings in the data space, I encourage you to check out our new Anypoint DataGraph product. It offers a great way of liquefying your data for consumption at user-facing channels. I hope you enjoyed this blog series and bye for now!



