
This is the first in a three-part series on how APIs can be used to maximize the value of data in a digital organization.
Every organization is looking for ways to capitalize on the opportunities presented by the digital economy, whether they consider themselves to be “digitally transforming” or not. With the pace of technological innovation increasing and a growing list of “must-have” technologies — containers, serverless, AI, ML, RPA — leaders of these organizations struggle to keep up. So why are web-native companies setting the bar for the digital economy? What are they doing that companies established pre-web are not?
The economics of data
Web-native companies are certainly tech-savvy, but their most powerful differentiation is data fluency. It is data that Facebook and Google collect from users and turn into ad revenue. Amazon turns data on buying behavior into recommendations that lead to higher sales, and logistics data into supply chain cost reductions. Chinese conglomerate Tencent collects data across all of its business lines — from social to retail to payments — to leverage “closed-loop data” that drives its digital business model. Data drives the digital economy, and these companies are the data experts.
Organizations that want to succeed in the digital economy need to change their mindset on data. Rather than think about data as part of their technology landscape, they need to treat data as a capital asset. In previous blogs, I have discussed how data is a form of exchanged value that companies should consider when defining innovative digital business models. I have also talked specifically about how APIs and AI can be used to capture, create, and deliver value using data as the value currency. In this blog series, I want to look at the economics of data and the role that APIs can play.
Economists have been studying data for quite a while now, and have acknowledged that data breaks many standard economic theories that were developed based on physical goods. In economic terms, data is considered to be a non-rival, non-fungible, experience good. Let’s examine each of these attributes:
- A rival good is one that can only be possessed or consumed by a single user, whereas a non-rival good can be consumed or held by users simultaneously. A cake is a rival good (you can’t have your cake and eat it too!) The song “Happy Birthday” is a non-rival good.
- A fungible good is one whose units are interchangeable, whereas non-fungible goods are unique and cannot be substituted for one another. An artist’s paintbrush is fungible. An artist’s paintings are not (nor is a digital artist’s NFT’s).
- An experience good is one whose value is not known until it is consumed. This contrasts with search goods, whose value can be determined pre-purchase. A haircut is an experience good. A hat is a search good. (Interestingly, the more data you have on a good, the more likely it is to be a search good as opposed to an experience good)
Using these three dimensions to classify data, you now have an easy retort for the next person who claims that “data is the new oil.” Oil is a rival, fungible, search good, the exact opposite of data!
There is another economic property of data that is vital to consider. The more data you collect, the greater the value of the data you already have. In economic terms, this is considered a “positive externality.” This effect goes even deeper when you consider the growth in understanding of the data you have. Increased correlation and contextualization of the data you possess leads to a non-linear increase in its value. Consider Google’s collection of web searches, map queries, and YouTube views. It is the correlation and contextual understanding of that data that allows it to fuel their lucrative advertising engine. We now have a robust economic definition of data:
In economic terms, data is a non-rival, non-fungible, experience good whose value increases non-linearly as it is collected and correlated.
Leveraging data’s economic properties
Leaders driving an enterprise’s digital transformation can harness this economic understanding to guide their data strategy. The economic characteristics of data reveal both opportunities and risks, as shown in the table below:
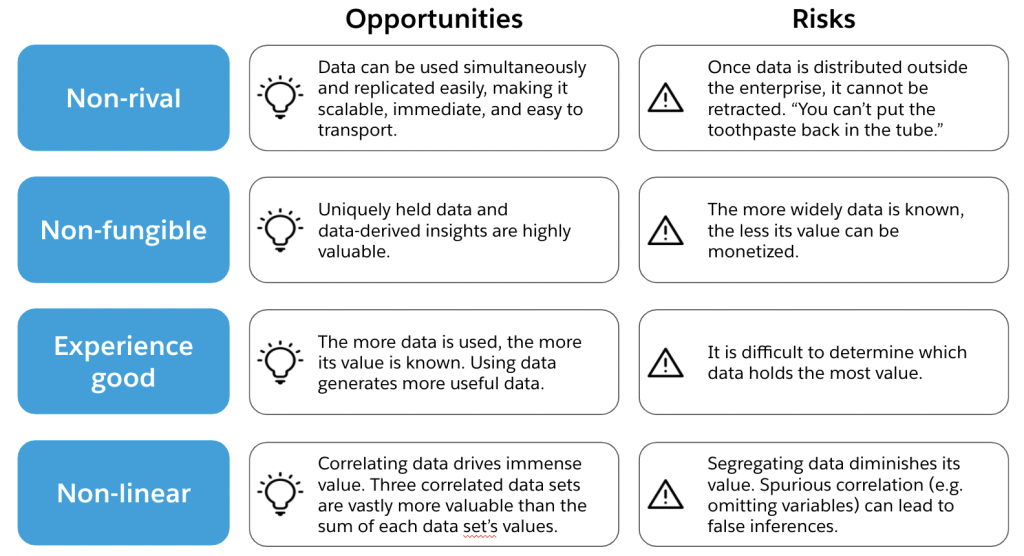
Taken together, these benefits and risks suggest specific principles organizations should adopt in order to maximize the value of their data:
Data economics principle #1: Share it
Data’s non-fungibility makes it valuable to collect. The non-linear growth in value caused by data correlation means it should be as connected as possible. The good news is that data’s non-rival nature makes its distribution fast, simple, and scalable. Therefore, data should be interconnected and shared widely within an organization. For best results, access needs to be immediately available and ubiquitous.
Data economics principle #2: Use it
Data being an experience good means it should be consumed as much as possible to determine and predict its value. An even bigger benefit of increased data usage is that using data generates more data — metadata, behavioral data, contextual data — that can instantly be correlated with the data being consumed. As discussed above, this phenomenon drives a big increase in value of the collective data. Accordingly, data should be utilized and synthesized in as many user contexts as possible.
Data economics principle #3: Protect it
The third principle runs counter to the other two. As previously discussed, data’s non-rival nature makes it impossible to retract. Because data is non-fungible, it can potentially be devalued by letting it outside the organization’s perimeter. Thus, organizations should carefully govern third-party access to unique data and proprietary data derivatives.
These principles are fundamental to a sound economic data strategy, but how can they be implemented? We will examine that question and the way APIs and API management can help out in parts two and three of this blog series. For now, I hope this blog has opened your mind to the economic potential of data, if not to the subject of economics itself.
Digital transformation requires a transformation in the strategic assumptions associated with data. As David Rogers puts it in his superb book, The Digital Transformation Playbook, data must not only be perceived as “a tool for optimizing processes.” It must be viewed as “a key intangible asset for value creation.” That is certainly the way it has been used at the most successful digital companies on the planet.
Thanks to Sinan Onder, Mike Amundsen, Stephen Fishman, and my former college roommate/current economic director Thomas Storring for their contributions to this blog.


