
Here’s how NVIDIA leveraged an API-led approach to build system APIs for backend applications and stitch data together using a process API that leverages MuleSoft’s Message Processors.
This story was written by Saiesh Prakash, Cloud Integration Architect at NVIDIA. Saiesh plays a critical role in his organization. He and his team’s mission is to enable digital transformation, improve development processes, promote reusability, and reduce development times across multiple projects with an API-driven architecture.
The GDPR initiative has proved to be a critical integration project for companies around the world. At NVIDIA, the Silicon Valley-based accelerated-computing company where I work as a Cloud Integration Architect, we wanted to ensure customers could visualize all the information NVIDIA had collected on them in a single view, and be able to delete this data from all our backend systems upon request, all within a one-minute SLA.
This project wasn’t going to be easy, but the clock was ticking as we had to be ready to launch before GDPR fines applied.
Some of the challenges included:
- Customer data was spread across 12 different systems, both in the cloud and in on-premise applications.
- Each system used different data formats that had to be collected and stitched into one JSON to be rendered by the UI within the one-minute SLA.
- Applications had different kinds of restrictions, such as firewalls, security, and IP whitelisting.
- Time had been lost after an unsuccessful integration attempt using Java before handing it over to MuleSoft – and further delay could mean millions of dollars in fines.
Using an API-led pattern to integrate data from 12 different apps across cloud and on-premises
As a MuleSoft customer since 2017, NVIDIA decided to follow an API-led approach where we build system APIs for backend applications and stitch data together using a process API that leverages MuleSoft’s Message Processors. This is illustrated in the following diagram:
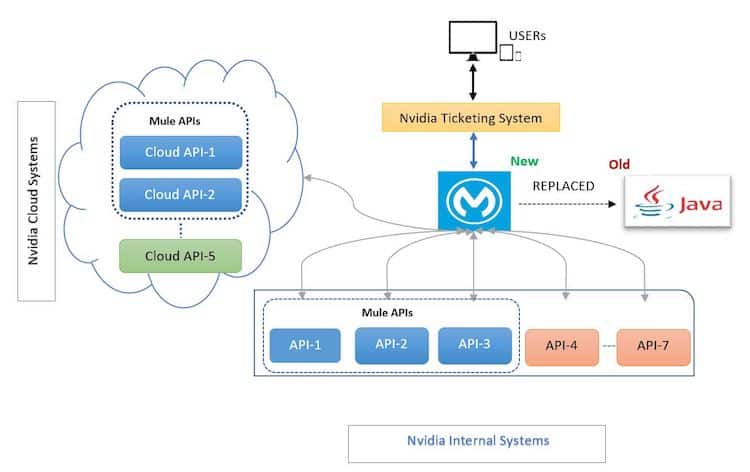
The first step in the process was to create system APIs using MuleSoft to access data from different backend systems and cloud applications, such as Salesforce, internal databases, and web services.
Building these system APIs with MuleSoft provided the following advantages:
- It standardized all the systems’ output formats (using MuleSoft’s DataWeave transformer) to make the data consumable.
- Leveraging different MuleSoft connectors for different systems (such as Salesforce, DB, Marketo, Web Service Consumer, HTTP Requestor) eased configuration and sped up development.
- Security was implemented across all the APIs with RAML-based security schemes.
- These APIs were published on MuleSoft’s Anypoint Exchange, promoting reusability across the organization.
- New systems for data visualization and deletion were added with ease without affecting any existing integration, making the whole solution scalable.
Executing these multiple system APIs concurrently
Once we had our APIs in place, the next step was to continuously poll our ticketing system for requests opened by users to fetch/delete their data, call all these system APIs, and merge responses together.
The ticketing application had exposed SOAP web services to search open tickets.
We used the Mule Poll component to poll every minute and queried the ticketing service using the Mule Web Service Consumer component.Then we used Scatter-Gather to route incoming requests (data visualization or deletion) to all the system APIs in parallel threads.
Thanks to this process, we were able to reach our objective of executing the 12 APIs concurrently, ensuring faster processing times to meet the one-minute SLA.
Scatter-Gather made it easier to configure specific error-processing strategies for different routes and apply message filters when no data was found. The Gather component fit perfectly to merge data from all the APIs for data visualization requests. The response payload was then filtered and formatted using DataWeave.
Deploying integrations using CloudHub VPC and AWS Peering
One of the deployment challenges we faced was to establish connectivity to the different backend systems from the Mule apps deployed on CloudHub. Indeed, these backend systems were scattered across third-party cloud services, Amazon AWS, and internal on-premise systems with corporate firewall rules and IP blocking in place.
To resolve this challenge, we set up the Mule Virtual Private Cloud (VPC) for our Mule apps with support from the MuleSoft Services team to create an isolated network with a private IP address space. This helped connect to on-premise applications using an IPSec tunnel as well as connect to AWS applications with VPC peering. Static IPs were then used to whitelist requests originating from Mule applications deployed on the private CloudHub workers.
Achieving GDPR compliance in time
Thanks to this approach, we were able to allow our users to see and delete the data we had about them, and thus meet the GDPR requirements on time, saving the company tremendous fines.
The API-led architecture, along with our APIs being available in Exchange, promoted reusability within the organization and significantly reduced development times. It’ll keep doing so as teams reuse these assets.
We did the design in one week, built it in two weeks, and deployed in two days. All in all, it was a quick project from start to finish, with performance requirements met by a small team of six people.



