
In the first blog post of this series, we described how Anypoint DataGraph relates to API-led connectivity. In the second post, we presented three approaches on how to consume APIs:
- Direct call: When the application directly calls System APIs
- Experience API: When the application calls dedicated Experience API
- DataGraph: When the application calls DataGraph endpoint
In this final post of the series, we will compare these three approaches based on a selection of characteristics:
Integration effort
The direct call approach requires more integration effort because all integration logic has to be manually coded in the consuming application. With the Experience API approach, Experience and Process APIs have to be specified and implemented. This approach requires less work because it uses the Anypoint toolchain that fully supports this API lifecycle. The DataGraph approach requires the lowest integration effort, as the consuming application only needs to describe the desired result in GraphQL. Anypoint Datagraph is a generic solution in this context.
Reuse potential
With the direct call approach, the connectivity logic in Systems APIs can be reused across use cases. In contrast, it is difficult to reuse any integration logic as it is built into the consuming application. The Experience API approach introduces a separation of concern by structuring APIs across layers. As a result, Process and System APIs have a high potential for reuse. In the context of the DataGraph approach, Anypoint Datagraph is a generic solution that can be reused across multiple use cases.
Self-service
Self-service is key for developers of consuming applications to be able to publish, document, and search APIs. With this prerequisite, developers in the direct call approach can search for System APIs and use them without the need to align with the teams providing the APIs. The same is true for the Experience API approach. The only dependency here is on the skills required to build Mule applications that implement Experience and Process APIs. Thus, a Center for Enablement (C4E) is important because it fulfills two key functions: a.) driving enablement within the organization and b.) managing Anypoint Platform. The DataGraph approach only requires the mobile team to have GraphQL know-how.
Expressiveness
How do the different approaches compare in situations that require complex integration logic? For example, if a simple mapping is not enough to merge information between systems with fundamentally different data models. In the direct call approach, the integration logic is manually coded on the consumer side and not limited in its expressiveness. In the Experience API approach, the integration logic is built in the form of a Mule application. Combining two main means of expression, Mule applications can also cover practically any use case: 1. A Mule flow that describes various control flow patterns like sequence, split-join, choice, loop, etc., and 2. DataWeave, a functional special purpose language for data manipulation. In this comparison, the DataGraph approach appears to be most limited by the expressiveness of the GraphQL standard and the capabilities of DataGraph.
Processing performance
Both the direct call and Experience API approaches offer full control to developers to optimize integration logic for specific use cases. With the direct call approach, the integration logic resides on the side of the consuming application so there might be hardware restrictions regarding processing power. For example, in our earlier mobile application use case, we are bound in processing power and scalability options.
In the Experience API approach, integration logic resides on the server side. The structuring of integration logic along the API-led layering introduces the ability to scale on every layer independently. Processing performance in the DataGraph approach depends on the ability of DataGraph to optimize the execution of incoming GraphQL requests. The challenge here is that all requests run through the same processing pipeline. Thus, optimizing for a specific use case can influence the performance of other use cases.
Network performance
How do the approaches compare in regard to the amount of data that needs to be moved over the internet and the number of calls required? In the direct call approach, there is a possibility that we could be working with a massive amount of data. This is because System APIs that the consuming application is calling are not optimized for the specific use case and channel. They are generic in this regard. Thus, they need to expose all the data that might be required in any upcoming use case to be reusable. This can result in large amounts of data transferred over the internet because filtering the result set and selecting relevant fields is done after the data is transferred.
In the Experience API approach, the Experience API is dedicated to tailor data for a specific channel. Thus, only the relevant data is transferred and only one call is required. The same goes for the DataGraph option, however the key difference is that the tailoring is done by specifying the GraphQL request.
Maintainability
Regarding maintainability, we focus on a specific aspect: Managing the dependencies between APIs and consumers in the context of change or service degradation. If a breaking change for an API is planned, it is important to handle its relationship to all consuming applications; for example, marking the API as deprecated and notifying owners of the consuming applications. In the direct call option, this is manageable but a large amount of consumers could pose a challenge.
The Experience API approach has two characteristics supporting the management of dependencies: 1. The API-led connectivity isolates changes and consolidates orchestration logic in the Process layer. This potentially reduces the amount of dependencies. 2. Anypoint Platform provides the Visualizer tool that provides insight into the network of dependencies between APIs.
In the DataGraph option, the ability of the DataGraph endpoint to provide access to all APIs in the Unified Schema becomes a drawback. If a breaking change is required for any of the APIs in the Unified Schema then all consumers of the endpoint are potentially affected. With DataGraph, consumers depend on the requested set of fields exposed in the service schema. In this regard, the dependencies are granular and dynamic. By opening up a GraphQL endpoint, you lose some control of what API consumers are able to do. GraphQL gives a lot of power to the API consumer, but also offers means to control it.
Summary
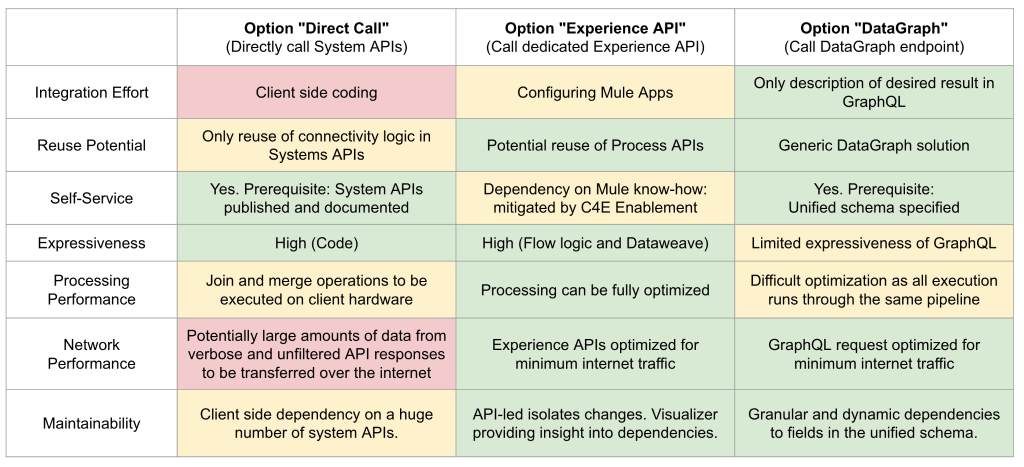
The spreadsheet above provides an overview of our comparison. The colors green, yellow, and red indicate how well each option delivers on the characteristics listed on the left.
None of these approaches are overall superior in every evaluated characteristic so there will not be a best option for all use cases. We see the direct call, Experience API, and DataGraph approaches as complementary consumption patterns. For example, if you have invested in an API-led approach and built a set of holistic, domain-oriented Process APIs then you can leverage this investment with DataGraph to add a flexible way to consume these APIs. In the context of the command query responsibility segregation (CQRS) pattern, you could also think about combining different approaches for reading and changing data like using a DataGraph endpoint for queries and an Experience API for updates.
If we look at the overview spreadsheet above, the DataGraph approach (calling a DataGraph endpoint) is best suited for minimizing integration effort and maximizing reuse and self-service. These characteristics together have a huge impact on reducing development effort and driving speed of delivery. These properties are key to building and delivering innovative customer experiences at a high speed and a high rate with limited resources. Thus, the DataGraph approach is a perfect fit for driving innovation.
If new customer experiences gain traction, priorities may change. In our example, many fast iterations of our mobile application may be built and thrown away before it fits customer expectations and gets broadly accepted. This phase would benefit from leveraging a DataGraph endpoint. Later the roll-out will become broader and the rate of change will decrease. In this phase, characteristics like scalability and manageability become more important. Thus, at some point in time the developer might switch to the Experience API option and implement Process and Experience APIs instead of using DataGraph.
Last but not least, the most important factor to take into account will always be the preferences and capabilities of the developers that create the API-consuming applications. Always think about APIs as products and study their market before making design decisions.



