
Have you ever tried installing a new app, but it fails when you actually use it? Now imagine that disappointment played out at enterprise scale. With today’s AI gold rush, building generative AI features has become almost routine. But the real triumph lies not in launching them – it’s in making them matter to customers.
From building to benefiting: Bridging the AI value gap
Enterprises are racing to bring AI into their operations, from writing emails and automating workflows to generating integration flows and complex coding. But countless reports reveal that most of these shiny features never deliver actual value. A staggering 95% of generative AI pilots fail to create measurable impact on the bottom line, despite impressive hype and investment. That means only 5% actually progress to meaningful outcomes.
In short, launching an AI feature isn’t the same as creating value. The buzz is high, but the payoff is often low. Organizations may check the technical box of “AI capability,” but without trust, consistency, and guardrails, that capability doesn’t translate into customer confidence or business impact.
This gap between building and benefiting is at the heart of why quality assurance is mission-critical. Consistent, observable, correct behavior distinguishes generative AI tools that are trusted from those relegated to novelty. It’s not enough for an AI system to work on paper or in a demo. What counts is that it works reliably in real-world, high-stakes workflows.
In a sea of competing AI features, what separates the winners is not just what they can do, but how reliably they can keep doing it. And that’s why, before anything else, we must guard their quality.

Assurance at MuleSoft
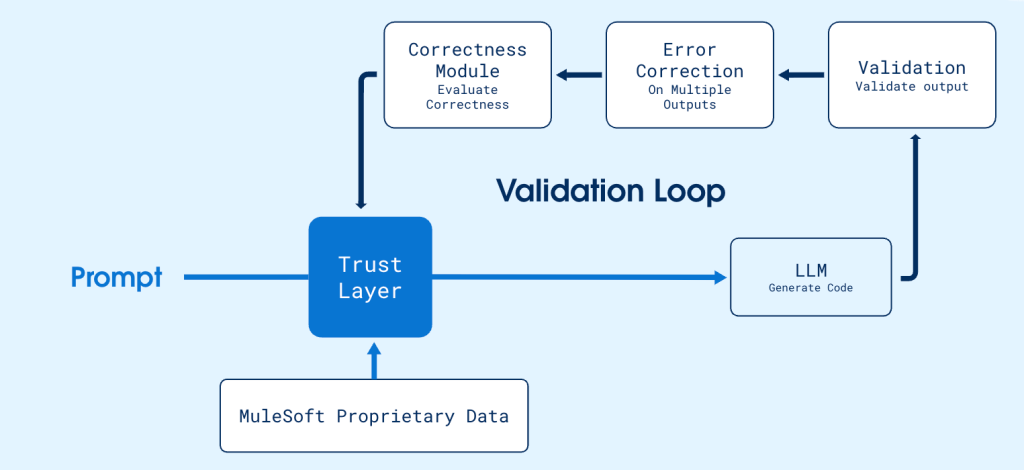
At MuleSoft, we faced the challenge outlined in the introduction: transforming promising AI features into solutions customers can truly rely on. Take our generative integration flows as an example. LLMs are powerful, but left unchecked they often produce outputs that look right while hiding critical flaws: syntax errors, outdated or incompatible operations, or incomplete logic that frustrates users instead of helping them.
We address this with a multi-layered approach to quality. First, we ground AI prompts with proprietary data we built in-house, covering around 200 connectors and over 7,000 operations. This reduces hallucinations and keeps generated flows anchored in reality. Our IDE-integrated validator automatically checks outputs for syntax and compatibility, catching errors before they reach the user. When issues arise, the system prioritizes fixes and guides the AI using related metadata, turning almost any flawed snippet into a valid, usable flow.
Validation alone isn’t enough; correctness matters more. A flow can be syntactically valid but still miss critical business logic. The key question is whether the generated flow actually fulfills the user’s requested functionality. To ensure this, we use a well curated LLM judge to evaluate outputs against user intent, making certain that delivered flows are functional and meaningful.
With this approach, we’ve moved from flashy demos to real, dependable value. Users get integration flows they can trust, and the AI’s capabilities translate into tangible outcomes. The exact leap from “built” to “beneficial” that most generative AI features never achieve.
For a closer look under the hood, check out these deeper dives:
- Technical Guide to Einstein for Anypoint Code Builder: Generative Flows
- DataWeave Generative Transformation Deep Dive: AI Innovation for Rapid Data Transformation
Curating a diverse evaluation set for reliable AI
Building AI that consistently delivers value requires high-quality outputs and rigorous evaluation. For our generative integration flows, this starts with a carefully curated evaluation set designed to reflect the full diversity of real-world use cases.
We begin by leveraging proprietary internal data, scraping examples from past projects and exploring a variety of sources. With over 7,000 connector operations in our Generative Flows feature, the dataset captures a broad spectrum of scenarios.
Next, we focus on data processing and filtering. Only high-quality flow code snippets that meet predefined criteria are retained, duplicates are removed, and each snippet is validated through our IDE-integrated validator to ensure correctness and compatibility. Sensitive data is handled with care, combining automated PII detection with human review.
To streamline labeling, we leverage our LLM to generate prompts for flow code snippets, tackling the challenge of establishing ground truth while drastically reducing manual effort. We then iteratively refine prompts using the LLM, guided by our LLM Judge correctness evaluator, to ensure that each prompt both reflects the flow’s functionality and conveys the user’s true intent.
Finally, a comprehensive evaluation set of approximately 840 flows is created using strategically weighted sampling based on connector popularity and usage frequency. This set is used to rigorously assess the performance of our pipeline development. This data-driven approach ensures that our AI is not only technically capable but also consistently reliable across diverse, real-world workflows.
Pipeline performance and quality gains
To highlight the effectiveness of our quality-first approach, we compared the performance of our pipeline to baseline LLM calls across nine widely used large language models on our carefully curated evaluation set. Performance is measured using two key metrics:
- Validity: Ensuring flows use correct syntax and supported operations, guaranteeing full compatibility and functionality within the MuleSoft ecosystem through our IDE-integrated validator.
- Correctness: Ensuring flows include all required components in the proper order and fully satisfy the user’s business logic and intent, evaluated using our well-curated LLM judge evaluator.
In the baseline approach, user prompts with simple instructions are sent directly to the model, followed by post-processing and validation. Our pipeline, by contrast, enriches prompts through retrieval and grounding and applies parallel error correction, significantly improving output quality.
Across multiple models, our quality-first pipeline consistently outperforms the baseline LLM pipeline. On average, it achieves ~90% validity and ~80% correctness, compared to only ~20% validity and ~17% correctness for baseline calls. With advanced models like GPT-4.1 and GPT-5, performance climbs even higher, exceeding 95% validity and reaching over 90% correctness.

Using the same model, our pipeline reliably delivers high-quality flows that are both valid and correct. In contrast, the baseline LLM pipeline often generates outputs that look plausible on the surface but break down due to syntax errors, incompatible operations, or missing business logic. The chart below highlights the quality gains achieved when moving from the baseline LLM pipeline to our MuleSoft AI quality pipeline.

Performance metrics collected from the production environment closely align with those obtained during experimentation on our curated evaluation set. This consistency underscores the robustness of our methodology, the representativeness of our evaluation design, and the reliability of translating experimental findings into real-world outcomes.
By integrating grounding, validation, and error correction alongside an LLM-based correctness evaluator, our MuleSoft AI quality pipeline transforms AI-generated integration flows from flashy demos into dependable, production-ready solutions that users can trust.
In the end
Launching generative AI features is only the first step; bridging the gap from “built” to “beneficial” is what creates real impact. Across emails, workflows, integration flows, and beyond, organizations often struggle to turn AI capabilities into trusted, reliable outcomes.
We’ve demonstrated that a quality-first approach consisting of grounding, validation, error correction, and rigorous evaluation can transform AI features from flashy demos into tangible value. By focusing on both validity and correctness, businesses can ensure their AI not only works but truly delivers on its promise, closing the AI value gap and driving measurable results.


