
Francis Edwards, Integration Analyst at Saint-Gobain and MuleSoft Ambassador, is an experienced MuleSoft developer. He spoke at MuleSoft CONNECT:Now EMEA sharing useful integration tools to help developers get the most out of Anypoint Studio. Below, he provides insight into each tool he recommends as well as demonstrates how he created a Mule app.
A large part of my work is frequently producing a variety of APIs for Saint-Gobain as it’s vital to managing retail and B2B sales/deliveries. As such, it has been important for me to find ways to simplify and improve how I work with Anypoint Studio. In this blog, I will discuss a few of the additional tools I have incorporated into my daily work with Anypoint Studio for API development. Specifically, I will discuss how to use an online tool for regular expression testing, negative lookups, and filename selection. Furthermore, I will look at formatting test data and validating it outside of Anypoint Studio using Notepad++ and how to handle large files.
Tools for large file handling to sort data
When I first came to Saint-Gobain, I found there were a number of issues with their file selection and testing. For example, several end points produced a multitude of files with single pickups — meaning they picked up all of the files at once. This caused problems in downstream flows as huge choice blocks were required to handle a multitude of business cases and further processing, each with different service level agreements. Case sensitivity was also a problem as people rarely followed file conventions, which may get missed by automated processing.
To solve this issue, I separated different business processes into different flows with attribute properties geared to the individual needs of the differing files picked up and processed. Regular expressions to select specific filenames and file type groupings were needed to enable each flow to have an inbound pickup that selected only the files required. It also needed to be robust enough to handle case insensitivity. There are various online regular expression testers, but one that matches the Mule regular expression libraries is regexterster.com. Any expressions that work here, work within MuleSoft connectors, this includes those that negate file selection.
Testing regular expressions with regextester.com
To use regextester.com, open the website and ensure the flags are enabled (ignoring case, global, and multiline). This reflects how the Mule file selector works within the Mule libraries.
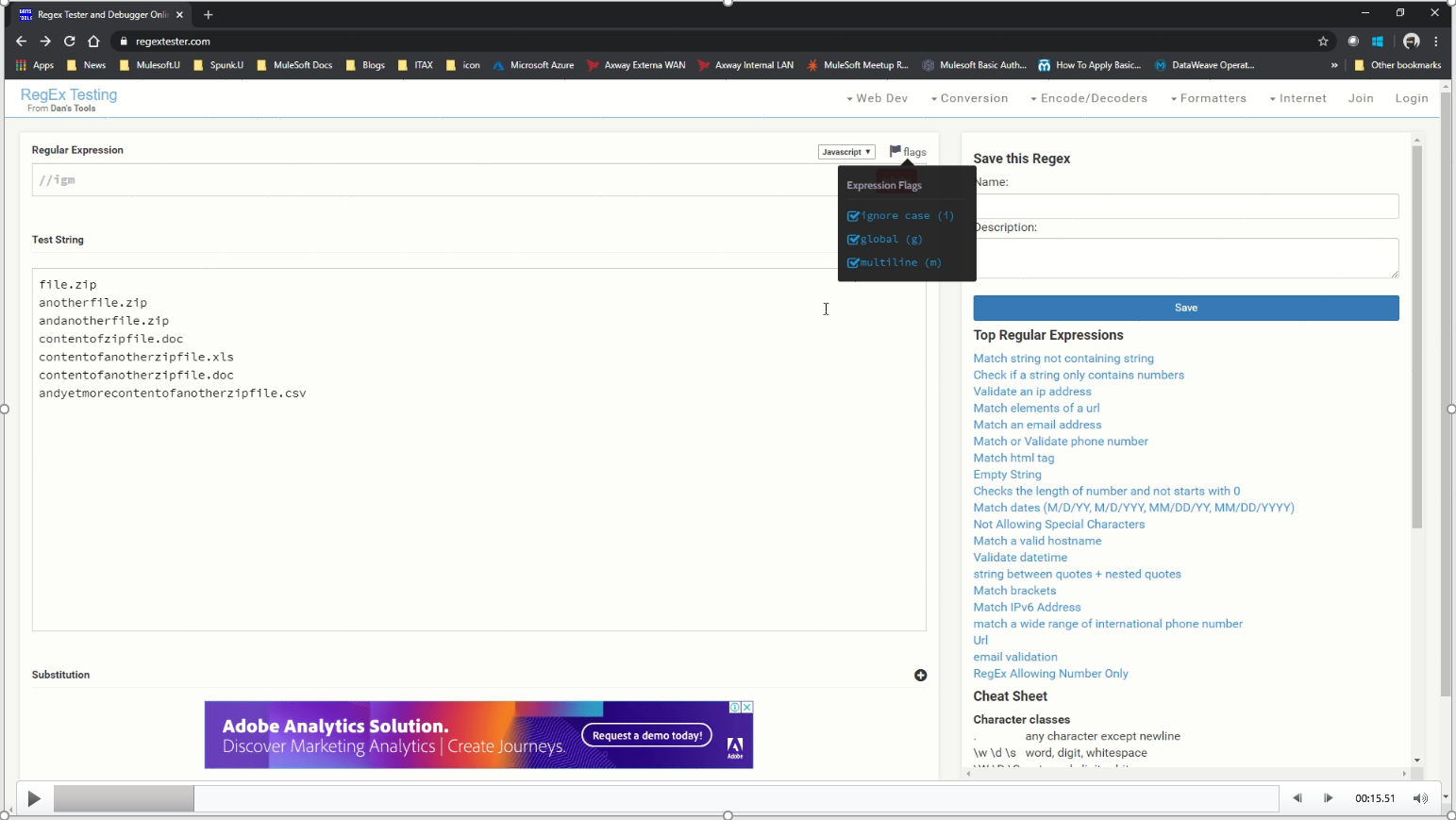
Within the Test Strings, I list a number of file names and types that I expect to find in the inbound endpoint. Included are a list of zip files that I want my first regular expression to check for, as well as a number of document and spreadsheet files that I expect to find within the content of those same zip files.
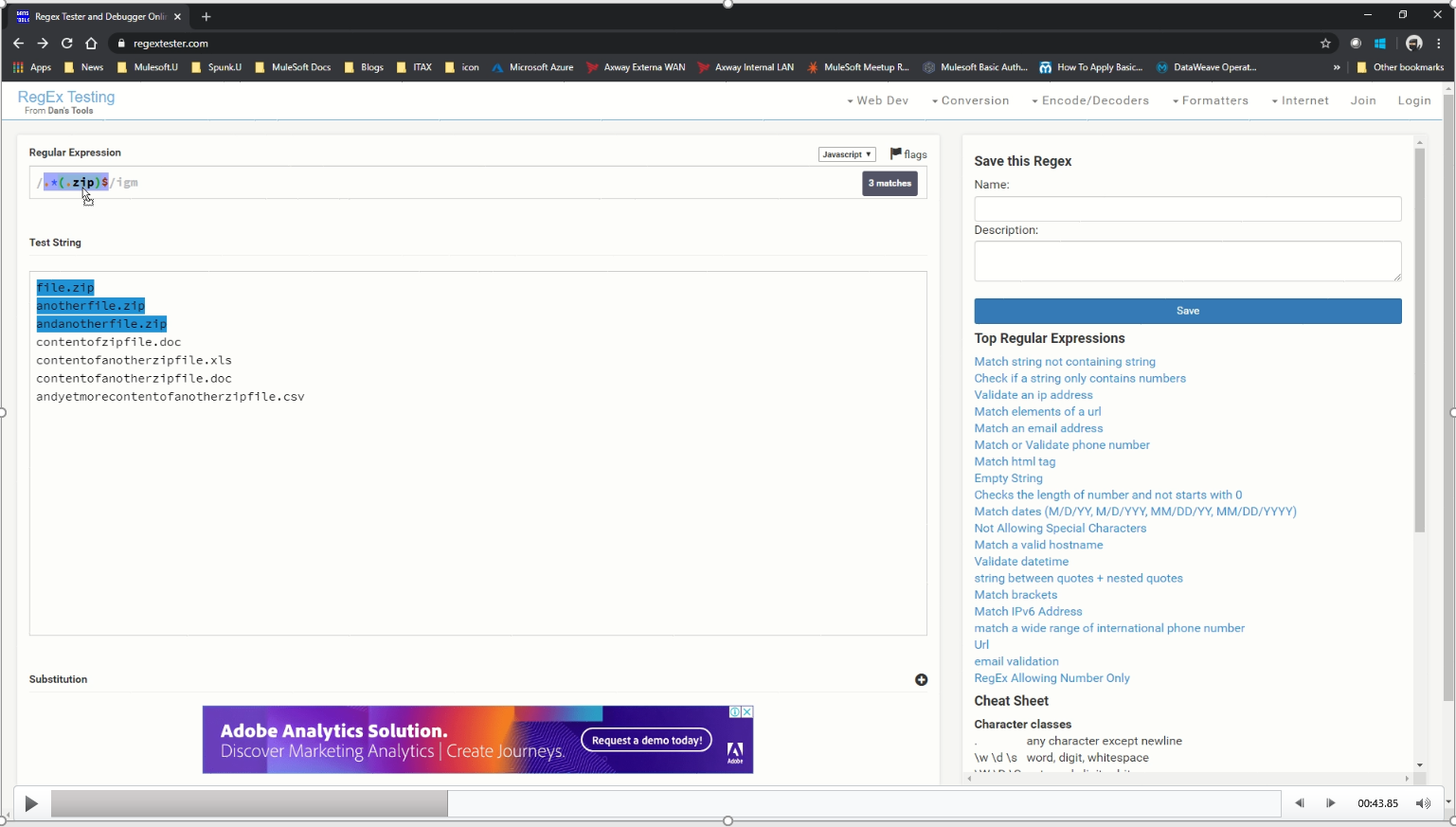
Then I enter the first regular expression searching for wildcards initially with a (.zip) suffix anchored to the end of the line. This allows me to select just the zip files and nothing else.
Secondly, I expand on this zip anchor and add a negative lookup. This ensures that I ignore any zip files and only select everything and anything else. In my example Mule app, I demonstrate the use of file pickups that contain a file name filter using the regular expressions to handle the processing of zip files and their nonzip file contents when collected from the same endpoint.
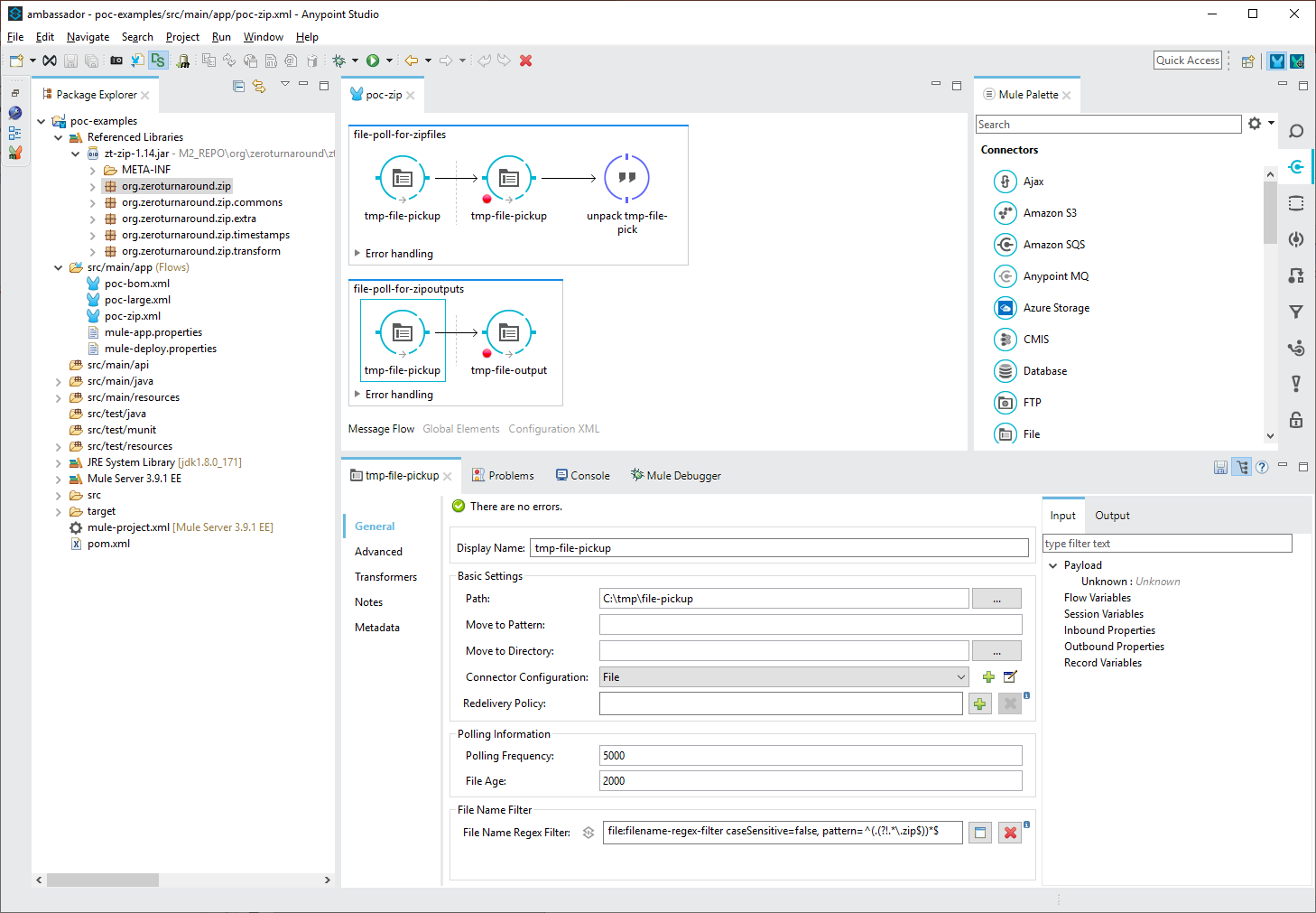
In the above configuration file, the first flow (file-poll-for-zipfiles) picks up files that have filenames conforming to the regular expression”.*(.zip).” This file is then written back into the same location with a known filename “zipfile.zip.” The subsequent transformer calls a Java expression to unpack the zip file contents of the known file which are expanded into the same location and the original file is deleted. The output file or files which do not have filenames ending in “.zip” are then picked up by the second flow (file-poll-for-zipoutputs), which uses the regular expression “^(.(?!.*.zip$))*$.” These files can then continue to subsequent processing, in this case output as a file to a different location.
Using Notepad++
A second issue was validating, formatting, and making test input easier to read or to match DataWeave inputs and outputs. I use Notepad++ to solve these issues. It allows me to identify mistakes and offers plugins for looking at Xpath statements and working out what data I need to select. This tool allows me to check data first before inputting it into MuleSoft and helps validate or invalidate data for the purpose of testing MuleSoft flows.
When using XML data as inputs in DataWeave scripts, it is useful to have it validated prior to being used, and for it to be formatted so that transformations can be easily cross referenced.
In this example of linearized XML, it is hard to know if the XML is valid.
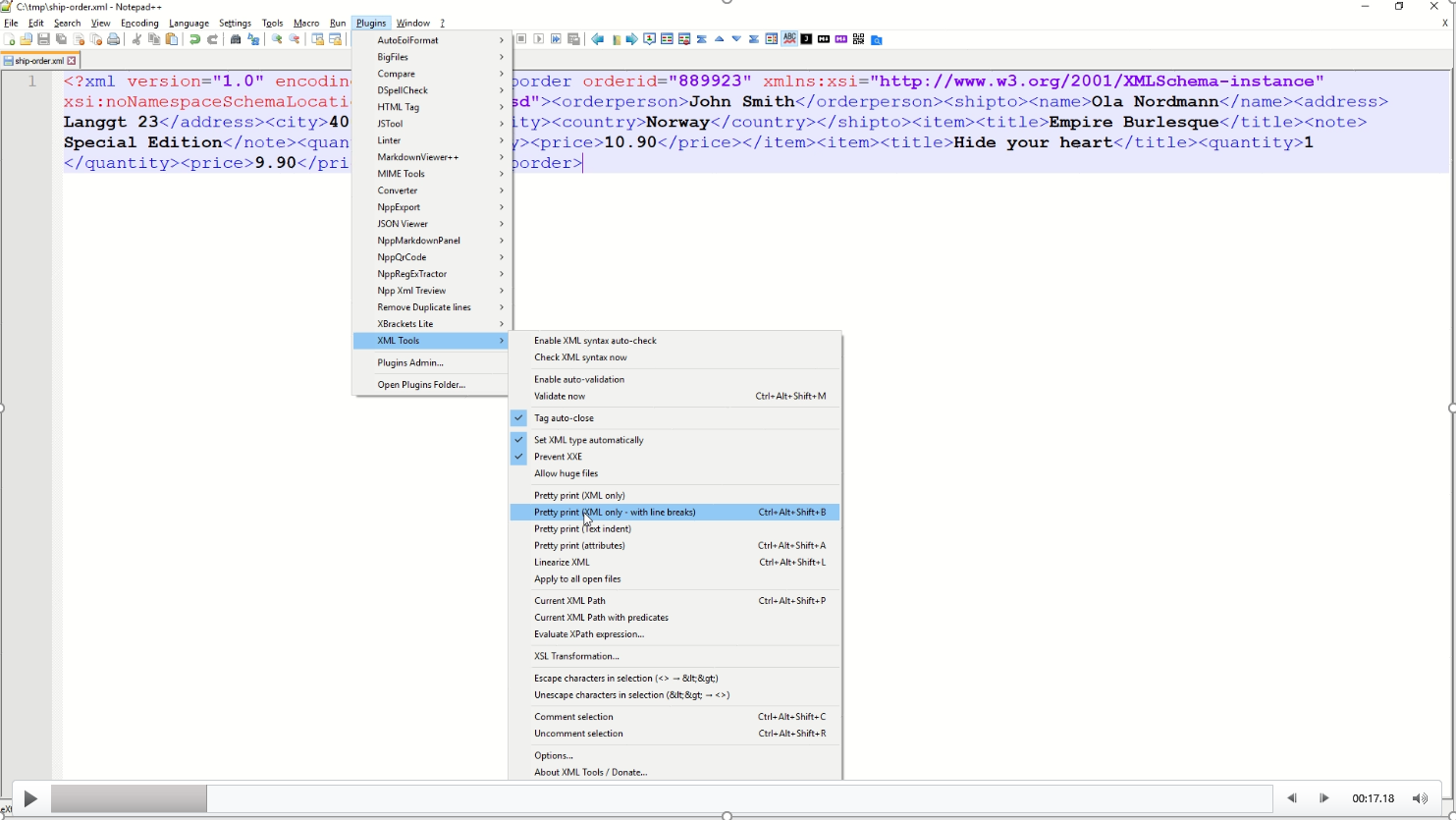
By using the XML Tools Pretty print plugin, the XML can be formatted to something more easily read.
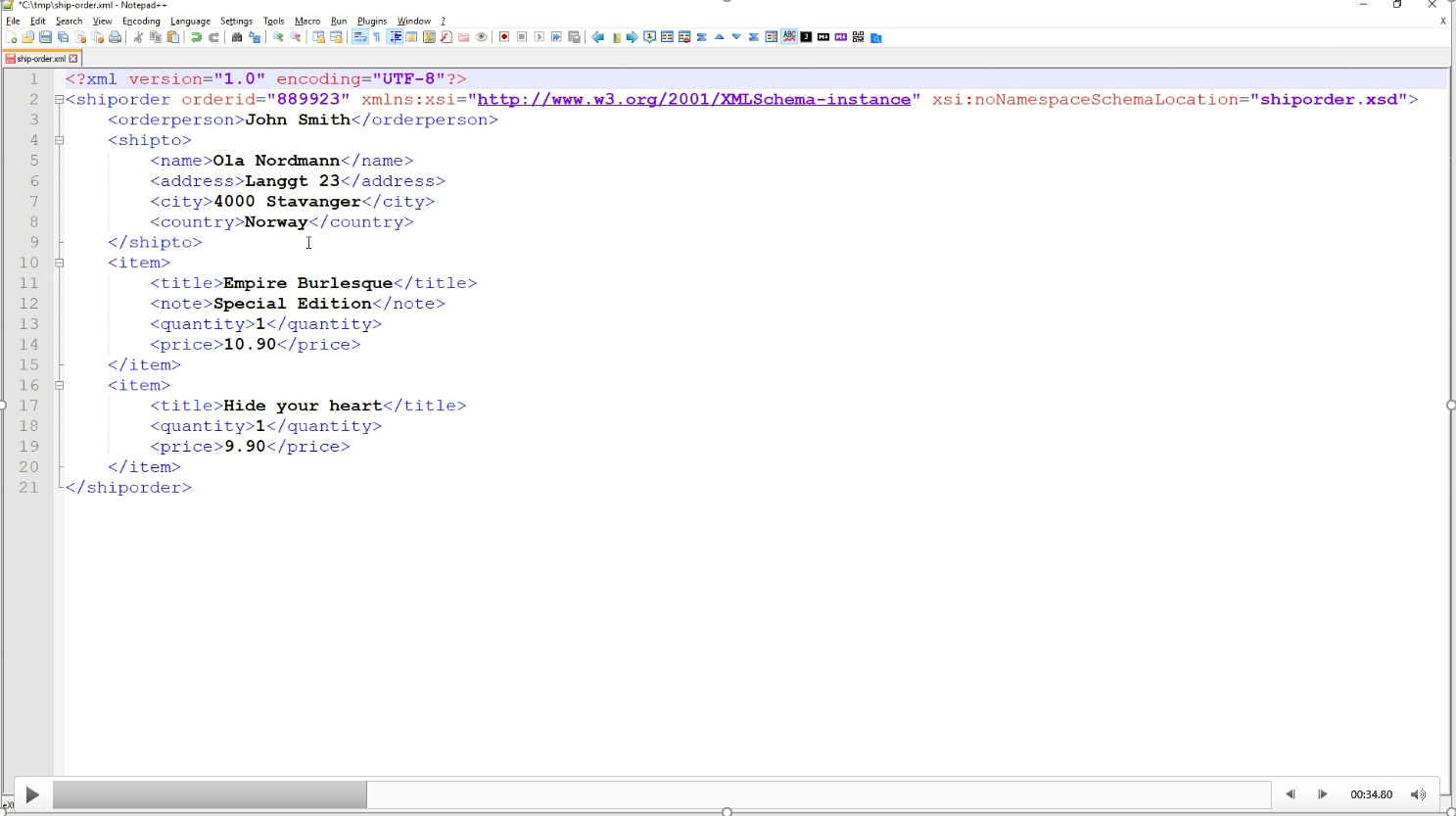
I can go one step further and use the same plugin to validate the XML against the referenced schema in the shiporder.xsd.
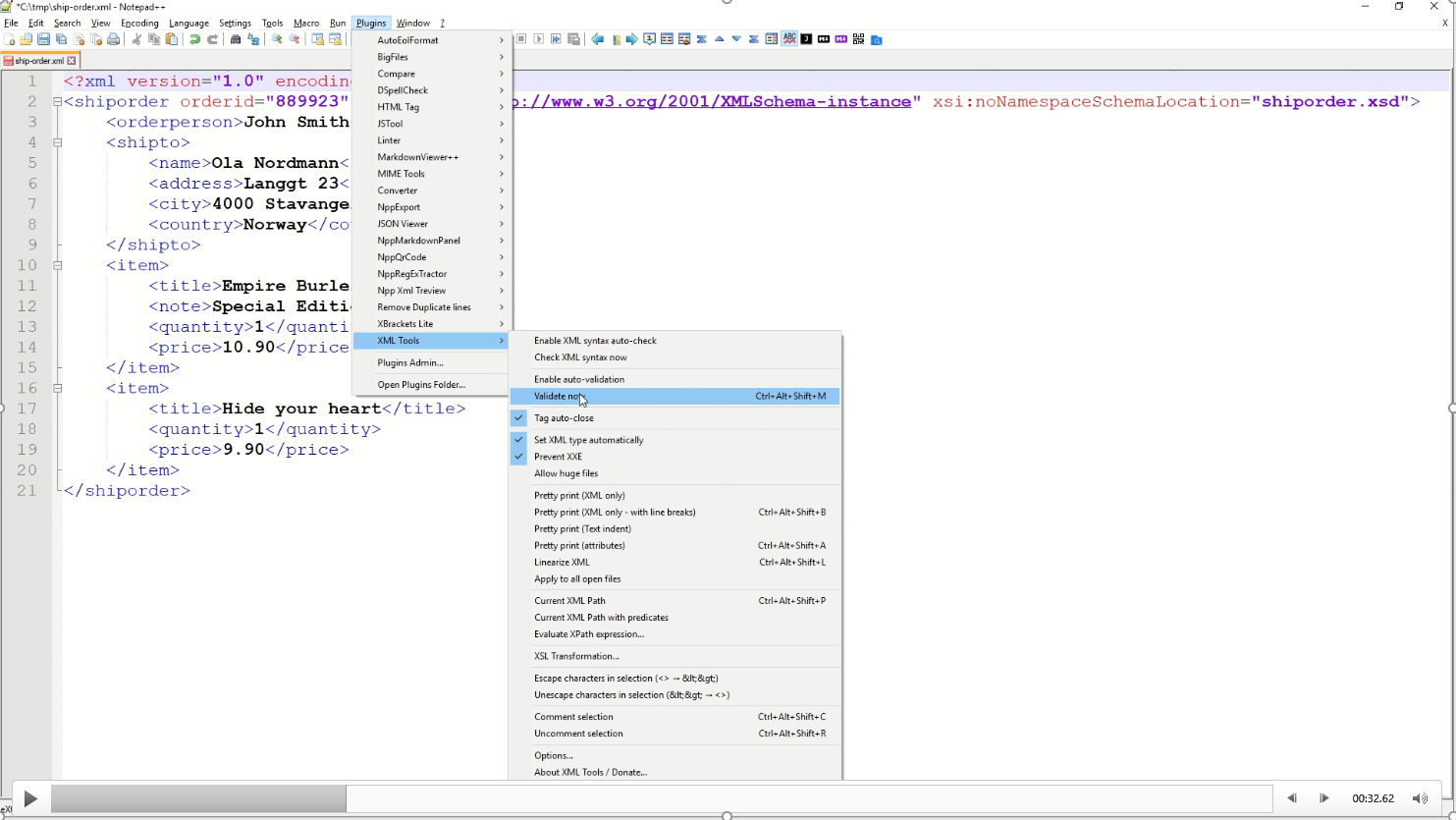
Another useful feature of Notepad++ is to see whether a file includes a Byte Order Mark (BOM), this can be viewed in the bottom right corner and can be converted using the Encoding menu item. DataWeave scripts, that handle XML input that has been converted to a string prior to processing, can cause errors and should be handled to strip the BOM from the message before any transformation.
In my example Mule app, I demonstrate the Mule transformers that Notepad++ mimics to show how a Mule app can be used to replicate the Notepad++ functionality, or conversely the Mule functionality for which Notepad++ can be used to produce the test data.
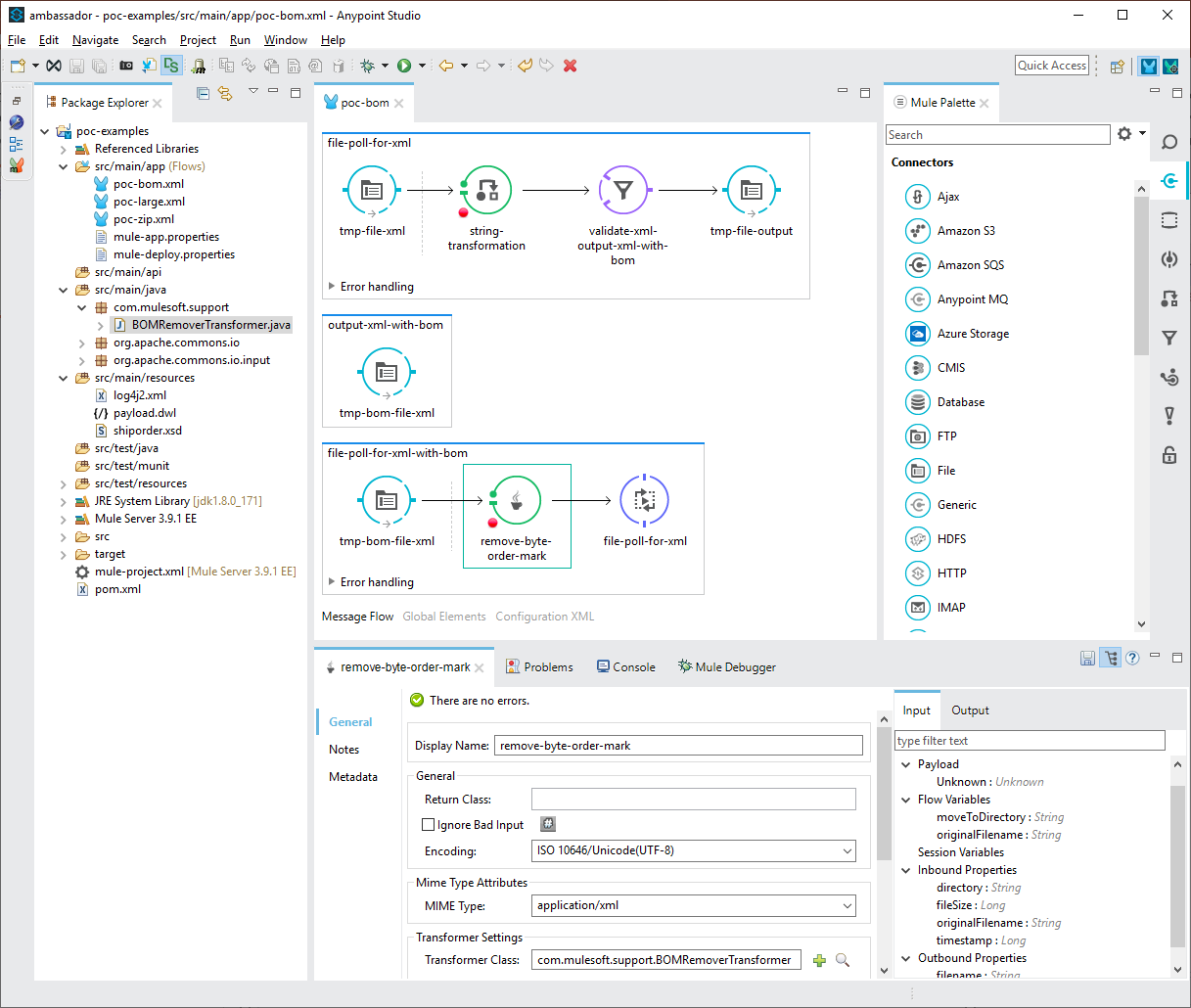
In the above configuration file, the first flow (file-poll-for-xml) picks up files and uses a Mule transformer to convert the payload to a string. Should the file have a BOM in the encoded data, it would fail both the validation module or subsequent transforms, so I used the validation filter to test the XML schema. If it fails, the message is passed to a second sub-flow which outputs the file to a second pickup location. The file is then picked up from the second location by the third flow (file-poll-for-bomfile) and a java transformer is used to remove the BOM from the message which is then redirected to the first flow. The second attempt to pass the validation module is subsequently successful and the message can continue to subsequent processing by the first flow.
Uning Emeditor
Finally, much of my data handling includes large files of up to 2Gb which may require transformations and streaming. Issues with big data include character encoding mismatches or special/escape characters within the data. Being able to search and sort data to work out field lengths and types, find misalignments because of problem delimiters or rouge data / characters can make debugging hard. For this, I use Emeditor, an editor that specializes in handling massive files. This enables me to easily sort columns of data, finding, or verifying that it conforms to the required specification and allowing me to clean or know how to handle it in DataWeave transformations where ‘replace’ or ‘when’ functions can be used to prevent exceptions.
Simply put, Emeditor is the only tool I can use to open large files, check for encoding type, and check whether there are any invalid characters contained within. I can search using regular expressions which is useful for finding special characters and unicode characters within potential ASCII data. Once I’m sure the data is valid, I can check and change delimiters and sort data by columns looking for useful min and max entries such as longest, shortest, A to Z, etc. This helps to describe the data when I’m writing RAML or creating schemas to describe the data types for the data contained.
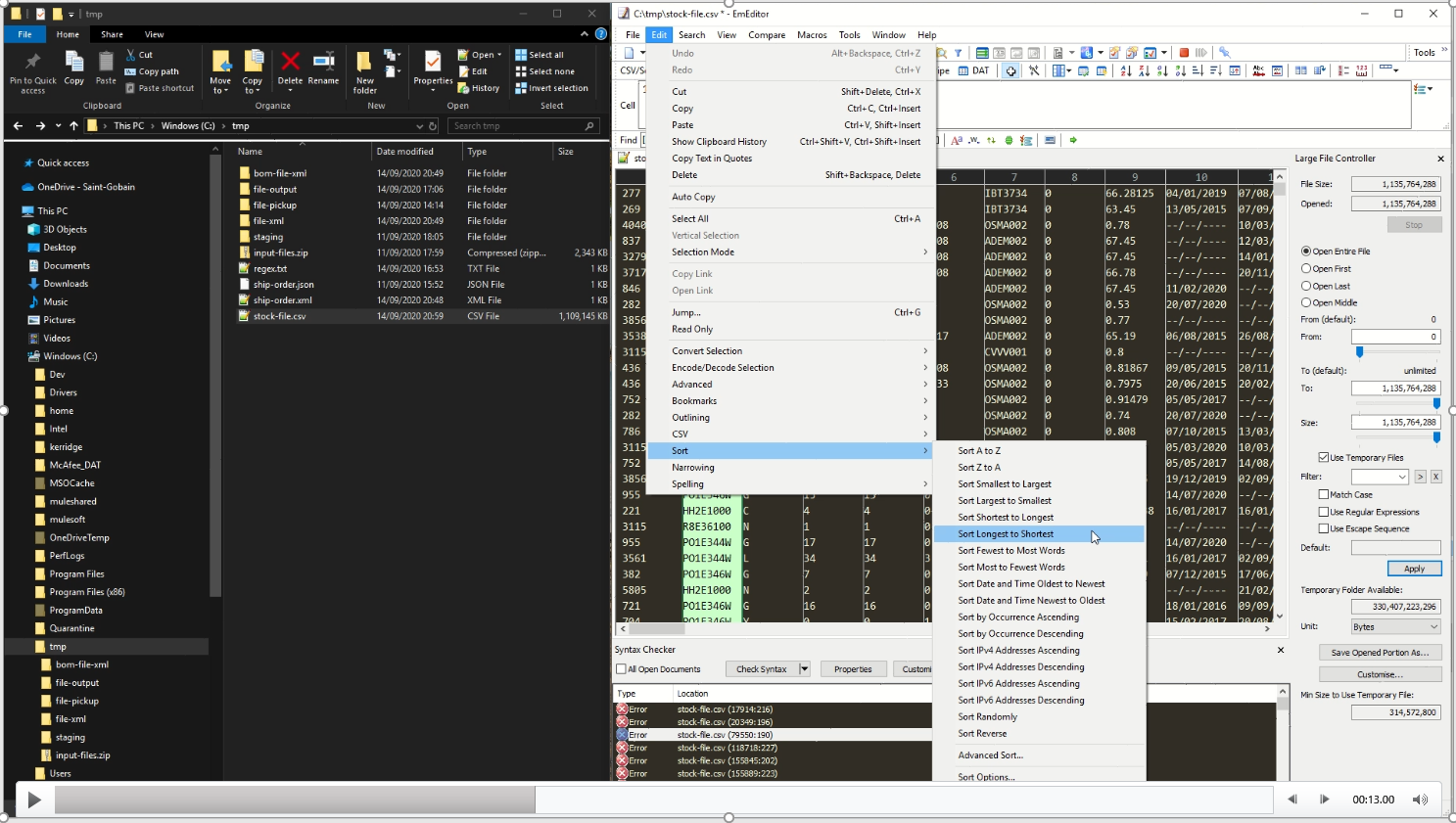
It also finds edge cases for the data or known discrepancies enabling me to include them as handled cases when writing DataWeave. In the picture below, you can see where I’m choosing a description field from the data, except when the field length is above a certain amount, where a secondary column is chosen to be returned.
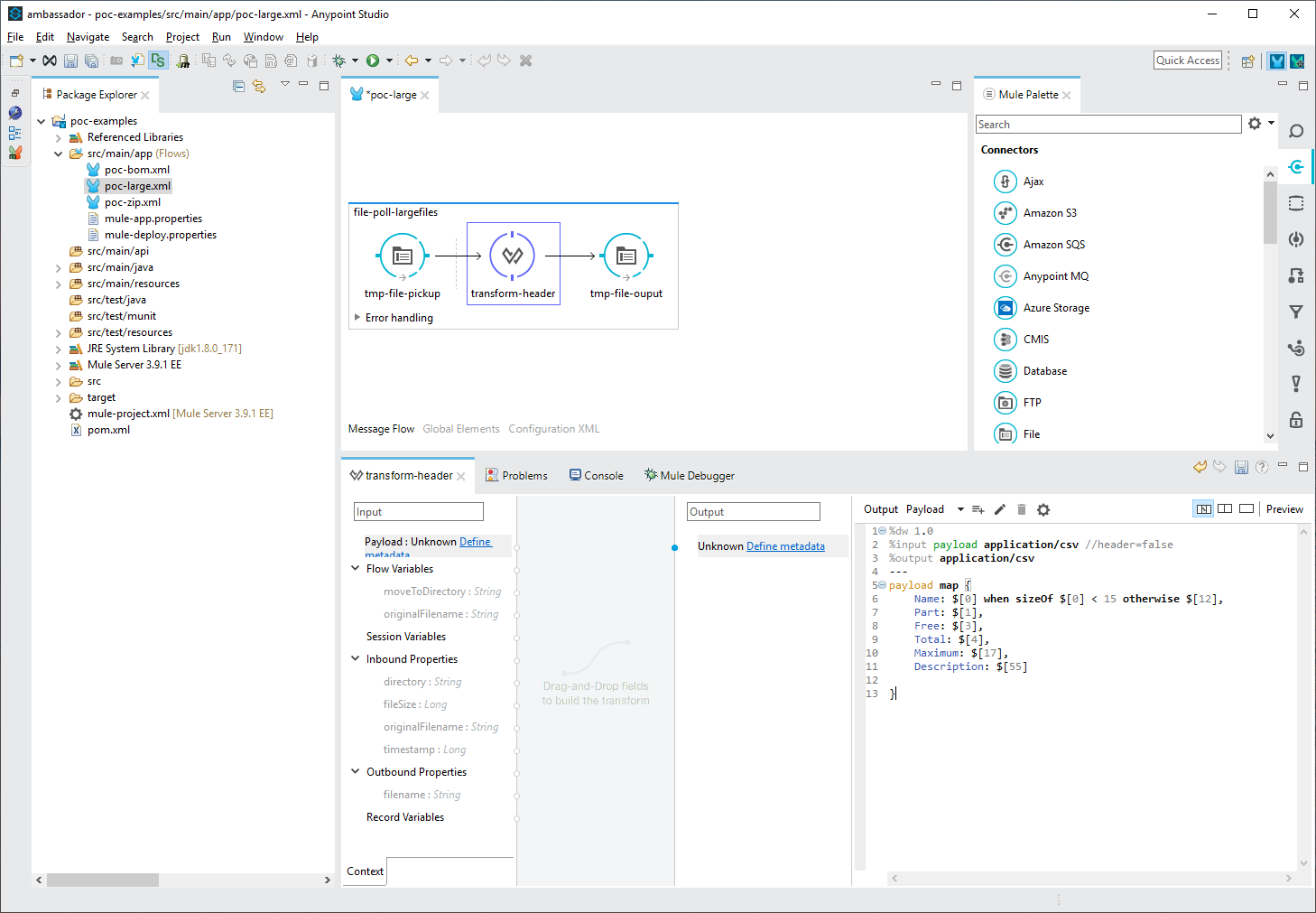
So, what are the benefits?
In summary, the benefits of adding these external tools to your use of Anypoint Studio are numerous. It allows you to:
- Manipulate data to ensure valid and invalid data to aid testing and exception handling.
- Test regular expressions against array of required/not required strings.
- Byte Order Marks removal, particularly for XML strings ensure correct processing.
- Ensures that delimiters independent of the real data can be specified.
Most importantly, these tools compliment Anypoint Studio, allowing quicker Mule app development. My advice is to know all the tools you can use to test and clean data, spotting likely errors to be handled, as this is the foundation that mature Mule apps are built upon.
If you have any questions, reach out to me on LinkedIn or during a West Yorkshire MuleSoft Meetup. You can also find more technical discussions such as this during one of our upcoming MuleSoft Meetups. Register for a virtual local or global event today.



