
In this blog, we’ll look at how a regular expression (regex) can give you the power to transform text in your DataWeave programming. When you need to select, replace, remove, or transform text, you can define a regex pattern to define what you want to match, and perhaps one that defines what you’d like to provide as a substitute.
The technique is nearly as old as Unix, but we still use it regularly because it works. You could use it to identify text fields in data that contain malformed information. You could use it to transform text in your data so that it always appears in a canonical form. Or you might use a regular expression to define a text pattern you’d like to identify and extract (such as a hashtag or an email address).
In DataWeave, the core library offers us a host of functions that accept properly formed regex as an argument — you’ll see a few of them in this article.
What you’ll learn
During the exploration, you’ll see how to do the following things:
- Use regular expressions to transform a plain text collection of quotations into a structured data set.
- Use Anypoint Studio to iteratively observe the effects of changes to your regular expression.
- Use a variety of useful functions from the DataWeave core library (eg. replace() with() splitBy() map() ++() ).
In the first section, we’ll take a plain text collection of quotations from a variety of sources. We transform this plain text into a structured set of quotations by parsing the data with regular expressions. We’ll look at some variations and see the effect of each.
In the second section, we’ll expand our approach by considering various sources of the data, and implications we might have to consider if we do not control the source of the data. As well as how to account for cross-platform variances in the presentation of text data.
We strongly recommend that you follow along on your own system as you explore this topic. To do that, you will need a couple of things:
- Anypoint Studio (version 7.5.0 or greater – download here)
- The input file of quotations (download from GitHub here)
- The starter project download
The basics of regular expressions
If this is your first time working with regular expressions — you’ll need to understand a few fundamentals.
When you search for a text pattern using a regular expression, there are tools that act in the same way. You have certain symbols (we call them metacharacters) and that represents something other than their literal meaning. Here are a few that we use all the time:

With these tools within your regex workbench, you can get a long way with your own pattern-matching expression. We may call any of these characters an “atom” of the regular expression. For that matter, a simple literal character (such as “A” or “9”) is also an atom. You may use parentheses to encapsulate part of your expression. It will then become an atom that can be modified or referenced later.
There are several metacharacters in a regular expression that have no meaning by themselves. They merely quantify another metacharacter or atom of your expression. We call them “quantifiers.” Some common metacharacters in this family are:

There’s one more thing we’ll need in our toolkit to handle variations in the input data: “zero-width assertions.” What that means is that the atoms of your regular expression occupy no actual space in the target buffer. It is common for these to be called “anchor characters.”
Think about the idea of a symbol that means “beginning of the line,” or “end of line,” or “end of word.” These atoms can anchor our expression to a boundary or other characteristic of the input text. We’ll take a closer look at this later in this article.
Here are some of the “anchor characters” or “zero-width assertions” that we might use:

By default, when an expression can match more than one substring in a buffer, it will select the longest substring, so long as the rest of the regex is still satisfied. We often simply say that regular expressions are naturally greedy.
Consider a few examples and see how these tools are combined. We start with some simple lines of text that can be easily understood at a glance. Here is our input:

Now, let’s see a couple of regular expressions that extract parts of the input text:

The parentheses in this example mark part of the overall expression for later reference as $[1]. If you have several “marked” portions of your expression, the subsequent portions will show up as $[2] and so on.
It helps to translate a regex into a spoken language to understand the meaning most. For example, you might state our third example above as “starting at the beginning of the input buffer, a series of one or more ‘not-digits.’” Or we might state the final example as: “a series of one or more digit characters, followed by a literal dash, then followed by another series of one or more digit characters which we shall remember as $[1].”
Preparation
Before we begin working with the DataWeave, we need to do a little bit of setup. If you master this phase, you’ll be able to code iteratively and quickly see your results.
We’ll launch Anypoint Studio and create an empty project (or download our starter project from here, and import it). Then we’ll place the data samples in the project source (put them in /src/main/resources) to make it easy to reference. You’ll place a transform message element into the project and use it to operate on various sized samples of the data. The next section describes how to do this.
The input
The data we’ll be using is in a file called quotes.txt. It’s a plain text file with many quotations, each separated by a blank line. (You can get the original source here).
Here’s an extract from the file:
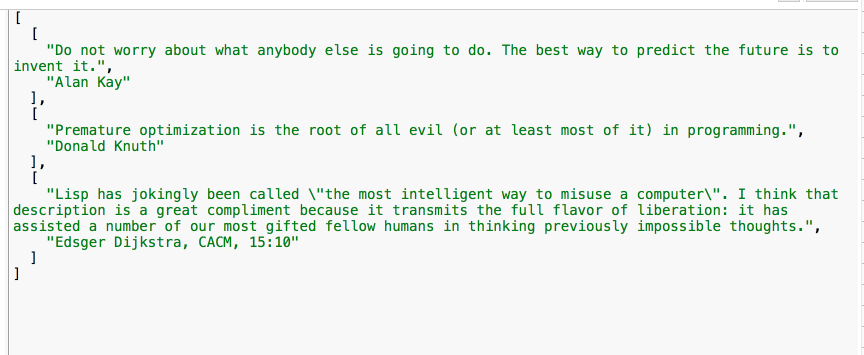
Do not worry about what anybody else is going to do. The best way to
predict the future is to invent it.
-- Alan Kay
Premature optimization is the root of all evil (or at least most of it) in programming.
-- Donald Knuth
Lisp has jokingly been called "the most intelligent way to misuse a
computer". I think that description is a great compliment because it
transmits the full flavor of liberation: it has assisted a number of our most gifted fellow humans in thinking previously impossible thoughts.
-- Edsger Dijkstra, CACM, 15:10The pattern we can identify is that each quotation is terminated by a newline, then a line that begins with two dashes. That subsequent line contains the author’s name, and then is terminated by two newline characters in a row.
The entire collection is fairly lengthy. As we prototype and develop, we’ll want to work with a small data replica. So we’ll create two shorter extracts to use for our testing. The section you see above, we’ll take that and simply add it directly into our DataWeave code, assigning it to a variable.
Next, we’ll take a short sample from the source file (about 10 quotations) and we can use that to test our approach against a filesystem hosted data set, but smaller than our full collection of records. We’ll call it “quotes-mini.txt.”
Since this is a learning project rather than production, we’ll simply place both the full quotation list, and the mini-version directly into: /src/main/resources. This way, we can read the file directly from our CLASSPATH later on.
First, we put a fragment of the file into our script directly as a sample in a variable. We open a fresh flow, bring in a fresh transform message element from the palette. Then, we set up our experiment to look like this:
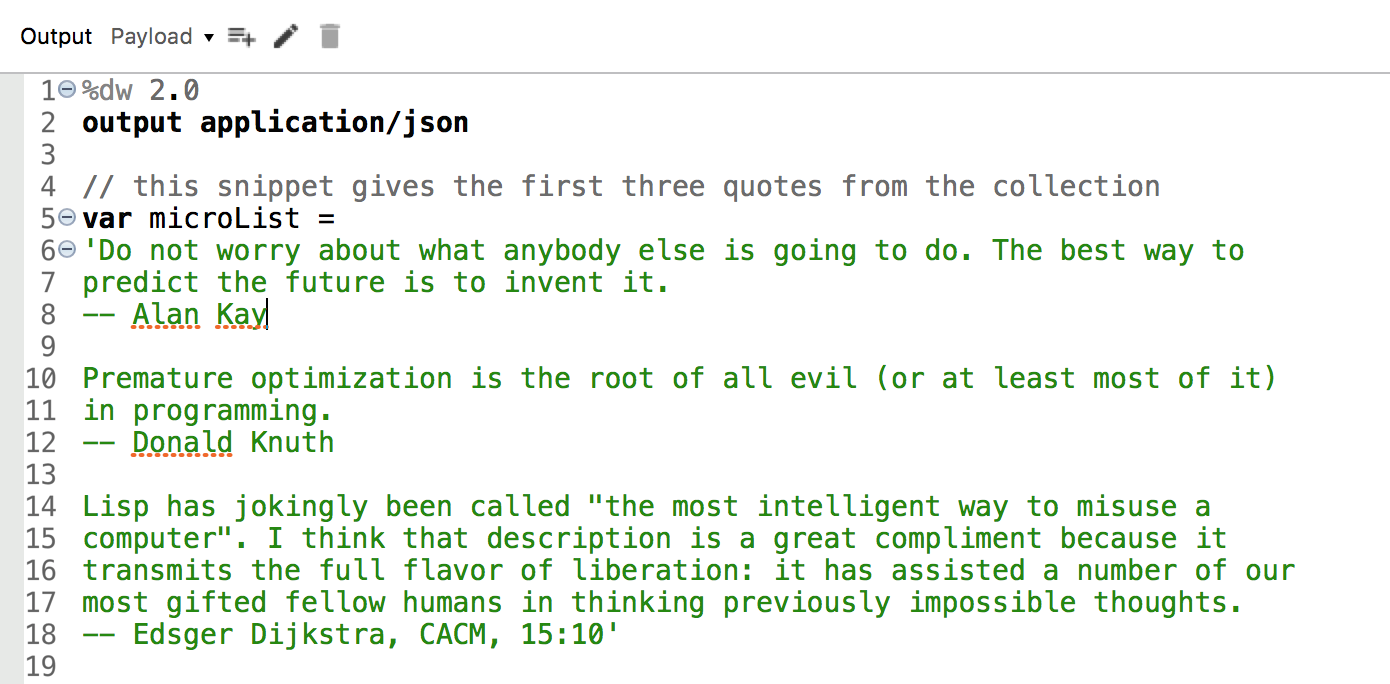
Break file into array (small data)
If we take a look at the preview presentation as seen in DataWeave, most of the quotes contain newline characters internally for readability. Let’s transform those to a simple space, and then we’ll have a text stream we can parse into individual elements.
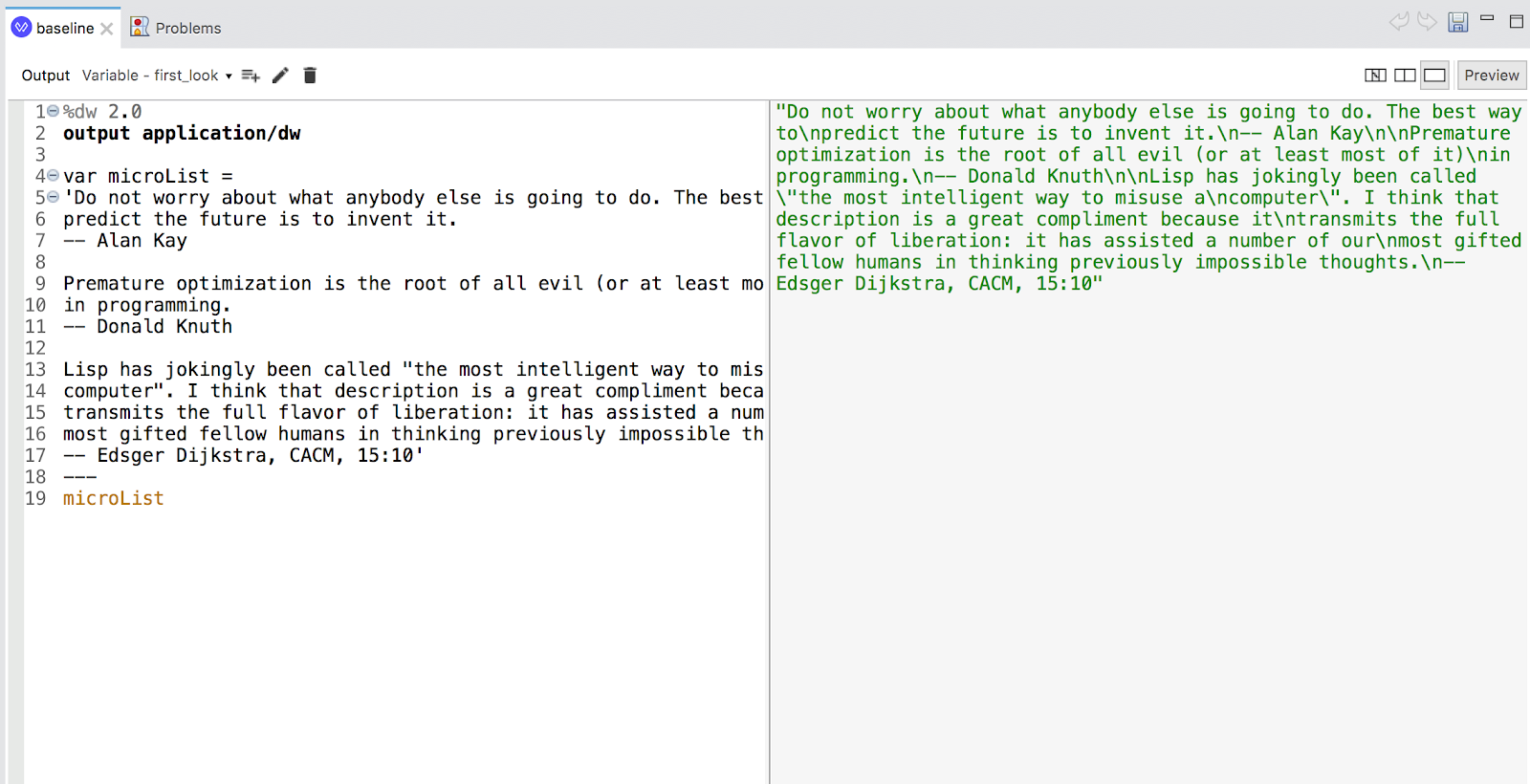
In particular, these portions interest us:
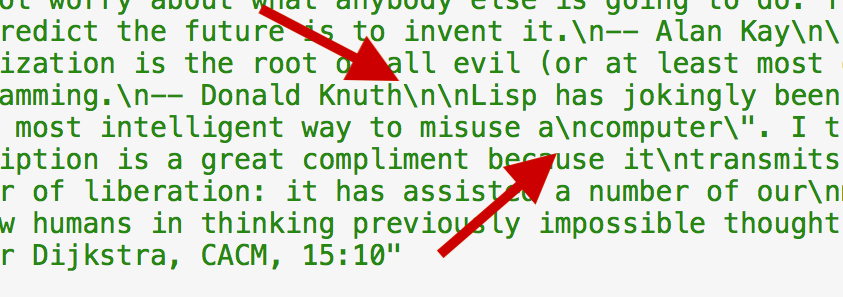
The pattern that delimits our “record” is two newline characters in a row. If we encounter a single newline character surrounded on both sides by a non-whitespace character, we can convert it to a simple space. This then, will be our first step in the transformation.
To do this in DataWeave, we’ll use the replace() function and the with() companion function.
Here is the expression we can use with replace() to make the transformation.
microList replace /([^n])n([^n])/ with ($[1] ++ " " ++ $[2]) So how do you do this?
Identify a pattern that consists of a not-newline character, followed by a newline character, then followed by a not-newline character. Remember the first not-newline character as $[1], Remember the second not-newline as $[2] – because parentheses. Now, replace the entire matched pattern with just $[1] and $[2] separated by a space.
Meanwhile, here’s what we get:
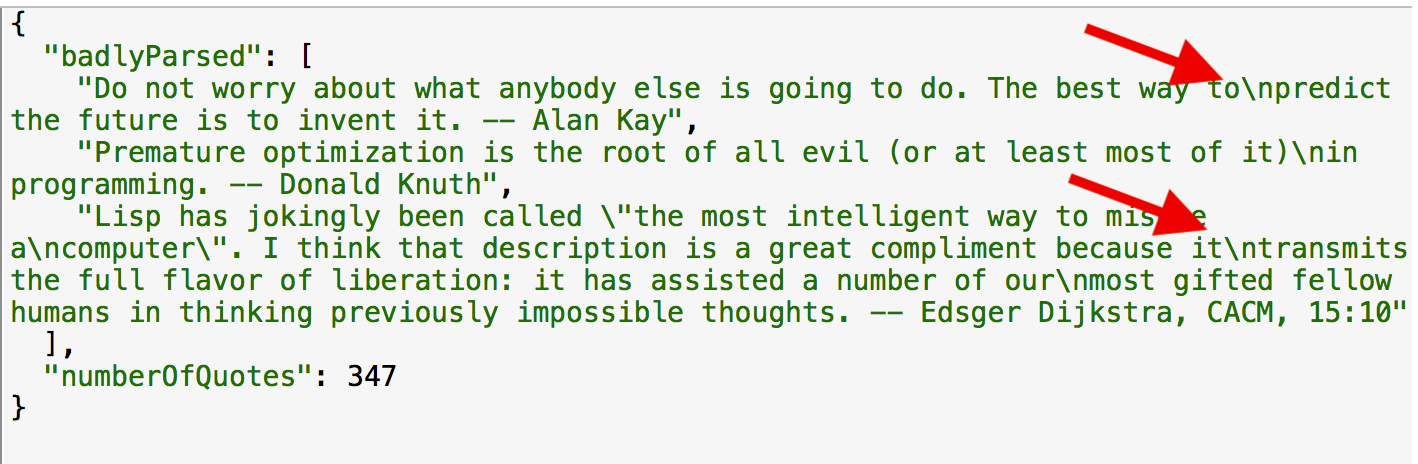
Modify to handle line endings
The challenge now is that there are still some embedded newline characters in the individual quotes. Now, we have a single string that consists of multiple individual quotations. We’ll need to break the string into discrete quotation elements. We’ll add the split() function and give it a regular expression pattern as its argument.
microList replace /([^n])n([^n])/ with ($[1] ++ " " ++ $[2])
splitBy /nn/This gives us a collection of quotation elements, and we can use map() to apply one last transformation to each element. Here’s what we say, and a look at the result.
microList replace /([^n])n([^n])/ with ($[1] ++ " " ++ $[2])
splitBy /nn/
map ($ splitBy / -- /)The addition here is this phrase:
/([^n])n([^n])/ with ($[1] ++ " " ++ $[2])We ask for any newline character that is surrounded by “not-newline” characters to be replaced with a simple space in place of the newline and we want to retain the original “not-newline” characters
The map() function executes and gives us an array of arrays, each with a quotation and author as elements. It looks like this:
Note that we used a regex as the argument to splitBy() in both cases — notice how we encase the model string in / instead of quotes.
The data is in a rational form and we can now easily use DataWeave to transform it into the organization and presentation it needs to have in the end. Come back to our Forum and tell us what you did from this starting point.
Final steps
So we’ve seen how to do a few important things in this article:
- How to set up data samples for rapid development. (using readUrl())
- How to use replace() and with() functions
- How to form Regular Expressions
Here are some next steps for you.
First, if this was your first good dance with regular expressions, we recommend that you spend some playground time at regex101. It really will pay off for you.
Second, if you didn’t download and follow along in the starter project, do that now. The sample project has other variations and insights available.
Third, register yourself into the excellent course, Anypoint Platform Development: DataWeave. There, you’ll get a chance to explore advanced practices that make your code more effective, more performant, and in many cases much more concise.



