
MuleSoft provides a batch job scope for processing messages in batches. This component is being used for various extract, transform, and load (ETL) processes. We’ll help you learn how to define batch processing, batch block size, and discover what happens to batches when they move between batch steps.
What is batch processing?
Batch processing is the processing of application programs and their data separately, with one being completed before the next is started. It is a planned processing procedure typically used for purposes such as preparing payrolls and maintaining inventory records.
Within an application, you can initiate a batch job scope, which is a block of code that splits messages into individual records, performs actions upon each record, then reports on the results and potentially pushes the processed output to other systems or queues.
Batch job examples
- A telephone billing application that reads phone call records from the enterprise information systems and generates a monthly bill for each account
- ETL process for uploading data from a flat file (CSV) to Hadoop.
- Handling large quantities of incoming data from an API into a legacy system.
- A legacy system publishes a list of transactions as an hourly batch that is consumed by an ERP system.
Understanding a batch job
Batch processing in Mule is taken care of by a powerful scope i.e batch job scope. A batch job is a scope that splits large messages into records that Mule processes asynchronously. In the same way flows process messages, batch jobs process records.
A batch job comprises various batch steps that act upon records as they move through the batch job. Each batch step contains various processors that act upon the payload and pass the processed payload to next steps as per configuration. Batch steps have various functionalities to act upon the payload. Once all records passed through batch steps, batch job ends and a report is generated showing which records failed and which passed during processing.
3 core batch job phases
There are three phases in batch job processing:
- Load and dispatch
- Process
- On complete
For this content, we will focus on the process phase where actual processing of the payload/records happens in the batch job. In the process phase, records are pulled from the queue and blocks of records are created as per the batch block size defined for the batch job. This block of records passes through each batch step as per the configuration asynchronously. In each batch step, a block of records (i.e. batches) are processed in parallel; once one batch is completed, it’s pushed back to the queue for processing by the next step.
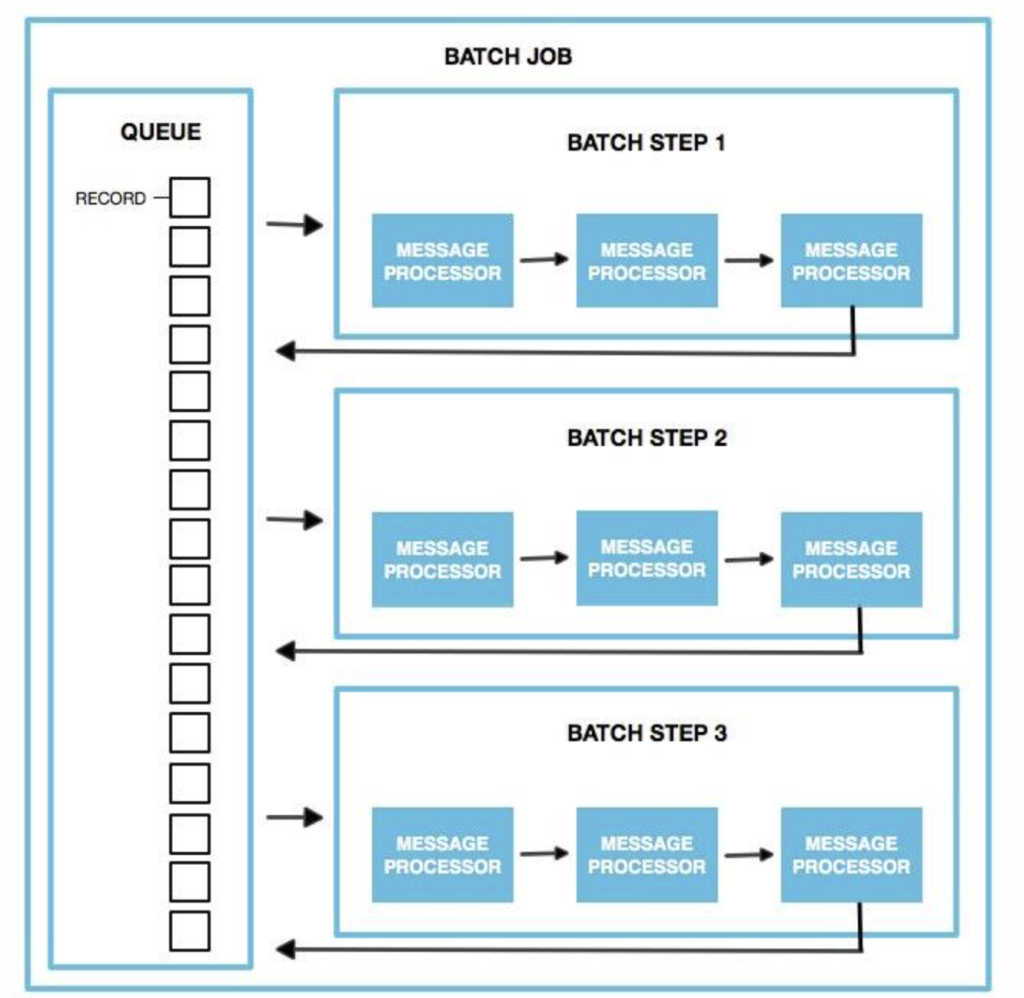
Records inside one batch block are processed sequentially inside the batch step.
We are passing an array of records as payload: [2, 3, 4, 5, 6, 7] and batch block size as three, meaning two blocks of records will get created. Let’s see how these blocks of records pass through each step.
In step one, wait is added for even numbers with some transformation, and in step two , records are passed as it is with some transformation.
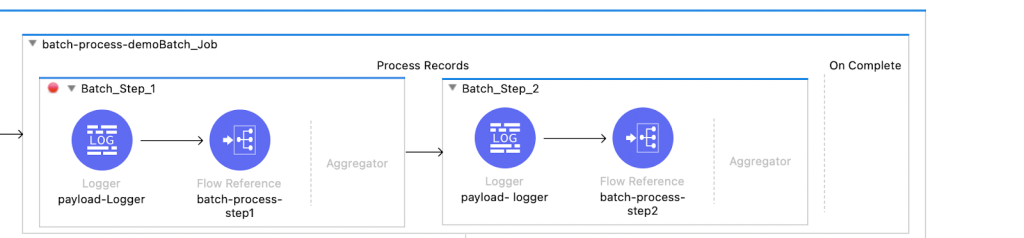
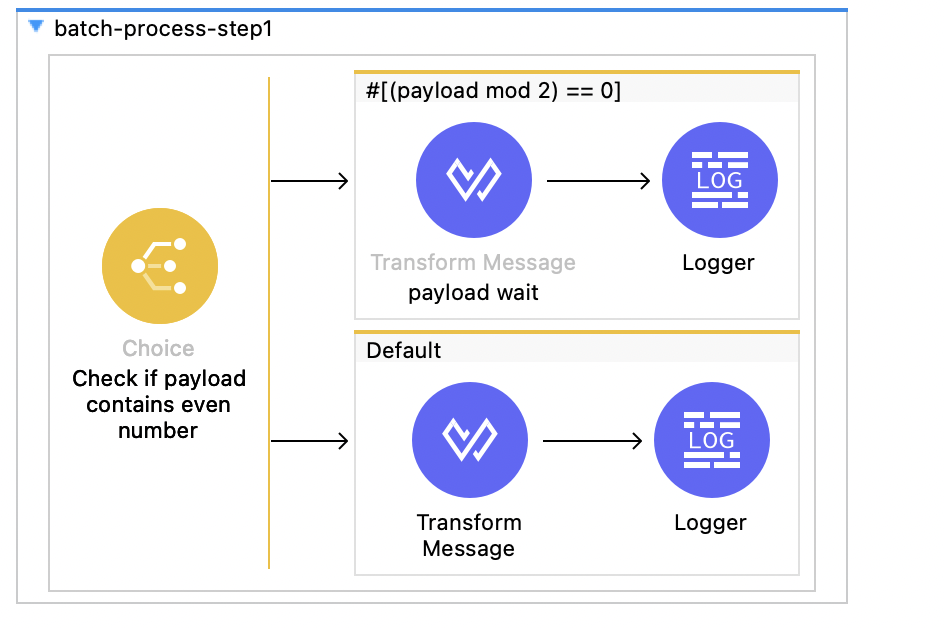
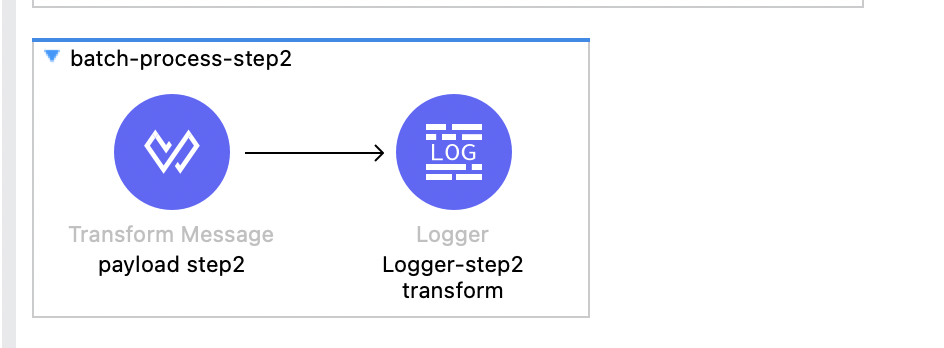
After running this flow with the array size of six and batch block size of three, we got two blocks of records as shown below.

Now suppose we have six records with batch block size three.

From the example above, we can infer how batch block size can impact performance of the batch job since it processes records sequentially. We only had six records of byte size but in actual ETL cases, we usually process millions of records with heavy XMLs/JSON files, so we should carefully set the batch block size considering heap memory in such a way that we don’t run out of memory as while processing the records, records get loaded in the memory.
To run your batch jobs with optimum performance, you must run comparative test cases with different values of batch block size and test the performance of each test before moving the code to production. A standard batch block size of 100 works for most of the use cases, but there may be scenarios where you are working with heavy or small payloads and changing this block size can give you better performance.
Here are a few scenarios:
- If you have millions of records with payload size in KBs, you can process blocks of a high number of records with no memory issues. Here, setting a larger block size improves the batch job time.
- If you need to process heavy payloads like files of larger size in MBs, then you can consider keeping the block size smaller to distribute the load and avoid memory issues.
Closing tips and further learning
Remember the following tips when dealing with batch processing:
- A lower batch block size will perform more I/O
- A higher batch block size will reduce the I/O, but eventually you will be processing more sequential records whenever you retrieve X amount of records from the queue, and X < block size.
Want to learn more? See also:



