
The Mule 4 Release Candidate is here and, with it, the updated version of the batch module!
The batch module was first introduced in Mule 3.5 and it aims to simplify integration use cases where basic ETL functionality is needed. If you’re unfamiliar with it, I recommend you look at this post before continuing. If you are already old friends with batch, then keep reading for a breakdown of all the changes!
Enter the Batch Scope
In Mule 3, batch was a top-level element, just like flows are. Now, the <batch:job> element is a scope which lives inside a flow––making it easier to understand, invoke dynamically, and interact with other Mule components.
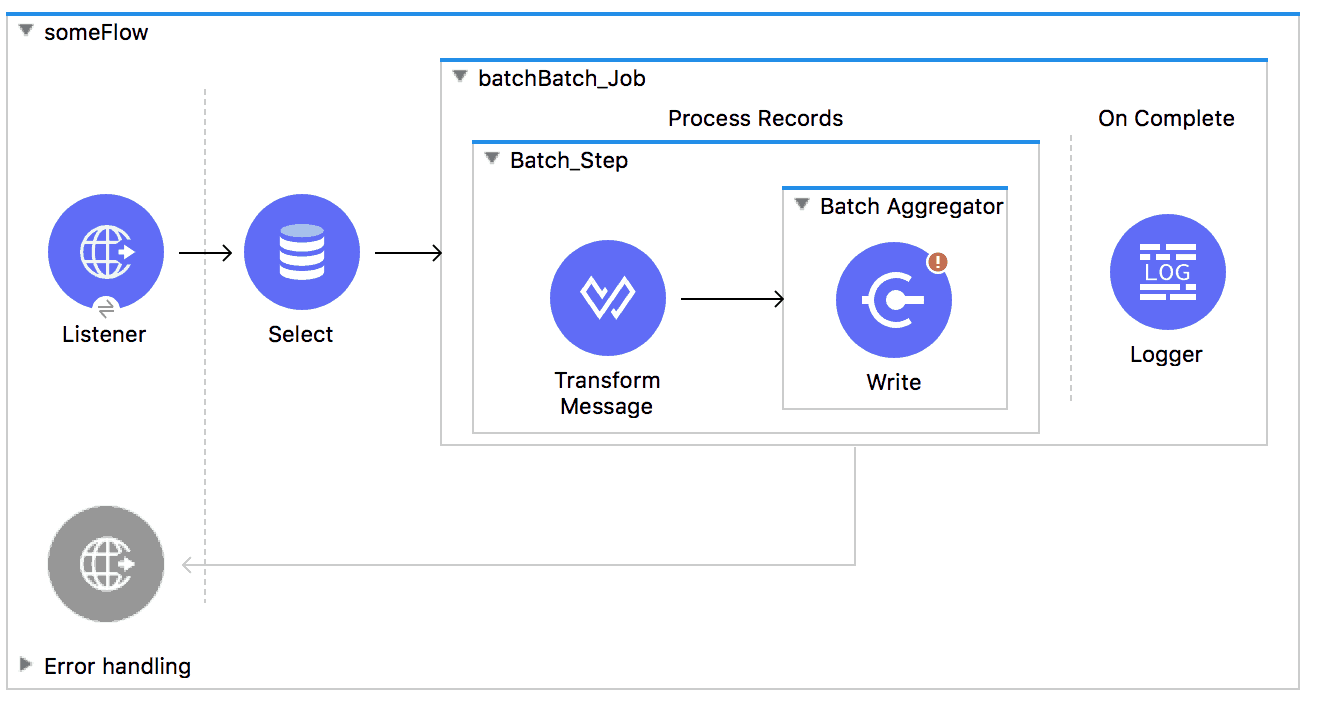
- This also means that there is no input-phase anymore. The role of the input-phase is now accomplished by whatever set of processors are in the flow before the <batch:job> is triggered
- Even though it’s a scope, batch still has a name. No app can have two <batch:job> definitions with the same name. This allows better tracking and management when one single flow defines more than one job
- The <batch:execute> operation doesn’t exist anymore
No More Record Vars!
Unlike a regular flow, batch processes at the record-level instead of message-level; Record vars were a new concept introduced with the original version of batch to allow variables to be attached to a particular record, just like a Flow variable does for a regular Message.
Leveraging the new Mule Message structure (for more information on that, checkout Part I and Part II of the awesome post series by Dan Feist), we no longer need the concept of Record Vars and just use regular vars instead. This is a huge improvement for users because it means that:
- One less concept to learn
- You no longer have to worry about mistakenly setting a flow variable when a record variable was actually needed. This will save you bugs and undesired behavior
- Inside a <batch:step>, you can now modify a variable which existed before the <batch:job> began executing, and you can do it for one particular record, without side effects on the other ones
Support for Non-Java DataSets
In Mule 3, the input phase was required to output a Java structure. It could either be an Iterable, Iterator, or Array, but it had to be a Java structure.
Often, the input data is in another format such as XML or JSON. In those cases, you need to first transform it to Java first, and you need to remember to tell DataWeave to use streaming in that transformation, since otherwise, you can run out of memory for large datasets.
So, suppose you have this source data pushed to your application through an HTTP call:
In Mule 3, you needed something like this:
In this example, you see how after you get the JSON input, you need to transform it to Java before passing it over. But wait! I forgot to tell DW I wanted to stream the transformation! If this JSON was of a considerable size, I could easily run out of memory.
You no longer need to worry about this in Mule 4. Batch can now automatically figure out that the payload is a JSON array and do the splitting on its own:
As you can see, this is a much simpler process, and you no longer have to worry about streaming! In this example, you will already take advantage of Mule 4’s new automatic streaming framework and everything will just work out of the box. (If you’re not familiar with Mule 4 streaming feature, please read this post).
Concepts Clean Up
- Following the Mule 4 DSL guidelines, and in order to improve consistency, all DSL attributes have been changed to camel case. For example, max-failed-records is now maxFailedRecords. The accept-policy is now acceptPolicy, and so on.
- We removed the filter-expression parameter from the <batch:step> element. This attribute was actually deprecated in Mule 3.6 and should be replaced with accept-expression parameter.
- The <batch:commit> is now called <batch:aggregator>
Mutable Aggregator (commit) blocks… Same same, but different

In Mule 3.8, we added the capability to change the variables associated to a particular record inside a <batch:commit> (now called <batch:aggregator> block). If you’re not familiar with this capability, please take a look at this post, which discusses batch improvements in Mule 3.8.
Mutable aggregators were highly reliant on leveraging MEL through expression components. Now that MEL is gone and DataWeave is the default expression language, we cannot do that anymore. As a functional language, DataWeave expressions won’t change input data; they will only produce new data. To achieve the same functionality from Mule 3, you can use Groovy and the Scripting module:
So, if in Mule 3 you did this:
Now you would do:
Batch EL support
Batch used to have a lot of MEL functions, specifically for error handling. If you’re unfamiliar with them, please look at this post, which covers how to handle errors in batch jobs.
For all the functions described in the above post, you will notice that equivalent DW functions were added. They look exactly the same:
The only missing MEL binding is recordVars[] since, as explained above, it no longer exists. Instead, you can use the standard ‘vars’ keyword:
Redirecting the Output
Finally, remember that batch execution is asynchronous. The steps will process the records in its own set of threads. As the records are scheduled for execution, the <batch:job> will immediately return a BatchJobResult instance, which contains information about the job id, how many records were loaded, etc.
Just like any other operation, you can avoid side effects on the message payload by using the target and targetValue parameters.
Try the Mule 4 RC and Give us Feedback!
This concludes the major improvements in the batch in Mule 4. Any other batch features, functionalities, concepts, and limitations that are not mentioned stayed exactly the same as in Mule 3.
Do you like these changes? Please let us know in the comments section and enjoy your enhanced batches! And, if you haven’t tried the Mule 4 RC yet, then download it today by filling out the form!
Plus, check out the following resources to help you get started:
Also, watch our webinar on the new Mule 4 release where you’ll see Studio 7 and Mule 4 in action.



