
In the previous post, Getting Started with DataWeave: Part 2, in this four-part series:
- Getting started with DataWeave Part 1
- Getting started with DataWeave Part 2
- Getting started with DataWeave Part 4
and a webinar about our powerful yet simple new transformation engine, DataWeave, we introduced you to Selector expressions so that you can navigate to and retrieve particular parts of the incoming message. We also showed you how to apply iterative and conditional logic as is required in almost all transformation scenarios.
We now present to you a use case which involves transformations from Java Lists to XML and from XML to JSON.
Scenario
Alainn Cosmetics are adopting an API-led connectivity approach in order to cater to their Innovation team’s demands to get digital solutions to market in a more rapid and agile fashion. They are now working on an initiative to get information about their products to their new Android and iPhone apps. The idea is to build a new Experience API which will deliver this information to the apps with JSON payloads. This same API will call down to a System API responsible for interacting with the system of record for the product information.
System API: From Java to XML


This API reutilizes some of the Messaging and Model schemas previously designed for their SOAP based web services. The abstraction around Item information hides completely any details about the underlying system of record, which in this case is a MySQL database.
A GET call to https://alainn-item-api-v2.cloudhub.io/api/items should return an XML payload as follows:
Note how there are a number of <Item/> elements and each of these has a number of <Image/> elements. The <summary/> element is optional.
The implementation of this API contains the logic to integrate with the MySQL database where the Items are stored. The SQL query sent to the database returns a Result Set which contains the entire set of data including the repeating image for each item.
So you can see the mismatch between the XML document which embeds the repeating Image information inside each Item and the ResultSet which Mule abstracts as a Java List of Maps (each entry on the Map is effectively the column name as defined in the SQL query and its value). The solution to our problem ought to include a grouping together of those Maps which belong to the same Item.
Grouping Logic

Let’s simplify the above so that we can visualize how our groupBy function will convert the DataWeave array of objects (a Java List of Maps is normalized as a DataWeave Array of Objects) into an object whose key:value pairs are determined by the criteria specified as the right-hand operand of the operator. Consider the following: we have as input an array of objects each of which has an item_id field. We will use the value of this field to act as our grouping criteria. Thus each unique value of item_id becomes a key on our output object, and the corresponding value is an array of those objects whose item_id values are equal to that same value.
Objects with Dynamically generated Key:Value Pairs

In our previous post, we explored the use of the map operator as a means to iterate through repeating content in our incoming payload. However, this represents a problem for us: the map operator necessarily produces an array, and we have already seen in the first Post that arrays cannot be rendered in XML. We want to iterate but we don’t want to produce an array. Rather we want to produce a new key:value (Item: {…}) pair inside our getItemsResponse object for each Item we encounter. Likewise, we want to produce a separate key:value pair (image: {…}) inside each Item object. We have seen that objects in DataWeave are defined as key:value pairs inside curly braces {}. In order to generate these key:value pairs dynamically, you need only wrap any expression which produces an array of objects in parentheses (). Our example above should suffice to see this. The payload is an array of objects. Let’s transform it to an object with a sequence of key:value pairs for every pair it encounters in each object in the array.
XML Namespaces
When faced with the need to navigate objects, the result of normalizing incoming XML or the need to render XML as the output of our transformation, namespaces will often need our attention. We use the %namespace <prefix> <uri> header directive to declare prefix – URI pairs. We then utilize these namespaces in our transformation with the syntax prefix#key. Typically, we don’t need to use them in selector expressions on the incoming data unless sibling keys in an object have different namespaces, and we need to distinguish between them.
The Transformation
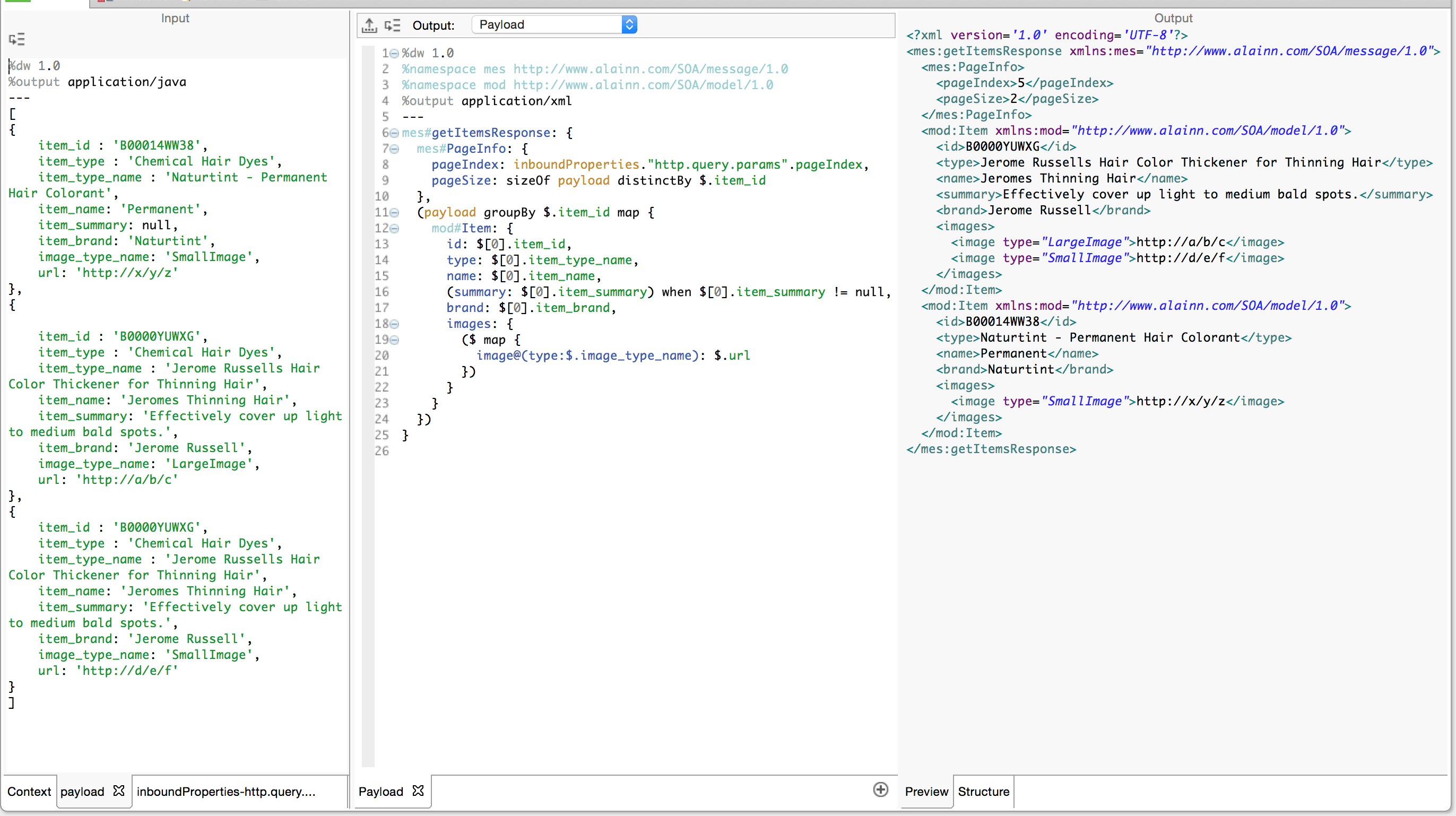
We now have enough tools to iterate through the array of objects (our result set) and build the corresponding XML.
Let’s summarize what we have learned in the light of the above expression:
- Reserved Variables: We have immediate access to payload, inboundProperties, flowVars and sessionVars. These can be used at any point in the transformation.
- De-duplication: To give a correct value for the pageSize key, we use the sizeOf operator. It looks at its right-hand operand and counts the elements (if it’s an array). We generated this array with the expression payload distinctBy $.item_id. The distinctBy operator iterates through payload and filters out any repetition of an object with the same item_id in the resulting array. Don’t forget that $ is an alias for the current iteration.
- Grouping: Given that we should only generate one Item key: value pair for each unique item_id we encounter, it’s necessary to use the groupBy operator so as first to group the objects in the array. (Remember, a Java Result Set in Mule is represented as a List of Maps which in DataWeave is normalized as an array of objects.) The expression payload groupBy $.item_id produces an Object, where each key is the unique item_id we encountered in our Result Set, and its corresponding value is an array of the Objects which hold each record’s data.
- Iteration: As we saw in part 1 of this series, the map operator always produces an array whose elements are produced by the expression in its right-hand operand. It iterates over the keys in the object given by our groupBy operator. Note how we use $ as a place holder for the current iteration in two different contexts as we build the images array. The outer $ refers to the current iteration as we iterate through the key:value pairs in the payload groupBy $.item_id map { } expression. The inner $ refer to the current iteration on the array as we map through the array of Objects for this Item.
- Conditional Logic: Also covered in part 1, we use the when operator here to output the optional key:value pair for summary.
- Dynamic Key:Value Pair Generation: Note how we surround in parentheses the entire payload groupBy expression as well as the expression we use to generate the repeating images. When we define the key:value pairs in an object expression, it is easy when these are static. However, if we need to generate them dynamically (we don’t know how many Items and Images we have in our Result Set) then we need to use the ( ) to extract each key:value pair from each object in the enclosed expression and add these to this object.
- Namespaces: Note how we utilize prefixes to assign namespaces to the keys. mes#getItemsResponse and mod#Item are rendered each with the namespaces which correspond to the prefix we defined in the header.
Experience API: From XML to JSON

This API is exposed for consumption by an Angular App and an iPhone and Android App. The API delivers a JSON payload which contains some hypermedia links. A GET call to https://alainn-my-special-offers-api-v1.cloudhub.io/api/offers should return:
Functions
We can declare functions that are reusable throughout the entire transformation using the %function <function-name> <function-body> header. We make reference to them by name, passing in actual values to the formal parameters declared in the function signature. The body of the function declaration is an expression of any type and will be evaluated with actual values for the parameters for each invocation.
Global Variables
Using the %var <variable-name>=<initial-value> global variable declaration we declare variables which can be used in function bodies as well as the entire transformation expression.
Type Agnostic Comparison
Whenever we make numeric comparisons we need to be mindful of the fact that incoming XML values are usually normalized as strings and that strings are never equal to numeric values. Hence, the string “3” is never equal to the number 3. There are two ways we can address this problem. Either we use the as :<type> type-cast operator or we use the ~= operator. This will cast both operands to the same type and guarantee that “3” ~= 3 will always return true.
Key Presence Conditional Logic
We have seen how we can apply conditional logic to test for value comparisons. Sometimes, we just need to test for the presence of keys in our objects (remember that XML elements are often optional according to their schema definitions). We do this with the .<key-name>? operator. This will return true if the key is present on the context and false if it is absent.
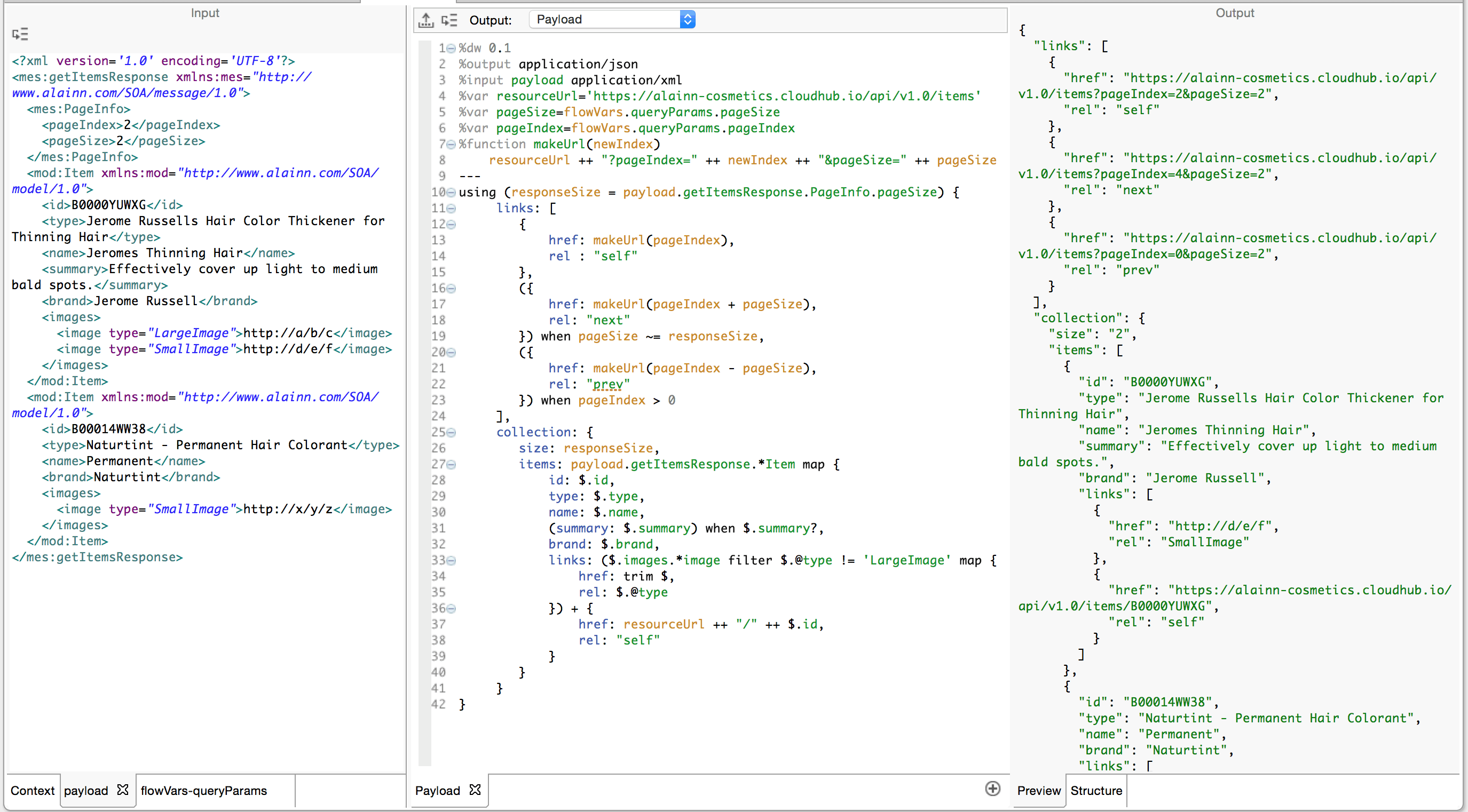
The Transformation
Let’s apply all of the above in our final expression:

Consider the following areas of logic which we utilized in the transformation:
- Function calls: We declare makeUrl(newIndex) to build URLs with the value of newIndex for our hypermedia links.
- Conditional Logic:
- The generation of the prev and next hypermedia links is optional. Note the use of the type agnostic comparison for pageSize ~= responseSize.
- We only generate a summary key for each item if we find a summary key on the input. We do this with when $.summary?
- Array Operators: We append elements to arrays with the + operator. In this case, we append the self hypermedia link.
- Variable References: Note the use of global variables defined in the header. These are referenced by name throughout the expression. Note also the use of local variable declaration prepended to the object expression with the using() clause. Remember the scope of local variables is limited to the expression to which the clause is prepended.
- Namespaces: Though the input XML document contains namespaces, we don’t actually have to reference these in our key selector expressions unless there are sibling keys with the same name and different namespaces. Namespace aware key selectors take the form .<prefix>#<key-name>. In this case we might say payload.mes#getItemsResponse (depending on a namespace declaration in the header) but because all the keys are in the same namespace there is no need.
Summary
That’s it! You can download the APIs built for these two use cases here:
- System API: https://github.com/nialdarbey/system-api.git
- Experience API: https://github.com/nialdarbey/experience-api.git
Try out the console for the System API here:
- https://alainn-item-api-v2.cloudhub.io/api/console
Coming Next
In our next post, Getting Started with DataWeave: Part 4, we will give you a cookbook style guide to some rather interesting and complex transformations. And if you haven’t already, make sure to watch our DataWeave webinar.




{kind=link}