
As AI agents grow in prominence, good data integration is essential. Companies use many applications and data sources, in the cloud and on their own servers, to run their business and understand what’s happening.
While MuleSoft Direct offers powerful pre-built connectors to streamline your integrations, what happens when your critical data resides in a system not directly supported out-of-the-box? This is where the true power and flexibility of MuleSoft Direct shine, allowing you to expand your integration horizons to custom data sources.
What we'll cover in this article: We’ll explore how to leverage MuleSoft Direct Accelerators to extend your solution to custom data sources, using Confluence Data Center as a prime example. We'll delve into the nuances of connecting to systems with unique API structures and demonstrate how MuleSoft Direct empowers you to unlock valuable data, no matter where it resides.
MuleSoft Direct currently provides a pre-built connector for Confluence, but it’s specifically designed for Confluence Cloud. Many organizations, however, still rely on Confluence Data Center for their knowledge management and collaboration, often due to specific compliance requirements, data sovereignty concerns, or existing infrastructure investments.
One compelling use case for MuleSoft Direct in action is demonstrated by Salesforce’s own DevOps AI Agent, which leverages Agentforce and Data Cloud to enhance developer productivity. This agent relies heavily on accurate and comprehensive data to provide intelligent responses and automate tasks.
MuleSoft Direct plays a crucial role by seamlessly integrating unstructured data from diverse sources like Confluence and Google Drive into Data Cloud. This ensures that the Agentforce has access to a rich repository of knowledge, including documentation, project notes, and other essential information, ultimately powering more effective and context-aware Agentforce Actions.
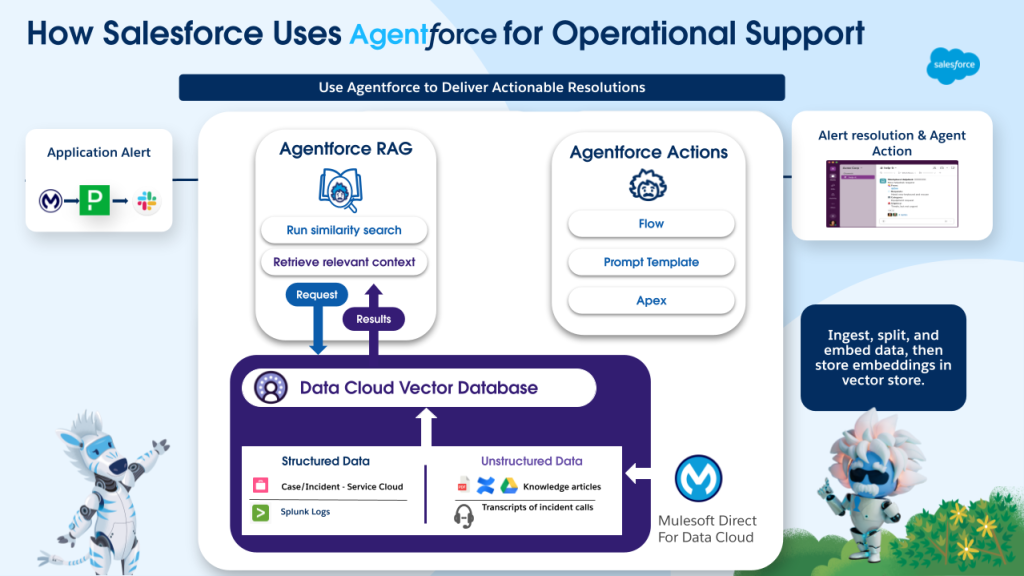
What is MuleSoft Direct for Data Cloud?
MuleSoft Direct for Data Cloud gives organizations a faster, easier way to unlock the value of their unstructured data. With ready-to-use integrations, you can quickly connect your company’s knowledge repositories to Salesforce Data Cloud.
Out-of-the-box connectivity is available for key systems like Google Drive, Microsoft SharePoint, Confluence, and Sitemaps. Each integration comes pre-packaged with API specifications, implementation templates, and technical assets, making it simple to extract valuable information from your repositories and unify it in Data Cloud.
Because MuleSoft Direct follows MuleSoft’s proven best practices for connectivity, you can discover, configure, and deploy these integrations entirely within Salesforce, streamlining the entire process. Once your unstructured data is in Data Cloud, it becomes a powerful resource across Salesforce. You can ground AI prompts using retrieval-augmented generation (RAG), enabling faster, more accurate, and more personalized customer experiences.
With MuleSoft Direct for Data Cloud, your knowledge is no longer locked away; it’s connected, actionable, and ready to drive AI-powered insights.
MuleSoft Direct architecture
The solution enables ingestion of unstructured data from various source systems into Salesforce Data Cloud, making it accessible for downstream Agentforce use cases. MuleSoft Direct acts as the deployment and orchestration layer for integration applications, ensuring seamless connectivity, metadata synchronization, and content retrieval.
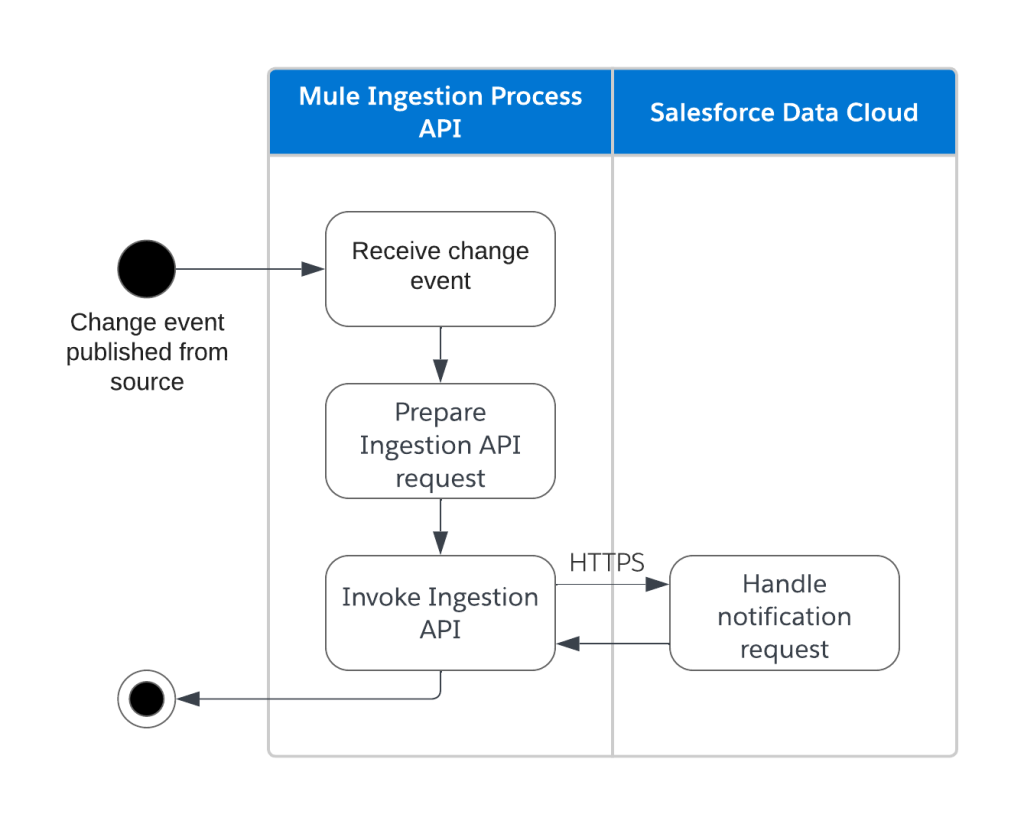
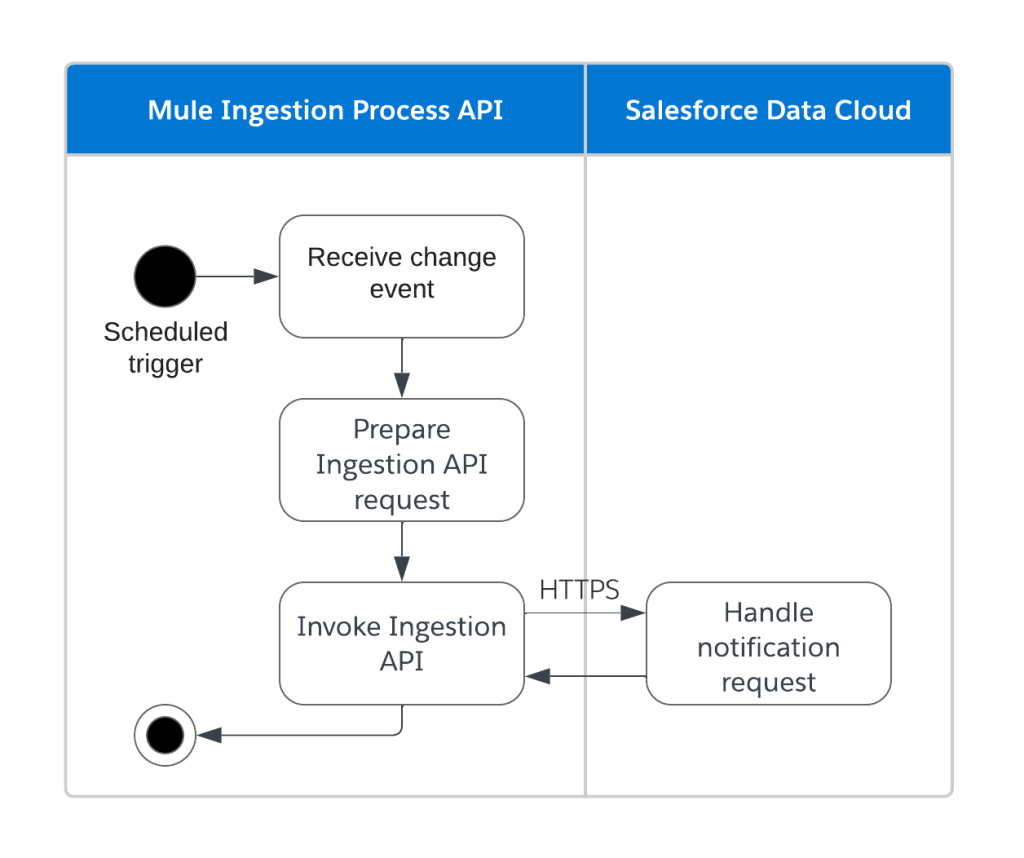
- Metadata ingestion: Triggered by either an initial load (“Refresh Now” button on UDLO) or change notifications for event-driven data sources. Mule applications call source system APIs, transform responses, and push metadata into Data Cloud.
- Event-driven updates: Source systems send change notifications to Mule applications. Mule apps fetch updated metadata and sync with Data Cloud.
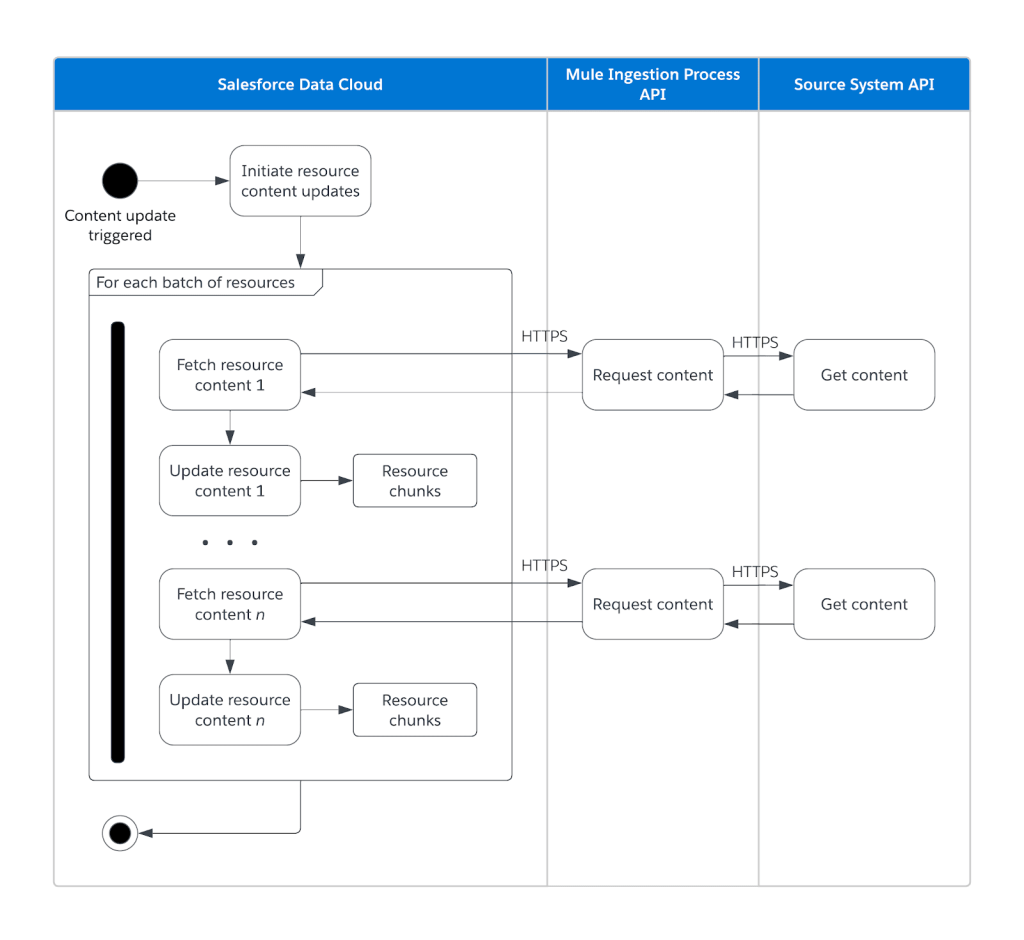
- Content retrieval: Upon request from Data Cloud Search Index, Mule applications fetch the content from the source system and return it in supported formats.
- Data Cloud indexing and Agentforce consumption: Ingested content is indexed in Data Cloud. Agentforce retrieves indexed content for context-aware AI responses.
How MuleSoft and Data Cloud work together
MuleSoft Direct offers pre-built integration with Data Cloud, automating the entire process from start to finish. This automation includes:
- Establishing a connection
- Deploying a Mule application to Anypoint Platform
- Creating an asset in Exchange and API Manager
- Generating a contract
- Automatically creating a named credential Data Cloud connector on the Salesforce side
Push notifications
Poll notifications
Get content
Expand MuleSoft Direct to Confluence Data Center
MuleSoft makes it incredibly easy to adapt and build Mule applications by simply changing the underlying APIs and following the existing orchestration. This means you can tailor MuleSoft Direct to connect with Confluence Data Center, or indeed, any other custom data source that may not have a dedicated pre-built accelerator. This approach ensures that your integration strategy remains agile and capable of addressing evolving business needs.
The key difference lies in their underlying APIs. Confluence Cloud and Confluence Data Center have distinct API structures, meaning the pre-built accelerator for Confluence Cloud will not function with Data Center installations.
For instance, searching using CQL (Confluence Query Language) differs between the two environments:
- Confluence Data Center: http://myhost:8080/rest/api/content/search?cql=space=TEST
- Confluence Cloud: https://your-domain.atlassian.net/wiki/rest/api/content/search?cql={cql}
Confluence Data Center webhooks, which publish events for an entire instance, aren’t suitable for notification needs for a given space. This is why you’re transitioning from a webhook-based notification framework to a scheduler-based source retrieval system. The following example demonstrates how you can retrieve Confluence updates using the last modified date via Confluence Query Language (CQL).
http://myhost:8080/rest/api/content/search?expand=space,history&start=0&limit=200&cql=space = {spaceName} and type = page and lastModified >= '2024-05-31 18:16'Here is an example of the output of the CQL.
After applying the transformation in the DataWeave script, the beacon API can be used to notify Data Cloud of the changed file’s metadata. Here is an example of a request to beacon API.
The following code snippet demonstrates how to convert CQL output, including space and history information, into the required payload for the Data Cloud Beacon API.
/**
* Provides the content metadata details of resources maintained in the source system.
*/
%dw 2.0
import * from dw::core::URL
import * from dw::core::Strings
output application/json skipNullOn="everywhere"
---
{
"continuationToken": if ( !isEmpty(payload.'_links'.next) ) (substringAfter((splitBy(parseURI(payload.'_links'.next).query, "&") filter ($ contains "start"))[0], "start="))
else "",
"resourceChanges": (payload.results) map (item, index) ->
{
"applicationId": p('api.autodiscoveryID'),
"sourceId": item.space.id as String,
"sourceType": p('app.data-source-type'),
"changeEventType": p('confluence.change-event-type'),
"eventDateTime": now(),
"resourceEntry": {
"resourceId": item.id,
"resourceName": item.title,
"resourceType": p('confluence.content-type'),
"resourceLocation": item.'_links'.self,
"resourcePath": item.'_links'.webui,
"contentType": p('confluence.content-type'),
"contentVersion": item.'_expandable'.version,
"authorName": item.history.createdBy.displayName,
"authorId": item.history.createdBy.userKey,
"createdDate": if ( !isEmpty(item.history.createdDate) ) (item.history.createdDate)
else if ( !isEmpty(item.history.'_expandable'.lastUpdated) ) (item.history.'_expandable'.lastUpdated)
else now(),
"createdBy": item.history.createdBy.displayName,
"updatedDate": now(),
"updatedBy": item.history.createdBy.displayName,
"isArchived": false,
"isDeleted": false
}
}
}The next crucial step involves creating the Data Cloud Unstructured Data Lake object. An existing connection can be leveraged to create both an unstructured data lake object (UDLO) and an unstructured data model object (UDMO). Once metadata is loaded from your customized MuleSoft application, you can build a search index and utilize that retriever to power RAG-based agent responses within Salesforce, dramatically enhancing the capabilities of your CRM system with relevant knowledge from your custom sources.
To build a custom source integration, you can utilize the SDC Ingestion Template Process API from MuleSoft Exchange. For reference, here is the existing SDC Ingestion from Confluence Process API template.
By understanding the differences in APIs and leveraging MuleSoft Direct’s flexible templates, you can unlock a world of integration possibilities, connecting your Data Cloud with virtually any custom data source, including on-premise systems like Confluence Data Center. This empowers you to truly maximize the value of your data, no matter where it resides, driving more intelligent operations and informed decision-making across your organization.
MuleSoft Accelerators to fast track your implementation
By leveraging MuleSoft Accelerators, you can significantly fast-track your integration implementations, saving countless hours in discovery, design, development, and testing. These pre-built solutions, available in Anypoint Exchange, provide ready-to-use reference architectures, API specifications, and application implementations for common use cases across various industries.
They enable you to focus on your unique business logic, knowing that the foundational integration components are already optimized and aligned with best practices. Whether connecting to an out-of-the-box source like Google Drive or a custom data source like Confluence Data Center, MuleSoft Accelerators help you deploy strong integrations faster, bringing immediate value to your business.



