
Hello there! If you’ve been using Mule for a while now, you probably remember that the batch module was introduced back in the 3.5 release. If you’re not familiar with it, you can familiarize yourself by following these links:
- Introducing the Batch module
- Batch Module Reloaded
- How to build a Batch enabled connector
- Near Real time syncs with the Batch Module
- Handling errors
- Tuning Batch Jobs
We received a lot of love for this feature, but as adoption grew, so did the requests for improvements. We introduced 3 popular improvements in the 3.8 release of Mule, and this is the first of a 3 part series to describe them.
In a nutshell, the batch module now gives you:
- Read/Write access to a record’s payload and variables when inside a commit block
- The ability to customize the queue block size
- Configurable job instance ids
Let’s discuss the first feature…
The Problem
As you know, the commit blocks are used to group a set of records together in order to perform bulk operations. For example, if you want to insert contacts into Salesforce or write to a DB, it would be quite inefficient to do that on a record by record bases, mainly because of the I/O cost (network overhead, disk overhead, etc). So, it’s better to only perform one bulk operation in which you perform those inserts for many records at a time. If you want more context and examples around uses for the commit block, please check the links above.
The problem is that the commit block only used to expose the grouped record’s payload. It did not allow you to change those payloads nor to access (for either read or write) the associated record vars. Hence, imagine a batch job in which you want to insert contacts into salesforce and then log the generate salesforce ids. There was no way of doing this with a commit block prior to 3.8. You would have to do it on a record by record basis, which would not only be slow but probably rapidly exceed your Salesforce API quota in no time.
The Solution
The solution is to simply expose the grouped records payloads and record vars as variables as context variables you can use through the Mule Expression Language (MEL). So, let’s consider an example:
I went into the Mule Exchange and took an example of an application which inserts a CSV full of contacts into Salesforce. You can find such example on this link: https://www.mulesoft.com/exchange/#!/import-contacts-into-salesforce
I then modified it a little bit to express the same thing as a batch kob:
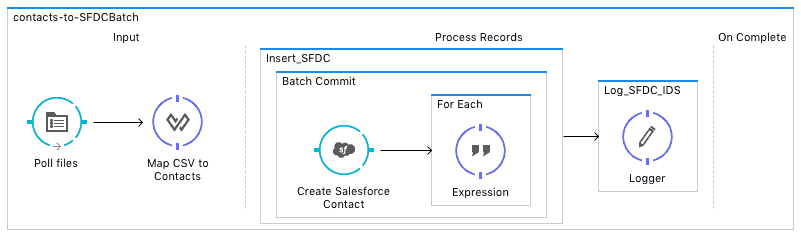
The above job has:
- An input phase which polls for those files and uses DataWeave to transform the file into a List of Maps
- Then it has a step with a fixed sized commit which inserts those records into salesforce, and then uses a foreach block to extract and set the generated SalesforceIDs (more detailed on that to come)
- Finally, has a second step which simply logs the extracted IDs.
Sequential Access
As you probably figured by now, the magic happens on the foreach block. The block has one simple expression component:

As you can see, whenever you place a foreach block inside a commit block, you will automatically get a variable called record which holds a reference to one of the aggregated records. This example shows you how to access the record vars and set the generated id.
Other valid expressions are:
This approach has a limitation though: It assumes that the list you’re iterating complies with the following restrictions:
- The size matches the amount of aggregated records
- There’s a direct correlation between the aggregated records and the items in the list. Meaning that the first item in the list being iterated correlates to the first aggregated record and so on…
This is true for most use cases including the example above, and although these restrictions are something you must not loose sight off, they make most cases easy to deal with. However, this is not enough for all use cases…
Random access of records
For those cases which don’t fit the above restrictions, we also expose a variable called records which is a random access list. That variable is accesible all across the commit block, not just inside a foreach, and can be used more freely:
The example above just plays with the first record which is not something that makes much sense on the real world, but it does show that as long as you know how to handle list indexes, you can do pretty much whatever you want. Just for the sake of it, I’m now going to show you how to use random access to produce code that is semantically equivalent to the sequential access example:
In this example, you see how the counter variable that foreach uses to keep track of the iteration is used to access the correct record.
Streaming commits
The last case to consider is that of streaming commits. As you know, there’re two types of commit blocks: fixed size and streaming. Fixed size aggregate sets of records up to a certain limit which must be able to fit in memory. The record payloads are exposed as an immutable List. Streaming commits give access to the entire set of records, which is presumed to not fit into memory. So instead of a List, streaming commits use a forward-only Iterator which knows how to perform streaming in order to avoid the memory problem. How does it relate to this feature? Simple: because of the memory restriction, random access is not supported on streaming commits. You can only use the sequential access flavour of it that was explained on the first example.
Summary
This new feature enables lots of use cases which users have reported to have issues with and that we have found challenging ourselves while building the examples on the Anypoint Exchange. Do you find it useful as well? Feedback welcome!
See you soon!



