
After Peak Time Handling, and its heated discussions :), the Beyond Integration series continue with this new installment!
The thought of working on a legacy system makes developers shiver: they know the feeling of tiptoeing in a crystal palace or trying to run with lead-soled shows (and sometimes having to do both at the same time). At higher hierarchical levels, the idea of touching a legacy system doesn’t create much joy either, as it has “big bucks” and “unpredictability” painted all over it. But, driven by necessity (be it product end of life or the addition of new features), legacy applications end-up being modernized.
Bringing Mule ESB in the equation can help evolving legacy systems towards a new architecture that is more favorable to both the technical and business sides of things.
Legacy systems suffer from many miseries, one of them is that, being big balls of mud, they often present themselves as monolithic blocks, with coarse grained interfaces that encompass big chunks of business logic. In this post, I will discuss the opportunities that exist in shattering such monoliths and tying the pieces back together with Mule ESB.
Everybody enjoys a lovely set of before/after pictures. So let’s start with our system before shattering:
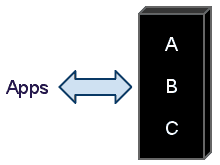
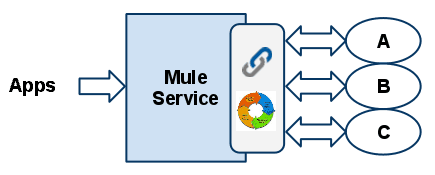
Our (not so) hypothetical system, performs three different business operations behind a unique coarse-grained interface exposed to its client applications. Each operation is performed in sequence and, most probably, within the same transaction.
Now let’s take a look at the after image:
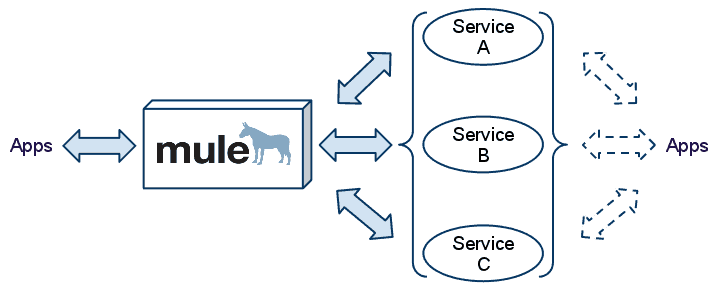
Each of the three operations has been extracted and exposed as a fine-grained service, while Mule has been introduced to act as an orchestrator of these services in order to present to the client applications a similar call semantics.
Here are some benefits of such an evolution:
- The code of each of the service reduces in size and becomes more maintainable.
- New business applications can be created by directly addressing the logic that has been disentangled.
- Database wear is reduced because a typically long running transaction has been broken into smaller ones.
- Temporal coupling can be reduced if all the operations don’t need to be performed in order to reply to the calling application. In that case, the orchestration doesn’t need to be fully synchronous.
And here are some drawbacks:
- The three operations are not performed in an atomic manner, creating potential consistency issues and forcing the different services that have been created to gracefully handle eventual consistency (think idempotency, lazy creation, self healing).
- What was centralized is now distributed, with all the challenges implied by such an architectural shift.
Before you, dear reader, start crying fool and yelling at the oversimplification let me make my point clear: I’m fully aware that relaxing transactional constraints or time coupling doesn’t relax developers. My point here is not that such relaxations should always be done, the problem is that developers will often dismiss them as impossible without even honestly considering them. Sure it is about stepping out of the comfort zone of transactional boundaries and linear timelines: it’s hard, our brains are in pain whenever we try to juggle with disconnected processes, but the potential benefits make the intellectual effort worthwhile.
And, yes, it’s been done in real life!
Let’s now discuss how the orchestration would be implemented on the Mule side of things. There are different options that depend on the overall synchronicity of the orchestration.
Fully synchronous
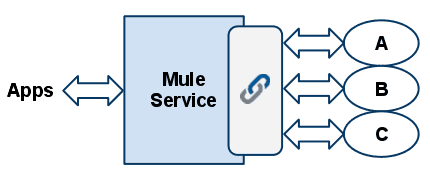
If the calls to A, B and C must all be done in order to build an acceptable response for the calling application, a good option is to rely on a chaining router with synchronous outbound endpoints.
Partially synchronous
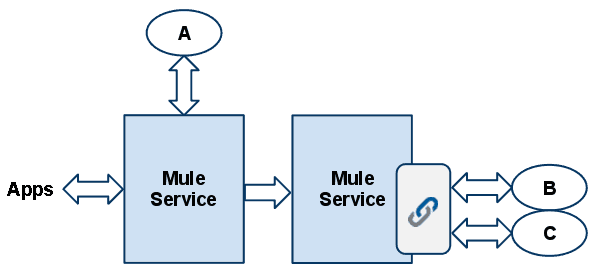
If the response of service A is necessary in order to build a relevant reply for the callers, you can use either component binding or requesting to invoke the service synchronously. Then the remaining steps of the orchestration can be performed by another service, called asynchronously.
Fully asynchronous
Interestingly. there are cases where it’s possible to give a default response to the calling applications, independently of the outcome of the orchestration. This allows to maintain backwards compatible call semantics for the callers. Of course, this requires that the system, as a whole, is able to recover from a potential failure of the orchestration. In that case, using a chaining router or a BPM-based orchestration would be appropriate.
Now your turn: what’s your strategy to shatter the monoliths that probably haunt your IT landscape? Have you used Mule for that matter?



