
In the world of data integration, error handling is crucial to a successful data integration strategy, however, it is often one of the most overlooked areas because, quite frankly, it can be quite intimidating when you initially try and understand it. In my series of blog posts, I hope to reduce this complexity by breaking it up into simple concepts that are easier to digest.
In my previous posts I have discussed the basics of error handling in MuleSoft:
- Understanding how on-error propagate/continue work.
- Understanding the behavior of each in different scenarios.
- Understanding how to handle specific errors.
In this post, I will discuss how these concepts can be combined into reference architecture to handle different types of errors… but before I get into these different architectures, it’s important to understand the types of errors that can occur within different types of integrations.
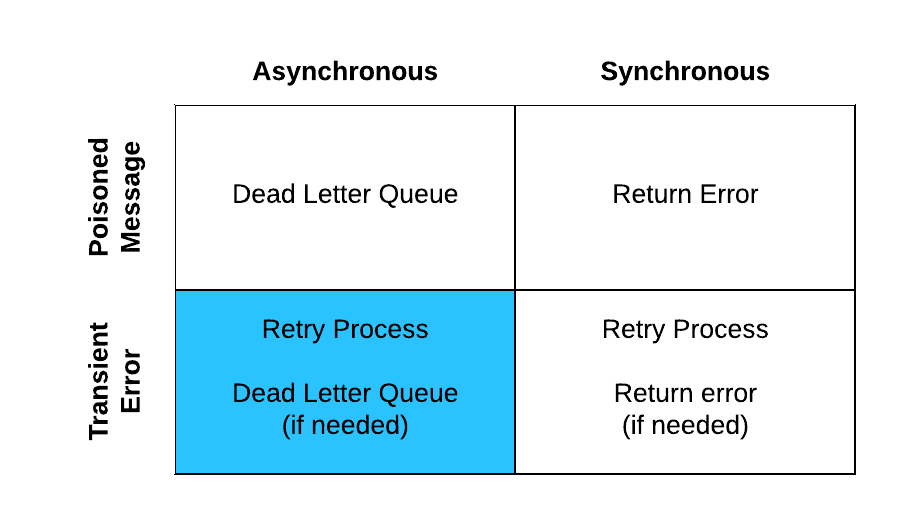
Transient errors vs poisoned messages
In general, you can classify errors into two different categories: transient errors and poisoned messages.
Transient errors are errors that occur sporadically and can typically be resolved by retrying the processing of the message. For instance, if you try to connect to a system and get a networking error or a request timeout error… those errors can typically be solved by waiting and resending the messages.
Conversely, if you were to get an error message indicative of an authentication error or a resource not found error — no matter how many times you retry those messages — they won’t resolve themselves. These types of errors are considered poisoned messages and require some kind of intervention to be resolved.
An important thing to remember about transient errors is that they are only transient errors for so long, and can become poisoned messages that need manual intervention. For instance, say you are trying to connect to some SaaS application and you get a service unavailable error on your first attempt, then retry the request three or four more times and still keep getting the same error. At some point, a decision must be made to stop retrying the message and surface the error to get some kind of manual intervention. At this point, the transient error becomes a poisoned message and is handled as such.
On top of different types of errors, you also need to be conscious of the integration patterns that these errors occur in so that you can handle them correctly.
Synchronous vs asynchronous integration
From a very high level, there are two different patterns for integrating data: synchronous and asynchronous and it is important to understand what is meant by each. To better level-set on this topic, let’s use a simple example of a real-life problem: delivering a package.
Option 1 – You can package up everything, drive across town to deliver the package, hope the person is home, deliver the package, and get on with your day.
This is synchronous integration. In this instance each step is verified as completed before the next one is started and you must wait for all of the steps to complete before you get on with your day.
Put in more tech terms, synchronous integration (sometimes referred to as blocking communication) is when a sender application sends a request to a receiver application and must wait for a reply before it can continue with its processing. This is typically used when the processing of one step depends on the results of the previous step.
Option 2 – You can give the package to the mailman and have them do all the work so you can get on with your day.
This is asynchronous integration (sometimes referred to as non-blocking or fire-and-forget communication). In this instance, you can simply allow someone to do the work and you don’t have to wait for them to complete their work for you to get on with your day. In other words, the sender application does not depend on the receiver application to complete its processing in order for it to move forward.
In both cases the packages get delivered to the recipient, just in different ways and each has different benefits. In synchronous integrations, you have greater control of what happens in each step and have immediate confirmation of whether something is successful or failed…however it is time consuming as you need to wait for every process to complete. Conversely, asynchronous integrations are typically less time consuming from a request/response perspective because of the fire and forget mentality… however it often takes longer to identify when issues occur.
Also, it is important to note that these two different styles of integration are not mutually exclusive when it comes to projects — both can be present in the same integration. Take for instance, the following scenario where you have a main process and then several processes spun off on the side:
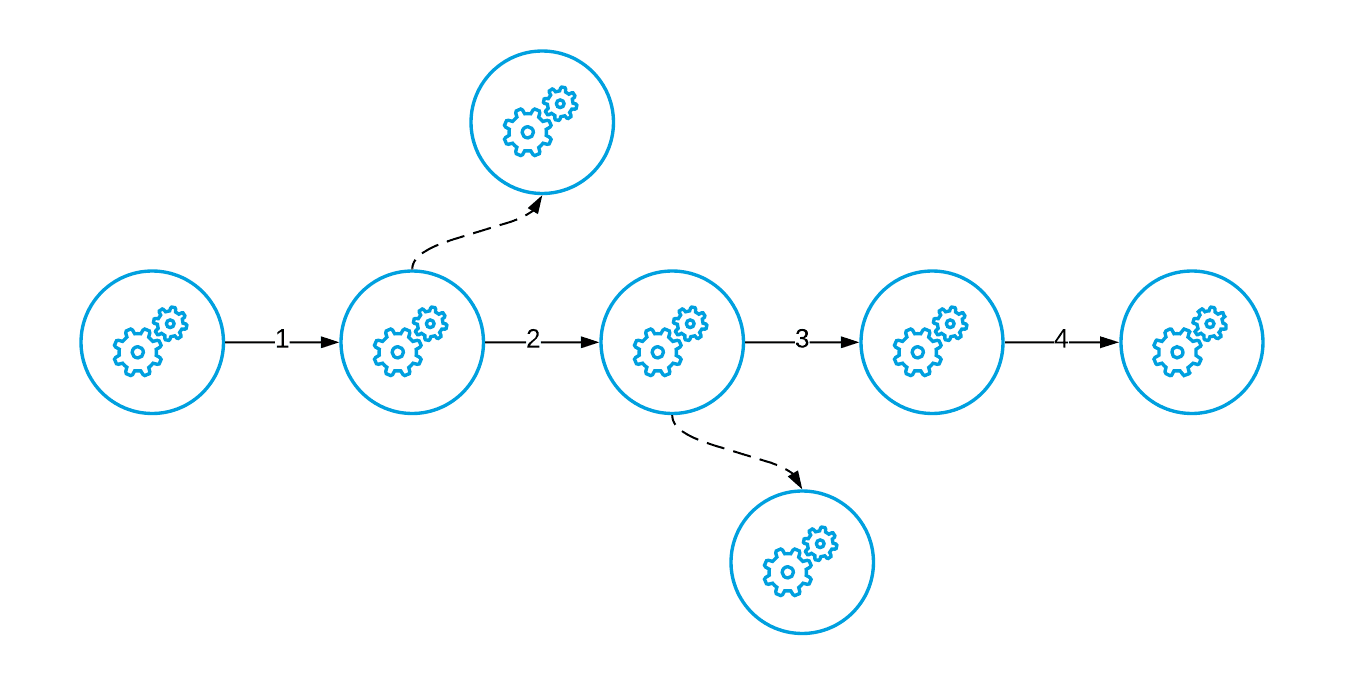
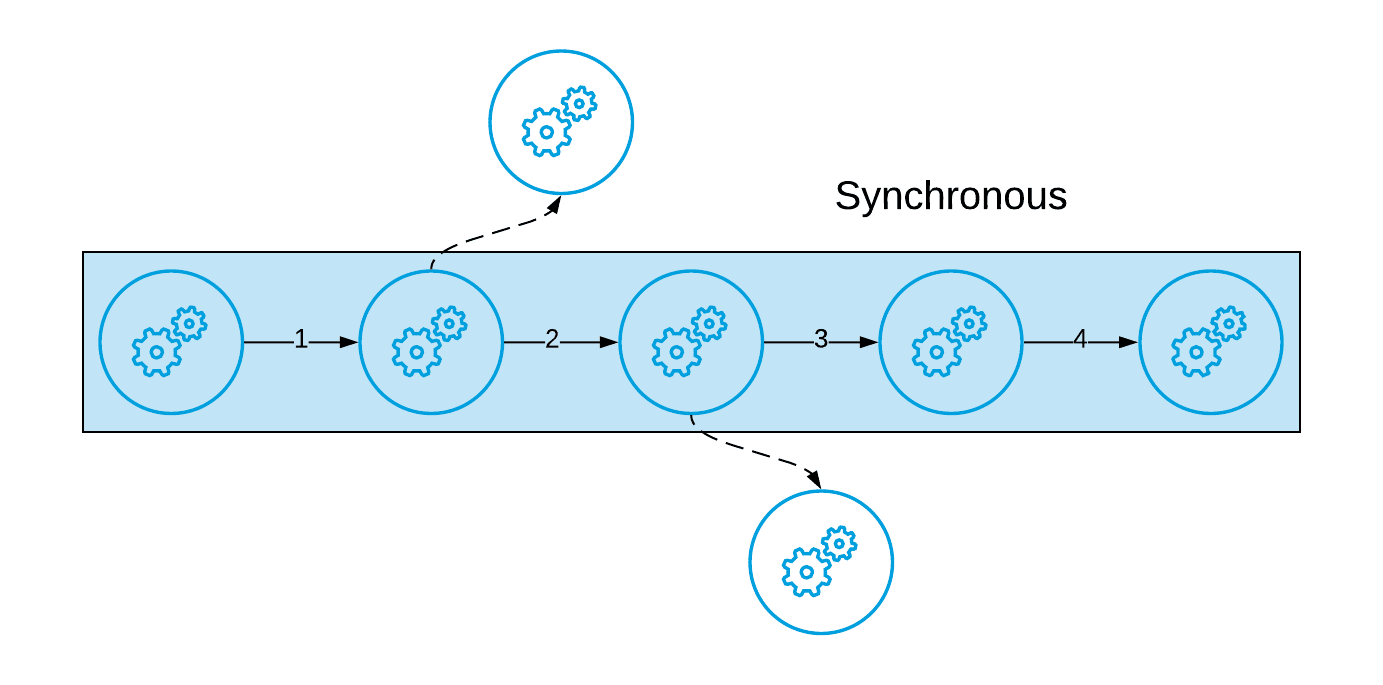
The idea is that the main process can be ran synchronously:
While allowing spin off processes to run asynchronously (for instance alerting, or inventory manipulation etc):
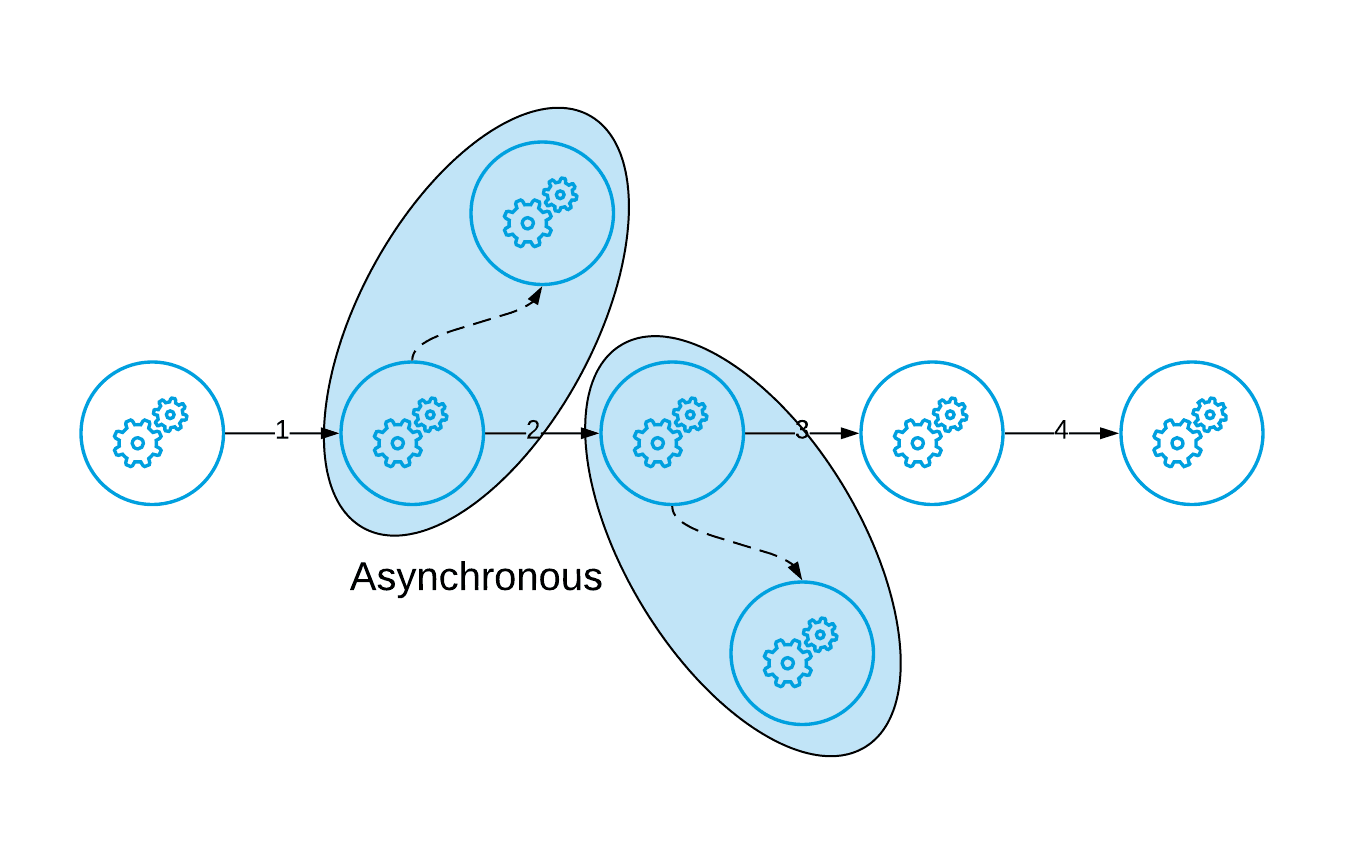
It is important that you understand how each of these patterns work because, in both cases, you can have errors occur and those could be either transient or poisoned messages and each type of error is handled in different ways.
Handling of pattern specific errors
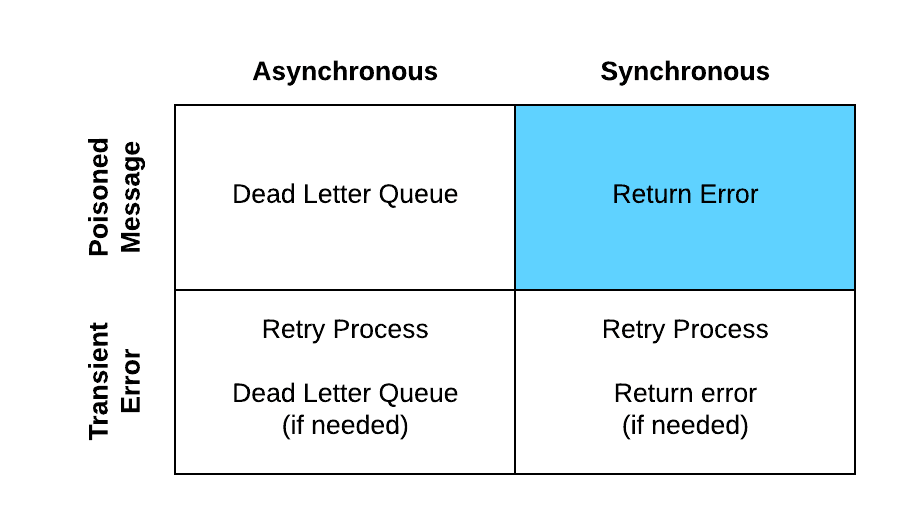
When thinking about types of errors it’s helpful to categorize them into the patterns they occur in and then the types of errors that they are. This will determine the method for handling these errors. The four categories are:
- Asynchronous poisoned messages
- Asynchronous transient errors
- Synchronous poisoned messages
- Synchronous transient errors
Synchronous Message Processing
When an error occurs during synchronous message processing, your options are fairly limited as to what you can do to handle the errors. The reason your options are limited is simply because of the nature of the synchronous pattern in that one step depends on the others. Therefore, if you don’t complete all the steps in the process successfully, you will likely need to roll back all of the steps in the process if an error cannot be handled gracefully.
Synchronous poisoned messages
In this case, you are processing messages in a synchronous fashion and one of the steps fails with an error that, no matter how many times you were to retry it, cannot be resolved without manual intervention. In this case, your only option is to simply return the error to the sending application. Below is the simple processes:
- Rollback any transactions that were created earlier in the flow.
- Error messages are logged using the standard error handling framework.
- Return the error message to the requestor.
Synchronous transient errors
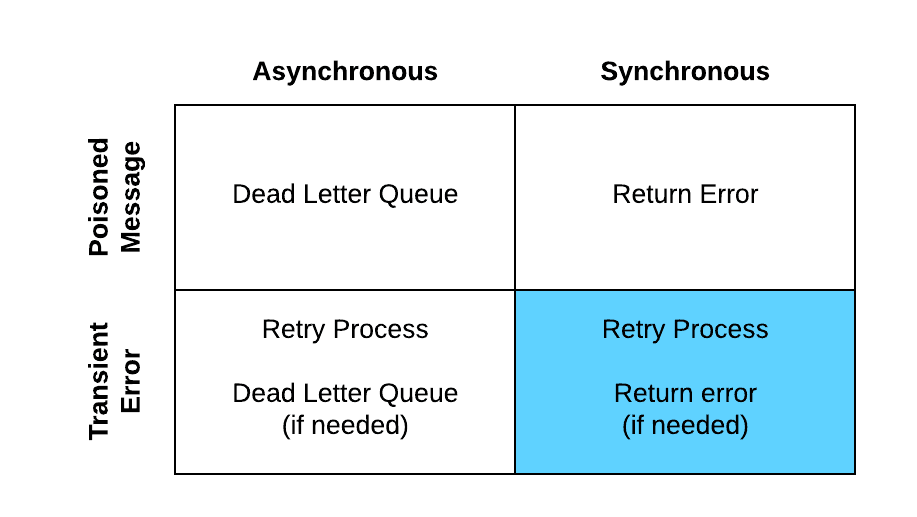
In this scenario, you are processing a message in a synchronous fashion and have some kind of error occur where you can, likely, resolve by retrying the message and don’t need manual intervention. With that being said, at some point you will reach a predefined limit for how many times you will retry the message and then it will become a poisoned message and will be handled as such.
- Message is retried as per the pre-configured max retries and retry interval.
- If applicable, the retry will be attempted:
- Retry count incremented.
- If successful the result is returned.
- If unsuccessful, wait the define retry period.
- Retry the error again.
- If max retries is reached, the transactions that were created earlier in the flow should be rolled back.
- Error messages are logged using the standard error handling framework.
- Return the error message to the requestor.
Asynchronous Message Processing
The ability to handle errors in asynchronous integrations may be a bit more complicated in process, but this enables you to have more flexibility with your processes.
In asynchronous error handling, we introduce the concept of queues to the picture for error handling, specifically:
- Retry queue – A queue used for holding messages that need to be re-processed. Typically, an integration is built to read messages from this queue and re-process them automatically.
- Dead Letter Queue – A queue used to hold poisoned messages for manual intervention.
Between the two of them they will be used as part of the below reference architecture for handling asynchronous errors: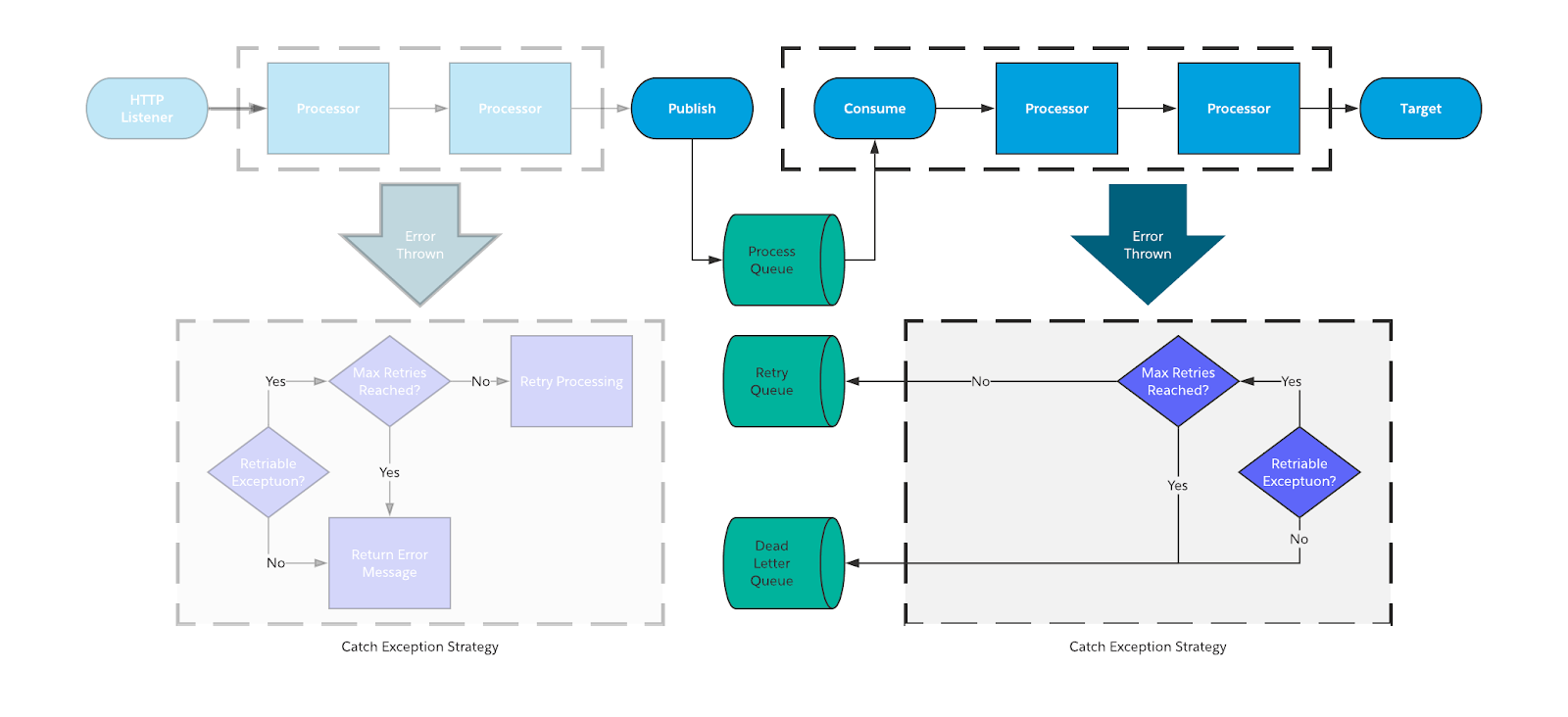
On the left hand side (shaded out) you can see the way that we handle synchronous errors. For the next section, we will talk about the right side of the diagram which depicts the handling of asynchronous errors
Asynchronous poisoned message
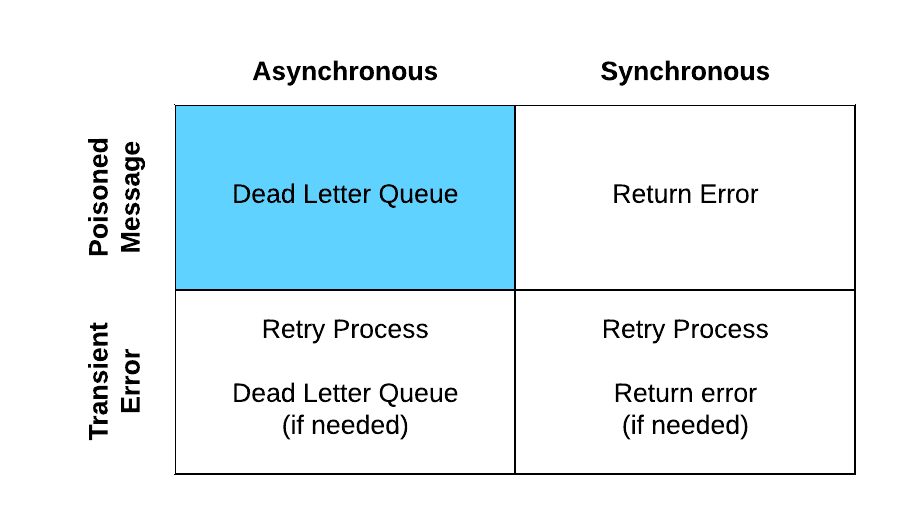
As with synchronous messaging, when you get a poisoned message, there isn’t much you can do other than surface the error so that it can be manually addressed. The process for this is as follows:
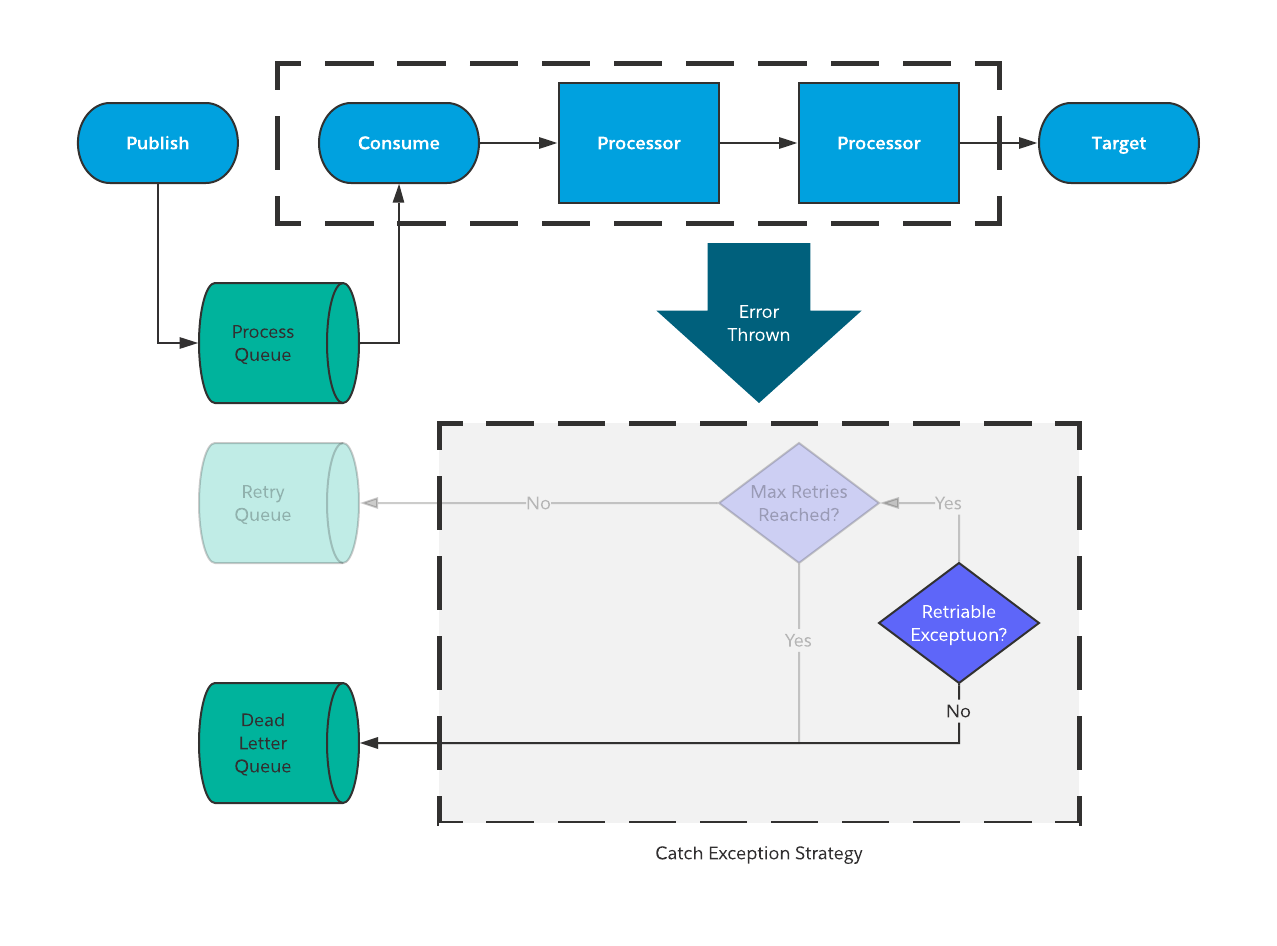
- Rollback any transactions that were created earlier in the flow.
- Error message is logged using the standard error handling framework.
- Publish the message to the Dead Letter Queue for manual intervention.
Asynchronous transient errors
Transient errors that occur during asynchronous integrations are a huge area where automation can help you with gracefully handling errors without human intervention. With that being said, handling these types of errors also has the most “moving pieces” and therefore takes some effort to develop this process.
The basic strategy for handling of transient errors in asynchronous patterns is to:
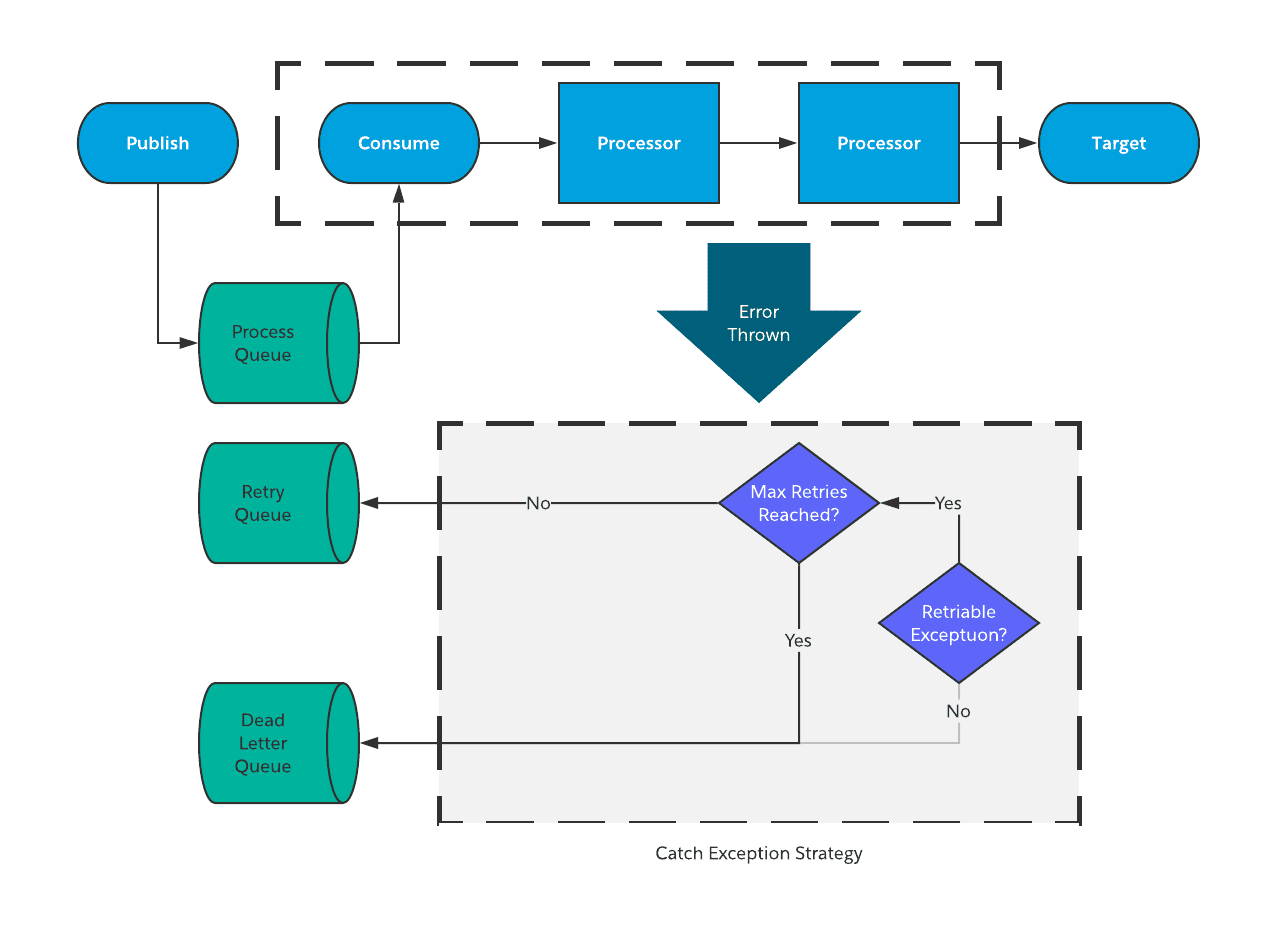
- Check to see the maximum number of retries have happened.
- If yes, send the message to a Dead Letter Queue.
- If not, send that message to a retry queue for future retry processing.
- Build out a process to automatically retry the processing of the messages.
This process seems pretty simple from a high level, but the key is in the last step, building out a process to automatically reprocess messages. Let’s dive a little deeper into what that looks like.
Retry Process
In asynchronous error handling, the retry process is the real meat and bones of the “magic” of the error handling, in this scenario. In this process a message — when ready — is pulled from the retry queue and re-submitted to the appropriate process queue for re-processing. This procedure should be flexible so that the process can be kicked off automatically via a timer (or something similar) but also kicked off manually to allow manual re-processing of messages.
It is also important that when messages are submitted to the retry queue that they have particular attributes so that the retry process can effectively route the message for processing. Some example aspects are:
- Error Code
- Error Message
- Process Queue Name
- SLA
- Last Processed Time Stamp
Here’s what a sample process would look like:
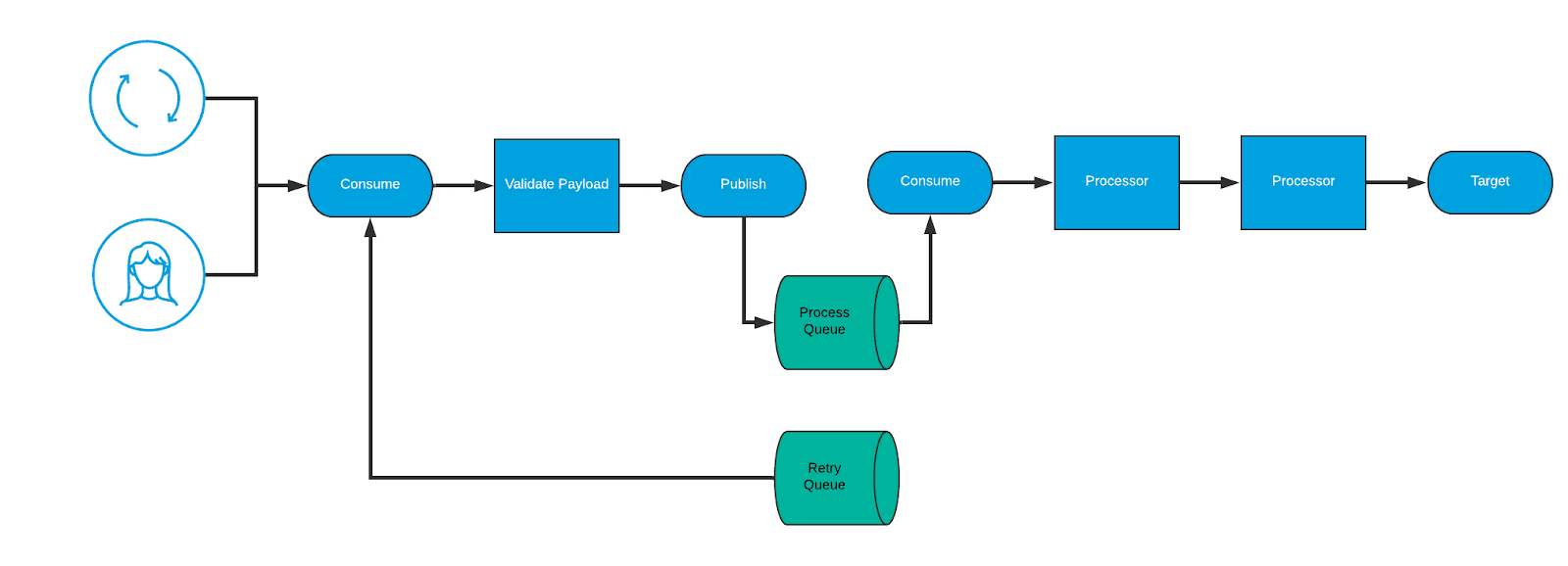
- A message ready for re-processing is pulled from the queue — triggered either manually or via some kind of scheduled process.
- The payload is validated to make sure it is a valid payload and wasn’t corrupted.
- The message, based on the details in the message, are submitted to the original process queue for re-processing.
- Once this processing takes over, the asynchronous error handling strategy (discussed earlier) takes over.
Bringing it all together
In an ideal scenario, applications would run smoothly and there won’t be errors, but as we all know, errors happen and the way that an enterprise handles those errors can make or break an organization when it comes to their data integration strategy. It is important that errors are handled as seamlessly as possible and, as much as possible, handled without human intervention.
Oftentimes, it can be a bit overwhelming for people to develop an error-handling strategy, but if you break it down into smaller pieces, it’s much more consumable. In previous blog posts in this series, I have addressed the fundamentals of how to build error-handling components into your flows and, with this blog, addressed how to handle errors from a patterns perspective. In my next, and final part of this series, I plan to address how organizations can approach building their error handling strategy and build the needed components to handle this strategy.
For more developer resources, trainings, and tutorials, check out developer.mulesoft.com and training.mulesoft.com.



