
In this penultimate part of my ESB or not to ESB series I’m going to cover two more architectures; API Layer and Processing Grid providing the benefits and considerations for each.
Previous Posts:
- ESB or not to ESB – original post
- ESB or not to ESB revisited – Part 1. What is an ESB?
- ESB or not to ESB revisited – Part 2. ESB and Hub n’ Spoke Architectures
- ESB or not to ESB Revisited – Part 3. API Layer and Grid Processing Architecture (this post)
API Layer
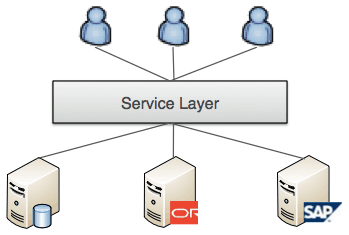
An API layer (or Service Layer) provides a set of APIs to access data and/or functionality. Typically implemented using REST or SOAP services over HTTP, it provides decoupling of backend systems and applications from the clients that access them.
API Layer Characteristics
Used to provide programmatic access to data or functionality and API Layer provides a REST or SOAP interface to one or more sources of data such as databases, file systems, legacy applications.
- Need to make data in databases or file systems available to a wider audience
- Reference / Lookup data – usually database, flat file or Excel spreadsheet
- Modernize legacy applications by providing REST access to its data functionality
- Provide a REST API in addition to an existing SOAP API to cater for a broader range of clients
- Publish a data source from two or more applications providing a union of the data sets i.e. combine your company employee database with LinkedIn and Facebook data, to provide richer information.
The API Layer architecture pattern needs to take care of access to the APIs including authentication and authorization to specific APIs, access tracking, and monitoring. Monitoring is particularly important for shared APIs (internal or external) since other user’s applications will depend on the API and will need to have an expectation around SLA for the API.
API Layer Benefits
- Decouple your clients from the data – promotes good service orientation
- Allows creation of REST APIs that can be consumed by mobile and other smart devices
- Private data remain private since the API should only publish a subset of the information. The API controls exactly what data the API publishes
- An API Layer can easily be integrated into existing access controls and LDAP/AD integration.
API Layer Considerations
Its hard to define an API Layer since there is no defined ‘right way’ to do it. The developer needs to define:
- A URL structure
- Authentication mechanism
- Define versioning model (many ways of doing this, no obvious winner)
- Define Data Transfer Objects – the data that gets published over the wire
It’s also hard to change an API since you often don’t control the clients that access it. Changing signatures, URL scheme, authentication or versioning model may result in breaking the API for existing clients.
Recommendation
API Layer is used to decouple clients from backend systems, which is good for modernizing legacy applications, refreshing existing SOAP APIs, migration of backend systems and unifying data sources. API layer is also used to publish data such as reference data, and lookup data form flat files, databases, even Excel spreadsheets. Typically, REST is used for the API Layer, though SOAP provides a WSDL, which defines a contract between client and API.
Processing Grid
The processing grid architecture is a powerful way to perform parallel processing tasks that can scale out. For clarification, scale out refers to the ability to add commodity hardware (nodes) to the architecture for processing more data or events. The processing power must grow linear or near linear as more nodes are added. Grids are typically used for highly computational tasks that can be parallelized such as processing large volumes of market data for trends or collecting device information (such GPS coordinates from phones or cars) for real-time analysis. This architecture is less about integration and more about processing power, however, typically the data came from multiple data sources and funneled into the processing grid.
Processing Grid Characteristics
- All nodes have the same configuration. Each node will process the same data input the same way as the other nodes. This mans it doesn’t matter which node in the cluster processes the data
- There needs to be a load balancing mechanism in front of the grid to feed the nodes. Typically an HTTP load balancer or a JMS or AMQP message queue will be used
- Grids are generally resilient to failure since nodes are interchangeable
- Grids are usually stateless. Sometimes the state is managed for ensuring idempotency i.e. duplicate messages don’t affect the outcome.
- To scale the architecture add more nodes
Processing Grid Benefits
- Straight forward architecture to build, simple deployment
- Works well for a small number of integration points (applications)
- Can be scaled by clustering the hub
Processing Grid Considerations
- Best for high-transaction or data processing tasks
Recommendation
Good for high-transactional or data processing tasks that can be parallelized. Having ESB-like capabilities can help feed data into the grid from different sources. Typically this type of architecture is used for processing structured data whereas Apache Hadoop would be used for unstructured data, however, processing grid is a different architecture to a Hadoop grid where the grid is highly distributed and processing logic is brought to the data rather than the data being moved to a centralised grid.
To wrap this up, I will be talking about how Mule works with these different architectures with my Choosing the right integration/ESB platform post. If you think I should be including other architecture patterns in this series, please let me know.
Follow: @rossmason, @mulesoft



