
Streaming in Mule 4 is now as easy as drinking beer!
There are incredible improvements in the way that Mule 4 enables you to process, access, transform, and stream data. For streaming specifically, Mule 4 enables multiple parallel data reads without side effects and without the user caching that data in memory first.
A lot of people are not familiar with the concept of streaming. So before we get into the specifics of streaming with Mule 4; let’s first go through a couple of use cases that highlight its value.
Example 1: HTTP -> 2 files
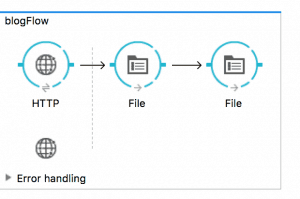
In this simple flow, you receive a content from HTTP (let’s say, a POST with a JSON), and then you write it on two files. What is the result you get after running this? The first file gets written correctly. The second file gets created, but its content is empty.
Example 2: HTTP -> logs -> file

This example receives the same JSON POST, but this time it logs it and then writes it to the file. The output of this flow is what you’d expect. The content gets logged and the file gets written. But is the behavior correct? The short answer is no.
The long, but concise, reason is that in order to log the payload, the logger has to consume the stream completely, which means that the full contents of it will be loaded into memory. By the time the message reaches the file connector, the content is fully in the memory. Most of the time, this is not a problem; but, if the content is too big and you’re loading it into memory, there’s a good chance the app might run out of memory––threatening the stability of the app.
Example 3: HTTP -> scatter-gather -> whatever
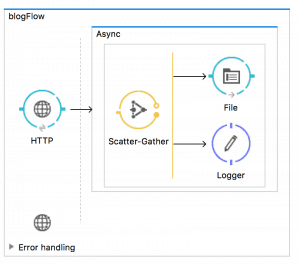
Now, let us try the same example but with a scatter-gather component (for explanatory purposes only). This scenario simply fails. A stream cannot be concurrently consumed by two different threads, therefore the component has only two options:
- a) load the whole stream into memory (like logger does)
- b) fail.
Scatter-gather does the latter.
But why?
This is the part where we really need to understand the implications of the meaning of streaming. There are two problems with consuming a stream:
- It can only be read once
- It cannot be read in parallel
One read only
Heraclitus said that you cannot take a bath in the same river twice. This is because each time you take a bath, the collection of drops that make up that river is never the same. The same is true for drinking a pint of beer. Each sip that you take is one sip you cannot take again. The same thing happens to streams.
The idea of a stream is that in order to avoid loading a potentially large chunk of data into memory completely, you start loading it sip by sip. This means that while you’re still “digesting” (i.e. processing) the first sip, the second sip is already going through your throat (AKA network, disk IO, etc). Not only does this save memory, but it also increases performance. The problem is that the sips cannot be taken back!
Going back to example 1, after the first file-outbound “drinks” the stream in order to process it (write it to disk), the stream becomes empty (no more beer in it). In order to make the example work, you need to place an <object-to-string /> transformer before the first file-outbound processor. This is not obvious, and will force Mule to fully load the contents of the stream into memory.
Also in example 2, the logger has to load the whole thing into memory and replace the message payload. Again, everything got loaded in memory.
Introducing repeatable streams
But what if there was a way to get the pint full again with the same beer?

In Mule 4, you no longer need to worry about answering the following questions:
- Which components are streaming and which are not?
- Is the stream consumed at this point?
- At which position is the stream at anyway?
- What does streaming even mean?
Mule 4 now makes sure that any component that needs to read a stream, will be able to do so regardless of which components already tampered with it. The stream will always be available and will be in its start position.
File Store repeatable streams
File store repeatable streams require buffering, and we have different buffering strategies. Mule now keeps a portion of contents in memory. If the stream contents are smaller than the size of that buffer, then we’re fine. If the contents are larger, Mule backs-up the buffer’s content to disk and then clears memory. This is now the default strategy in Mule 4.
In Memory repeatable streams
You can also take an in memory strategy. When streaming in this mode, Mule will never use the disk to buffer the contents. If you exceed the buffer size, the message will fail.
Reading streams in parallel
So far so good! But we only addressed examples 1 and 2. Example 3 remains unsolved.
Let’s go back to our beer anecdote. So we’re back at the bar and we’re having our pint of beer. Suppose the pint contains 500cc of beer. Since it’s a small world, you happen to run into an old friend at the bar and you start sharing your beer. Using straws, you can drink in parallel, but you’ll never drink the same sip as your friend. And, because you are sharing, when the beer is done you didn’t have your FULL 500cc, which means you lost some of the content.
The same thing happens with streams. If two threads are reading from the same stream at the same time, one thread will take some bytes and the other will take other bytes, but none of them have the full content. Therefore, content has been corrupted.
The new repeatable streams framework in Mule 4 solves this automatically. All repeatable streams support parallel access. Mule 4 will automatically make sure that when ‘component A’ reads the stream, it doesn’t generate any side effects in ‘component B,’ eliminating dirty reads!
Disabling repeatable streams
Although uncommon, there are cases in which you might want to disable this functionality and use plain old streams. For example, your use case may not really require this and you don’t want to pay for the extra memory or performance overhead. Again, you can disable this using the following:
Note that by disabling this feature, all the pitfalls of Examples 1, 2 and 3 are rendered current even if using Mule 4
Streaming Objects
Raw bytes stream is not the only case of streaming that Mule 4 supports. Back in 2013, Mule 3.5 was released and we introduced the concept of Auto-Paging connectors. This was a feature that allowed connectors, such as Salesforce, to transparently access paginated data. This is a form of streaming! Under the hood, the connector fetches the first page, and when it’s consumed it fetches the next one, discarding the prior pages from memory. In essence, this is exactly the same as streaming a file from FTP.
File Store Auto Paging
By default, you will now get a buffer which holds a number of objects into memory and uses the disk to buffer the rest:
Just like before, you can also do this fully in memory:
Buffer Sizing
Note, however, that buffer sizing requires a different approach here. In the prior examples, all buffer sizes were measured in bytes (or a derivative unit such as KB). In this case, we talk about instance count.
Object Serialization
In order for the FileStore strategy to use the disk as a buffer, it needs to serialize the streamed objects. Does this mean it only works on objects that implement the java.io serializable interface? Not at all. Just like the Batch module, this feature uses the Kryo framework to serialize things that the JVM cannot serialize by default. Even though Kryo does a lot of black magic, it’s neither all powerful nor a silver bullet. Some things just can’t be serialized, so try to keep your objects simple!
Try it Now!
- Download Mule 4 and Studio 7 Beta
- Watch a Demo-driven Webinar on Mule 4 and Studio 7 Beta
- Learn more about the role of DataWeave in Mule 4 Beta
- Discover new features in Studio 7 Beta



