
Building on the success of CONNECT 2015 in San Francisco, we’re happy to announce the final release candidate for Mule 3.7 and Anypoint Studio June 2015. Planned GA is now less than a month away!
Highlights of this release:
- DataWeave: a new language and module for querying and transforming data
- Metadata enabled payloads: attach metadata to payloads for context-aware connectivity
- Non-blocking HTTP proxies: Scale APIs with higher concurrency
- Java 8 support: Mule 3.7 is compliant with both Java 7 and Java 8
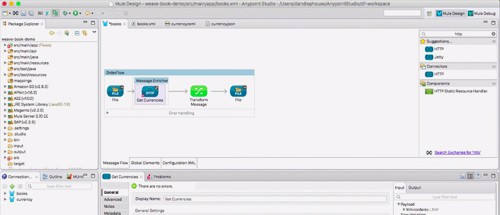
Introducing DataWeave
As organizations struggle to deal with the proliferation of applications and APIs inside their organization, being able to integrate data at speed and scale plays a pivotal role. Specifically, we’re seeing with our customers a need to:
- connect applications in ways that are maintainable over the long term
- integrate in real time APIs and do batch tasks such as data ingestion or synchronization
- handle a variety of data sources – from new RESTful APIs with JSON to XML to EDI.
As we looked at all these problems, we realized that there was nothing on the market today that sufficiently addressed these needs. After years of hands on experience and several cycles of development, I’m excited to announce what we believe to be the solution: DataWeave, a simple, powerful way to query and transform all types of data.
At it’s core, DataWeave is a JSON-like language that’s purposefully built to be easy to write, easy to maintain, and capable of supporting simple to complex mappings for any data type. And it’s built with a highly performant engine that supports both batch and real-time data integration.
The DataWeave language supports a variety of transformations, from simple one-to-one mappings to more elaborate mappings including normalization, grouping, joins, deduplication, pivoting and filtering. It also supports XML, JSON, CSV, Java and EDI out of the box.
It is fully integrated with Anypoint Studio, making on-ramp and continued development easy. It includes full integration with DataSense, allowing payload-aware development with auto-completion, auto-scaffolding of transforms, and live previews.
Underneath, DataWeave includes a connectivity layer and engine that is fundamentally different from other transformation technologies. It’s contains a data access layer that indexes content and accesses the binary directly, without costly conversions, enabling larger than memory payloads, random access to input documents and very high performance. NOTE: currently, reading larger than memory XML is not yet supported.
The DataWeave universal language for data access can not only be used for transformation, but also for querying data throughout your flow. Using the dw() function, you can quickly query data and use it to log information from payloads, route data, or extract it for message enrichment.
In short, there’s not much you won’t be able to do with DataWeave! If you’re ready to get started, jump over the DataWeave tutorial or take a look at the comprehensive reference documentation!
A metadata aware Mule
In parallel with our DataWeave development, we’ve been working to make metadata a first class citizen inside our tooling and runtime. Both Mule and Anypoint Studio are now more metadata aware. Mule now tracks the payload type internally, e.g. is it XML or CSV, along with the data, so that metadata can be used during transformation. You can also manually set this type using set-payload, set-variable, etc. Also, from Anypoint Studio, you can now supply design time metadata to any message processor and declare the type of your payload, ensuring that Studio can provide you content-assist capabilities and that you have visibility into your payload everywhere.
Non blocking processing strategies
A new non-blocking processing strategy has been added for HTTP proxy scenarios. We’ve been making all our internal components asynchronous, so you can scale your APIs to higher concurrency with minimal tuning inside the runtime.
Java 8 support
Continuing on the work we did with the 3.6 release to make Mule Java 8 complaint, now all 3rd party libraries Mule uses fully support Java 8. As a result, these libraries have been upgraded, making Mule fully Java 8 compliant.
And much more:
- Support for custom serializers and a new Kryo serializer which boosts performance for HA, VM Queues and ObjectStore
- HTTP now supports NTLM authentication and pre-emptive authentication for the HTTP request configuration
- WS-Consumer support for signing and encrypting payloads with WS-Security
- Support for specifying the default processing strategy
- When adding dependencies for connectors, you can now directly search the Maven repository to find the appropriate dependency and Studio will automatically add it to your POM.
- Many internal libraries have been upgraded, most notably Spring has been upgraded to Spring 4.1.6 and CXF has been upgraded to 2.7.15.
- Lifecycle improvements: the object lifecycle is now applied on registered objects in the correct order, taking into account both object types and declared dependencies. Also, dependency injection is now supported on all registered objects as defined by JSR-330. Non registered objects can also be injected through the new Injector api.
Get Started
- Download the new release of Anypoint Studio »
- Download the Mule 3.7.0 RC »
- Read the release notes for Anypoint Studio and the 3.7.0 runtime.
- Read the documentation for the release
We look forward to your feedback in this post’s comments and in our forum. Happy connecting!



