
As mentioned in the first post of this Mule 4 blog series, Mule developers build integration solutions that must cater to high volumes of data. The newest version of our runtime engine reflects that – Mule 4 uses reactive programming to enhance scalability so our developers can deliver smooth experiences for their users. Let’s dive into how it works.
Consider Mule flow to be a chain of (mostly) non-blocking publisher / subscriber pairs. The source is the publisher to the flow and also subscriber to the flow as it must receive the event published by the last event processor on the flow. The HTTP Listener, for example, publishes an event to the first event processor on the flow and subscribes to the event produced by the last event processor on the flow. Each event processor subscribes and processes in a non-blocking way.
Back pressure
Consider for a moment a natural phenomenon called back pressure which occurs in confined spaces like pipes. It opposes the desired flow of gases through that space. Mechanical engineers have to design the likes of exhaust pipes with this in mind so that the gas can move through the confined space with the least amount of impedance.
This forms the basis of a metaphor key to the reactive programming model. In order to allow the subscriber to consume the event stream without being overwhelmed by too many events, the subscriber must be able to apply back pressure, in other words signal to the producer to “please slow down.”
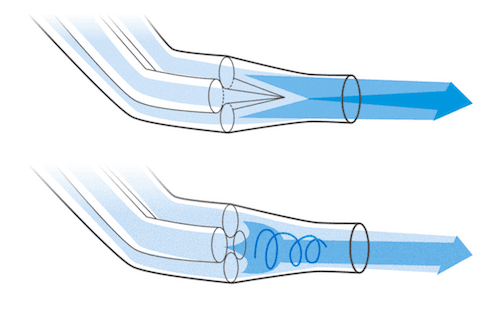
Automatic back pressure in Mule 4
Mule 4 applications are automatically configured so that the event source receives a back pressure signal when all threads are currently executing and no free threads remain in a required thread pool. In practical terms this will trigger the HTTP Listener, for example, to respond with a 503 – “Server busy”, and the JMS Listener will not acknowledge receipt of a message. OutOfMemory errors are avoided as a result of this configuration.
Manual back pressure in Mule 4
Mule developers can also configure each event processor to signal back pressure to the event source through the “maxConcurrency” attribute. This configuration affects the number of events that can pass through the event processor per second.
Non-blocking operations in Mule 4
Non-blocking operations have become the norm in Mule 4 and are fundamental to the reactive paradigm. The wisdom here is that threads, which sit around waiting for an operation to complete, are wasted resources. On the flip side, thread-switching can be disadvantageous. It is not ideal that each event processor in a Mule application flow execute on a different thread as this will increase the latency of the flow execution. However, the advantage is that a Mule flow can cater to greater concurrency because we keep threads busy with necessary tasks.

A simple metaphor for non-blocking operations in a Mule flow is the tolling systems on highways. Visualize a highway with multiple lanes filled with cars and a toll stop crossing the width of the highway. Some lanes go through the manual tolls. Others go through the e-tolls. Each lane on the highway is like a thread. Each car is like an event being processed by those threads. A car stopped at a manual toll is like an event going through a blocking operation. The database module’s read operation, for example, blocks and waits for responses to come back from the database server. That’s a bit like going through the manual toll. You stop your car, you pay, and the cars have to backup behind you while you wait for your transaction to be processed. The e-tolls, in contrast, allow you to drive straight through.
These are like the non-blocking HTTP Requester. It sends off requests on one thread but that same thread is immediately freed up and does not wait for a response from the server. The net-effect is greater concurrency and throughput – more traffic flowing on the highway!
I’ll explore thread management and auto-tuning in Mule 4 in my next blog. To access full insights, download New foundations for high scalability in Mule 4.



