
The word around the water cooler is that a queue has yet to be created that I don’t like. Whether it’s RabbitMQ, AWS SNS/SQS, or Google Cloud Pub-Sub, regardless of the implementation, I love queues to death, gobble, gobble…I’ll eat ‘em up. I mean, what’s not to like?
Not too long ago at a due diligence review, I was presenting my idea for a mission-critical enterprise architecture. The Pub-Sub pattern played a critical role in my thinking. So I did my dog and pony presentation and things seemed to have gone swimmingly well, then later that day one of the attendees at the presentation stopped by my desk and told me, “I like your thinking, but I gotta tell you, I hate queues. I think they suck.”
I was dumbstruck. My world shook. I felt as if I were a five year old and someone had just told me there was no Santa Claus, and I could not imagine a world with no Santa Claus.
My immediate reaction was to flip the bozo bit and dismiss his comment as one made by a guy who had no idea as to what he was talking about, but, I knew the background of the person. He was no dope and he had a boatload of experience. He’s worked in telecom for a very long time, on very large systems. Given his background and expertise, I’d be dumb not to consider his position. Going against every impulse had to defend my ego, I said, “Oh, why?”
And he told me.
Using a Queue is Lazy
“Basically using a message queue to facilitate interservice communication is lazy,” he said. “You should just have one service send a HTTP POST to the other service that wants the information. For a little more work, you get a lot more bang. Let me show you on the whiteboard.”
Figure 1 shows what he drew.
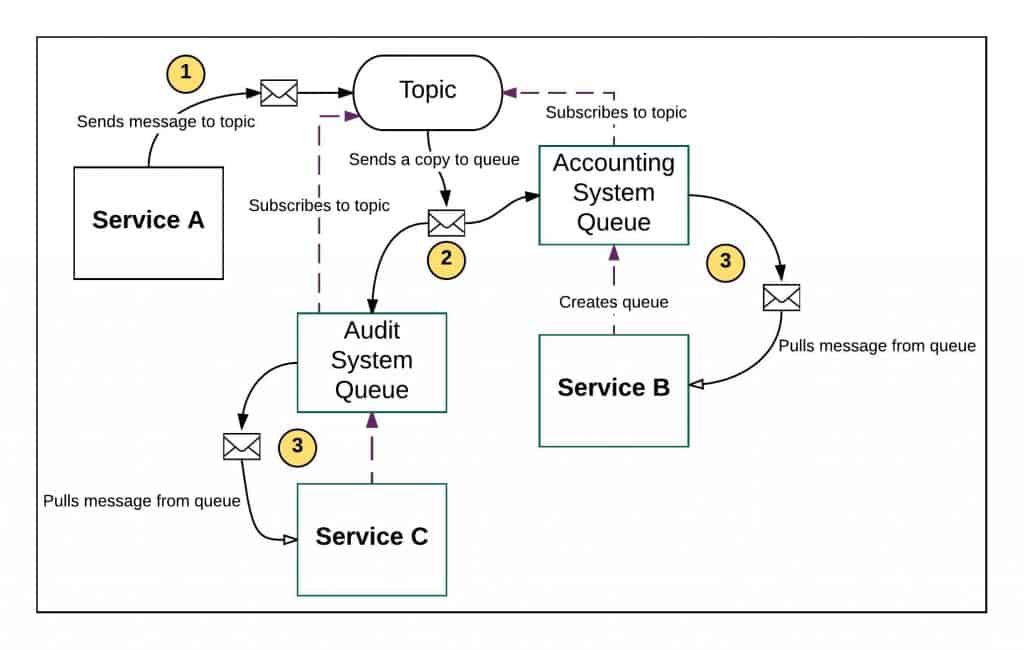
“In a typical Pub-Sub pattern you have a service that sends a message to a topic (1). If there are no queues subscribed to the topic, the messages accumulate, eating storage resource. Yes, you can configure a topic to delete a message after a time, but still, the topic is responsible to store the message.
“Luckily, in this case I’ve diagrammed, we have a queue subscribed to the topic. The topic could be a list that’s populating quickly such as real-time stock transactions for a stock brokerage firm. The topic will send a copy of the message to the subscribers it knows about (2). For example, the brokerage’s accounting system as well as another system belonging to the brokerage’s official auditor. Then, once all subscribers get the message, the topic will flush the message.
“Now we have the message sitting in the queue waiting for the Service bound to the queue to pull the message (3). That’s a lot of work. Not only do we have to devote resources to getting the message from the publishing service to the ultimate consuming service(s), but the consuming service has to create the queue and then subscribe the queue to the topic.
“For the same amount of work or less, the creator of the message can send it directly to the interested service, as I show in Figure 2.”
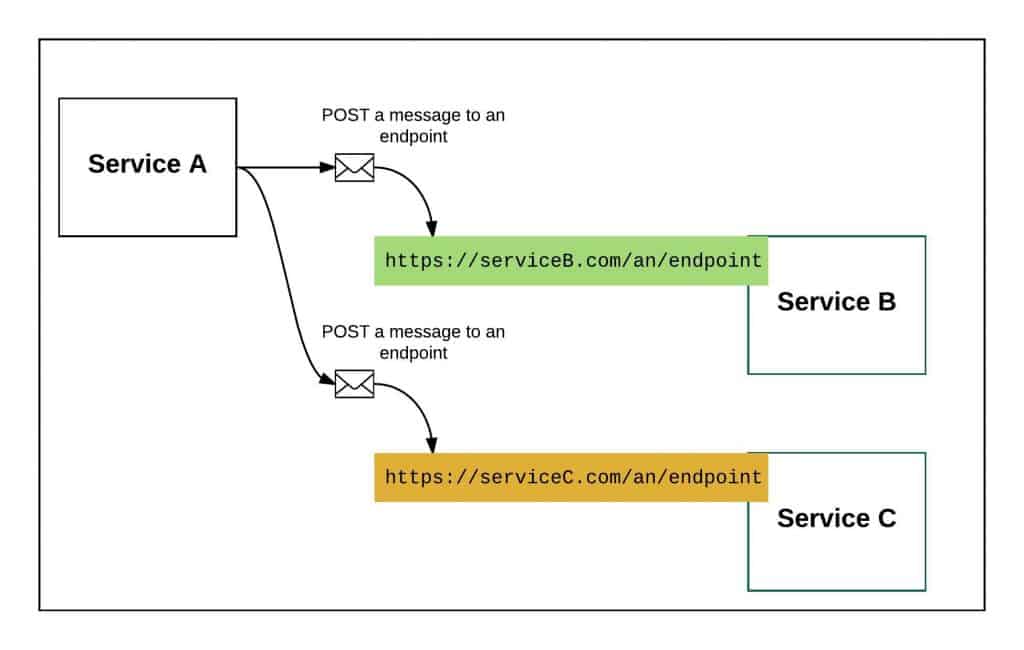
Not one to take things at simple assertion, I decided to put up some opposition to the idea.
Things are Not as They Seem
“Look”, I say. “The virtue of the Pub-Sub pattern is that the publisher of the message knows nothing about the consumer of the message. The publishing service just sends the message to the topic and that’s that. Any subsequent action is unknown to the publisher. Millions of queues might be subscribed to the topic. The queues can drop in and out as they need to. The elegance is that the publishing service does not have to handle that dynamic nature that goes with the registration of subscribers. The burden of subscriber registration is left to the topic.”
“My friend”, he says. “Things are not as they seem. Let’s get real world here.”
He continues drawing on the whiteboard with his back facing me. “Most enterprises that operate at large scale do not roll-their-own in terms of topic/queue hosting. They use a service provider such as AWS. Every topic in play costs money and the storage on those topics cost money. Thus, you are absorbing the storage costs of messages until all subscribers pull the messages down. That’s one little hidden factor, the storage costs you incur. Here is another: the publisher of the messages is incurring a cost for registering consumers that want your information. Yes, you are incurring the expense indirectly, but there is a real expense. You’re not going to let just anybody subscribe to a topic. At the least, if you are using AWS, you are going to have to grant interested consumers rights to subscribe to the topic. There is no magic here. That process needs to be managed, at least in terms of approval. So for the same labor, why not have services interested in your information register to your service directly? Take a look what I just wrote out in Figure 3.
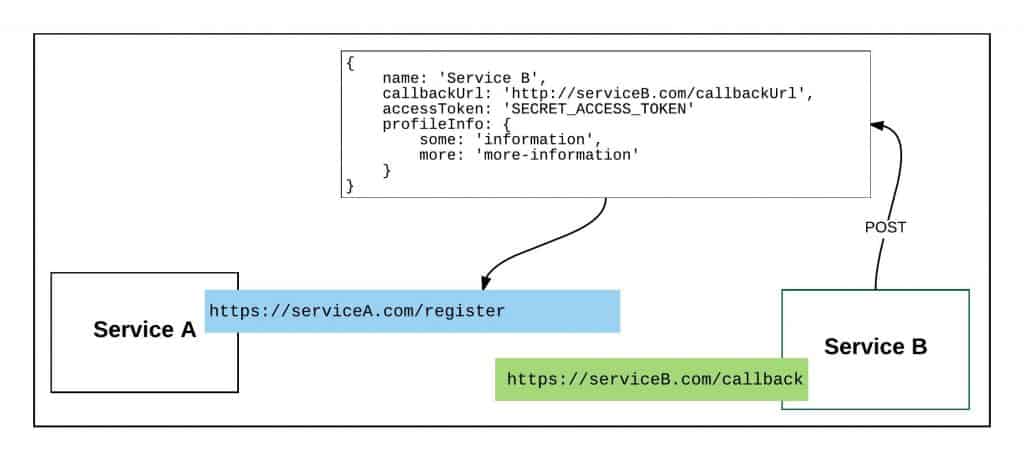
“Registering a consumer directly to a publishing service requires telling the publishing service the URL to where published messages are to be sent. And yes, you might need to include some security information in order for the publisher to be able to access the URL, but this is a common pattern.
“Of course you do have to implement a way to do subscriber list management, but you’re paying for that already. For the half-day it will take a developer to create a way to register list members and send information to those members, you’re making that expense back in the savings you incur by not having to store any messages at all. You’re shifting that message handling and storage cost to the consumer.”
I thought about what he was saying. As much as I was resisting, he was beginning to make sense. So to drive the point in a little deeper, he went to another whiteboard and drew out a table, shown below:
Table 1: A comparison features between Using Pub-Sub and Direct Access to an Endpoint.
| Using Pub-Sub | Direct Access to Endpoint | |
|---|---|---|
| Consumer needs to know location of get message | Yes | Yes |
| Consumer needs to register to source | Yes | Yes |
| Source knows about consumers | Yes | Yes |
| Allows late binding | Yes | Yes |
“Take a look at this table”, he says. “Whether you used Pub-Sub or Direct Access To an Endpoint, parties interested need to know the location of a source. In the case of Pub-Sub, the consumer needs to know the topic address and have rights to the address. In Direct Access To an Endpoint the consumer needs to know where the messages are coming from to register to the publishing service to get information. With Pub-Sub, you need to register, too, to a topic. But let’s face it, no matter what, your consumers are registering to an address. It’s a wash.
You might say that Pub-Sub is agnostic in terms of knowing about who is consuming messages. It may seem that way, but really when you think about it, the publisher does have knowledge. That knowledge resides in the topic. Remember, you own the topic and are responsible for granting access to topic. Of course you know who your consumers are.
As far as the benefit of late binding goes, in Pub-Sub you subscribe to the topic, in Direct Access To an Endpoint you register to the service sending the messages. Don’t want the information anymore? Unsubscribe or unregister. Same labor.”
I could feel my mind slowly changing. Obviously he had thought things through a great deal. But, still I had to ask, “Are you telling me that queues are a waste of time and I should hate them too?”
“Not exactly”, he replied. “There is a place for queues.”
A Place for Queues
“The place for queues is in the consumer,” he says. He went back to the whiteboard and scribbled away, creating Figure 4.
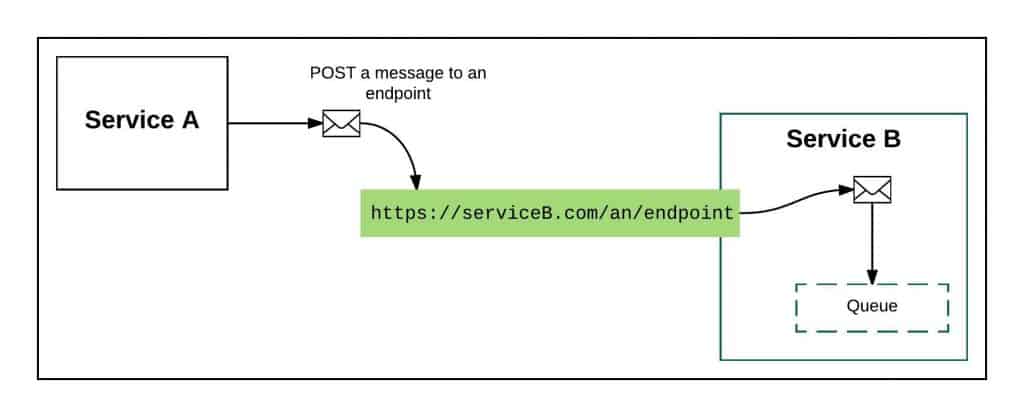
He continued, “Remember, the fundamental benefit of not using topics or queues for interservice communication is that we don’t have to incur resource costs. We push all of it onto the consumer. However, a service that consumes our information might want to use a queue, particularly if that service has a lot of parallel processes using the information we are delivering. The important part here is that the consumer of the information is incurring the costs associated with its need. Your job is to deliver information. The service’s job is to consume it.”
“Makes sense”, I replied, feeling humbled.
What It All Means
As I stated at the beginning of this piece, I really like queues and topics. Changing my mind is not easy. I think the same can be said for most of us who have been doing this sort of work for a long time. Yet having the ability to examine a new idea and adjust accordingly is the sign of a mature professional, even if it requires that we say those humbling words, “You are right and I am wrong.”
I approach using queues differently now. I don’t hate them. In fact, I still like them. What’s changed is the way I like them. It’s like when I first learned to use a hammer—everything was indeed a nail. Now, I can tell a nail from a screw or a grommet, and I know enough to use the right tool for the situation.
Sometimes growth is hard. But, it beats the alternative.
This article first appeared on ProgrammableWeb.



