
IT is under continuous pressure to keep systems available and maximize the uptime to ensure users have an unmatched experience. With the growing number of user experiences (such as 24/7 services, mobile, and eCommerce), every moment of downtime translates to loss in revenue or a missed opportunity.
To define a stable and scalable system, one must analyze and focus on attributes like system availability, desired system uptime and acceptable downtime (outage), and time and cost required to recover from the downtime/outage and recovery point. To understand more on system availability, see the table below which highlights how the availability rate for a system translates to acceptable outage/downtime.
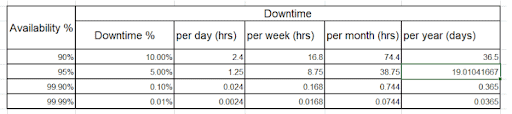
Recovery point objective (RPO) and recovery time objective (RTO) are the two key business continuity attributes, and highly dependent on business processes and objectives. RPO is a measure of how often the system should be backed up to minimize data loss during a disaster. RTO is a measure of how long a business can survive downtime before causing significant damage. For example, a customer-facing channel in a competitive market will have a lower RTO compared to an internal low-priority system that has no impact on business operations.
As we aim to lower the RTO and increase system availability, complexities arise, more maintenance is required, and operational costs go up. These infrastructure complexities could be inter- or intra-region data-centers, redundancy across different hardware and software components, backups, deployment and maintenance of applications, process automations, and dynamic scalability.
High availability and reliability
In order to achieve maximum uptime enterprises rely on redundancy, invest and deploy in multiple servers (kubernetes, VMs, bare metals) — which helps meet the availability SLAs and also improve system performance and the user experience. High availability defines the characteristics of a system that continues to provide operational capabilities based on the defined SLAs and is achieved through redundancy, deploying the services on a minimum of two servers. This redundancy provides a means for extended uptime (availability) of the services during day-to-day business operations, un/planned maintenance activities and also provides a platform to distribute work loads between the systems, enabling failover and zero message loss and horizontal scaling.
To understand how we can achieve high availability and reliability in MuleSoft, consider the following fictitious order processing use case for a large consumer base. This is realized through a series of APIs (both in-house and third-party). The external APIs require high availability, and order capture flow must provide reliability against message loss. The APIs used during fulfilment process large volumes of data and consist of a few CPU-intensive processing steps.

SLAs play an important role in determining the application and system design. If we look closely the use case lists the following as SLAs:
- High availability
- Zero message loss
- Performance
In an on-premise MuleSoft deployment topology, the high availability (service redundancy) for the stateless APIs can be achieved using server groups along with a front-end load balancer. However, zero message loss or reliability pattern and work-load sharing are required to maintain the state of the transaction which is achieved using Mule clusters. Under the hoods, Mule clusters rely on Hazelcast implementation to coordinate and synchronize state between the different nodes in the cluster.
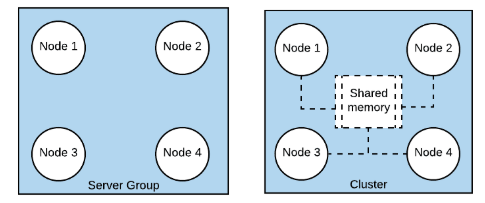
Server group is a set of servers that provide a logical deployment unit.Cluster is set of mule servers that provide a logical deployment unit, high availability and failover capabilities through distributed shared memory

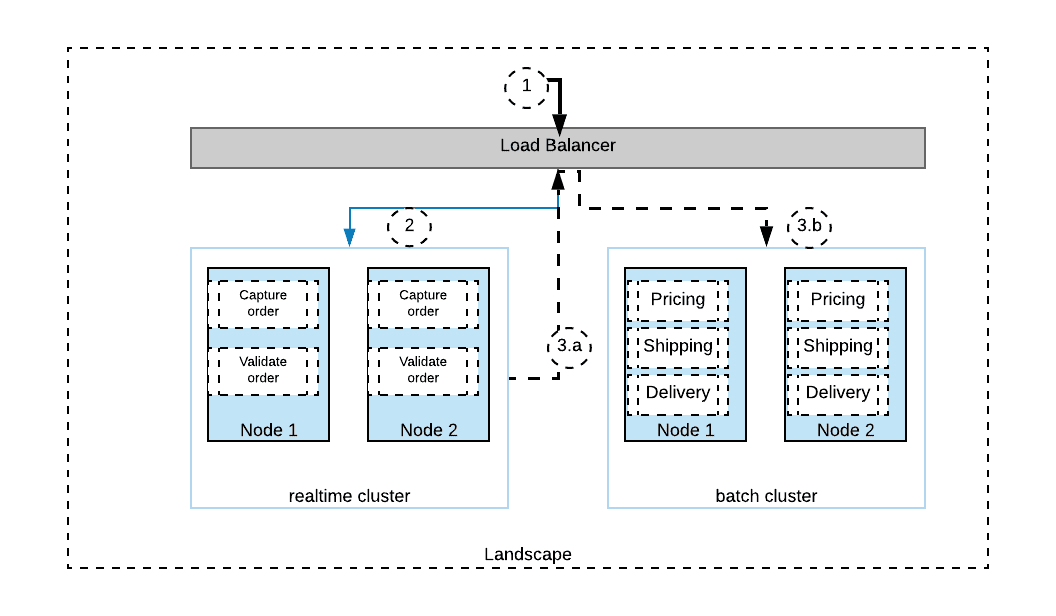
As a best practice, it is recommended to do real-time deployments and batch processes/ APIs on separate Mule environments. This provides required uptime and performance for real-time APIs through dedicated computational resources (and not shared with CPU-intensieve batch jobs) and also provides a platform to scale efficiently.
- High availability: Deploying an enterprise-scale load balancer in front of the Mule cluster will provide the redundancy required to support the desired high availability. Number of nodes in the cluster will depend on multiple factors — such as expected load, expected response time, and peak load. Based on the load balancer algorithm the requests are distributed and served by all the nodes in the cluster. In case of a node failure, the load balancer can route all the requests to remaining nodes in the cluster. When all traffic is handled by a single node there is a major performance impact on the overall system.
- Zero message loss (reliability): Mule runtime engine clusters provide a mechanism for failover in case the node processing the request goes down. This is achieved through distributed shared memory via Hazelcast. To make this happen, applications must be designed in a way to capture the state of a running process/instance, which can be picked up by another running node in the cluster. This can be achieved by using VM or JMS transport within the flows. VM provides in-memory and a cluster-aware transport support. Using persistent queues, the data is processed as long as one node member in the cluster is up/running to process the requests. However, if the entire cluster goes down the messages will be lost. To avoid message loss in case of complete cluster failure, external persistence should be used. It introduces latency as opposed to VM but provides more reliability. Consider the below diagram where an order capture request is broken into two flows — OrderCapture — exposed via HTTP listener to persist the order in the VM queue and processOrder, which consumes the orders from the VM queue to persist in the Orders table.
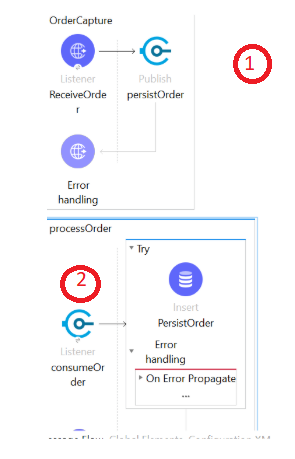
The flow of events is:
- HTTP listener accepts the request and persists the message in the memory using VM transport. If the request fails to persist, Mule will return an error for the client to retry.
- If the message is persisted, one of the nodes in the cluster will consume the message and process the message. The message will only be removed from the queue when processOrder Mule flow completes the transaction.
- In case of a node failure while processing, the processOrder Mule flow the message is still persisted and processed by another node in the cluster.
- If this was deployed on a server group — the node processing the request will not be picked up by another node in the server group, which will result in message loss.
- If the entire cluster fails, the message is lost.
- If the thread between client and server breaks (node that received the request goes down) after the data was published to VM, the processing of the processOrder flow will continue in a different node in the cluster.
- Workload distribution (performance): In our original use case, order fulfillment is a nightly run with a large number of records/events flowing between processes. To ensure system reliability, the applications are designed to run across clusters and workloads that can be distributed between multiple nodes in the cluster, so no node is overloaded with requests and compromises the sanity of the systems. In this scenario, we can make use of scheduler components which can trigger the interface and select the records from the Datastore and publish to VM transport to distribute workload across multiple nodes in the cluster. To achieve this lets break the processing into two flows: 1) retrieveFulfillment to select the orders and publish to the VM and 2) processFulfillment to process the orders one by one.
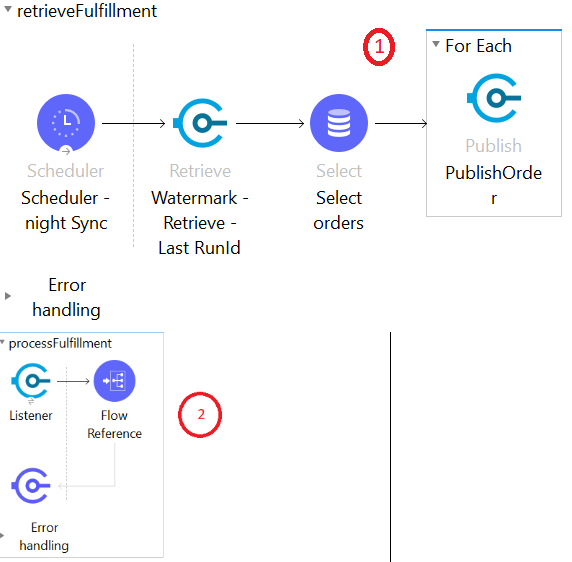
- All the nodes in the cluster run in active mode. However, components like pollers and schedulers only execute on the primary node. If the primary node goes down, one of the other nodes in the cluster will assume the role of the primary and trigger the remaining schedules/ polling components.
- In this case, the Scheduler – night Sync in retrieveFulfillment Mule flow is only processed by the primary node.
- The nodes in the server group do not coordinate with each other and will result in duplicate message processing.
- In the above diagram, if the node processing the request in the processFulfillment Mule flow is shut down before the transaction is committed, other nodes in the cluster will pick up the request and process it. This is made possible using cluster aware VM transport. Keep service idempotency in mind when dealing with transaction boundaries.
- If only one node from the entire cluster is available, it will act both as a polling and processing node, which impacts system performance.
Note: Setting up a cluster alone doesn’t provide failover and zero message loss capabilities. Application design plays an important role to support workload distribution and zero message loss. Consider a scenario where a process is triggered using a file poller and the file is deleted as soon as the file poller is complete. If the data is not persisted before the file is deleted and the node in the cluster shuts down this will result in message loss.
If you’d like to learn more about the range of deployment architectures MuleSoft supports, please watch our Friends of Max video below.

To learn more about achieving high availability and reliability on-prem, check out the full-length tutorial.



