
Tyler Haigh, DevOps Engineer at New South Wales Health Pathology (NSWHP), spoke at our MuleSoft CONNECT Digital event in APAC. He has more than four years of experience using Anypoint Platform. Recently, his projects focused on creating reusable DataWeave scripts for healthcare acceleration at NSWHP. In this blog, he shares how he uses DataWeave and MUnit testing to improve NSWHP healthcare messaging systems and patient experience.
Over the past two years, NSWHP — in collaboration with Deloitte — has embarked on a journey to develop an integrated healthcare solution using HL7-V2, FHIR, and MuleSoft. Traditionally, integration projects with source hospital systems are achieved using point-to-point integrations. Making changes to these integrations is generally impeded because each hospital system is implemented differently, with its own semantics. For our project, we identified the need to normalize the data from our source systems, prior to mapping and ingesting it into DataWeave. This would ensure we didn’t need to write bespoke logic for each hospital system — rather it was integrated into the broader solution.
We also needed to ensure that each patient event is processed in the correct order as it is received from the source systems. This ensures their care is delivered based on accurate information. With the goal of moving to the digital era of healthcare, we needed to connect and integrate with cloud services to perform tasks, such as sending notifications to our end users.
Lastly, when designing the solution, we needed to ensure reuse across NSWHP for future projects utilizing similar integration services.
What we built with Anypoint Platform
To resolve these challenges, we used Anypoint Platform and a range of Azure services to establish a microservice-style architecture for our integration platform. Specifically, we used the MuleSoft HL7-V2 Toolkit for our HL7-V2 messaging integration with our source hospital systems. We also used the Mule Healthcare Accelerator for RAML FHIR APIs to create this architecture and accelerate our development of new integration services. By architecting the solution using API-led connectivity, we built services encapsulating logic and rules for our source hospital systems to allow for normalization and common model definition. Utilizing Azure Service Bus Queues for ordered Message Processing, we built a custom Mule connector using the MuleSoft DevKit. Our solution also incorporated DataWeave to transform HL7-V2 to FHIR as well as a reusable platform service in MuleSoft to create an Azure Notification Hub for mobile app notifications.
How our team utilized DataWeave scripts and built our FHIR Resources is unique and requires an understanding of the core differences between HL7-V2 and FHIR standards.
Difference between HL7-V2 and FHIR
HL7 (Health Level 7) is an international standard for the transfer of clinical data between healthcare providers. Hospitals often use different systems to manage their patient admissions, lab results, medical record management, and billing of a patient. However, all of these systems need to communicate with each other when they receive new information. Thus, HL7-V2 is the messaging standard implemented by these hospital systems to ensure all of their systems can communicate. It is designed to be an event-based-trigger messaging system with a strong focus on state machine logic capturing the patient’s journey.
As an example, the HL7-V2 ADT (admissions, discharges, and transfers) message type can capture different events associated with the patient such as:
- When the patient is first admitted to the hospital
- When the patient is transferred between hospital wards
- When the patient’s information is updated
- When the patient is discharged from a hospital
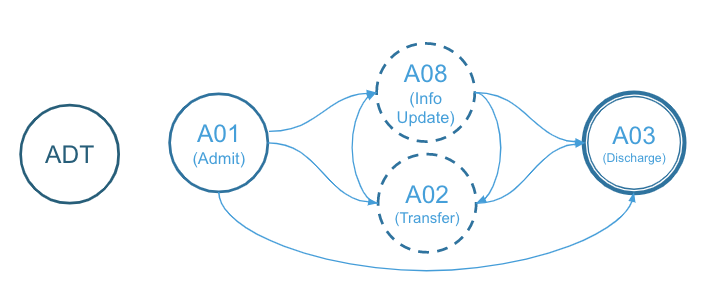
Comparably, FHIR (Fast Healthcare Interoperability Resources) is a different type of HL7 messaging standard designed for describing resources and defining an API for electronic medical records. One of FHIR’s main goals is to facilitate interoperation between legacy healthcare systems. This makes it easier to provide healthcare information on a variety of resources by allowing third-party developers to implement new medical applications and easily integrate them into existing applications. While built on previous data formats from HL7-V2, FHIR is easier to implement due to its core design utilizing HTTP and REST protocols with a strong focus on JSON and XML for data representation. It should be noted that a single HL7-V2 message can affect multiple FHIR resources such as patient resources, patient encounter resources, and location resources.
Example of a FHIR Structural tree:
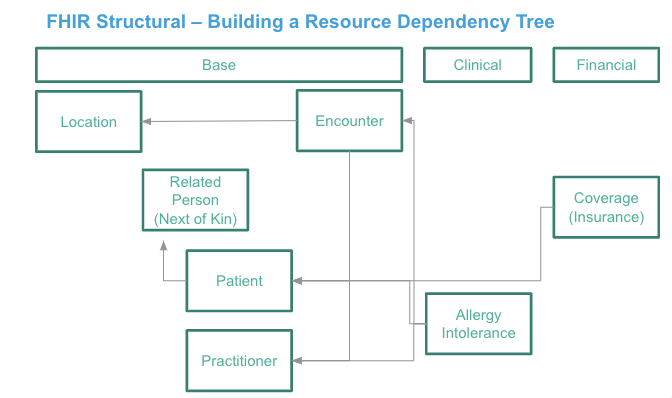
How NSWHP integrated MuleSoft with core hospital systems
With these two messaging systems and their frameworks in mind, let’s dive into how NSWHP utilized the MuleSoft HL7-V2 Connector to ingest messages from hospital systems into our integration layer. Below, we have a standard MuleSoft flow that we implement into each of our system layer adapters.
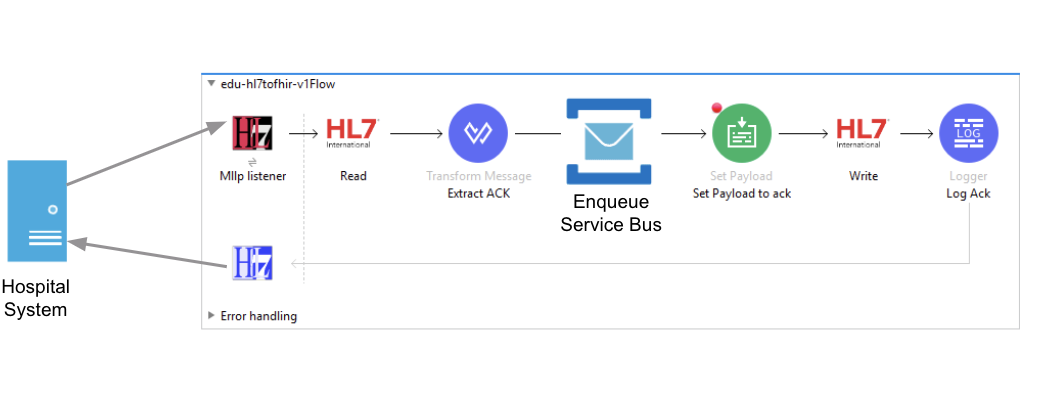
First, the hospital system emits a HL7-V2 message over a low level TCP channel using the MLLP (minimum lower layer) protocol. Then, the Mule MLLP Connector receives the message over the TCP socket. Once this occurs, the Mule EDI Message Processor reads the source message (in HL7 ER7 pipe-and-hat format) and transforms it to a HashMap data structure to prep and send into our DataWeave function. The source message is immediately enqueued to a FIFO messaging queue. This ensures we process patient messages in the correct order. At this point in the flow, NSWHP developed a custom MuleSoft connector using the Mule DevKit to connect with Azure’s Service Bus platform. Afterwards, an immediate Commit Acknowledgement (CA) is returned to the hospital system. This allows our integration layer to perform asynchronous message processing. The message can be processed in a separate thread without creating a bottleneck. We can later issue a full Application Acknowledgement (AA) asynchronously through the use of Azure topics and subscriptions after the message has been processed downstream.
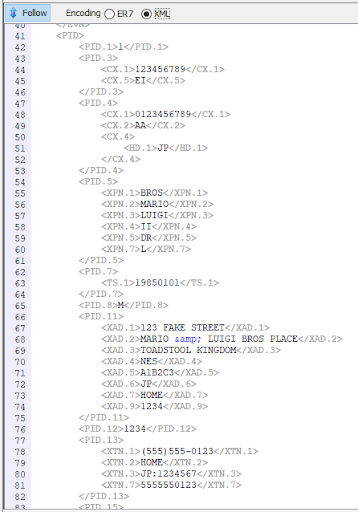
Below is a sample HL7-V2 message as described above. This is generated by the Hapi Test Panel — a free HL7-V2 Message Editor.

In Hapi Test Panel, we can then switch between the ER7 (Pipe and Hat) format and its XML equivalent. Notice in the image below, we have a nested data structure where we define the patient’s name, their date of birth, gender, and address.
Using Anypoint Platform, the MuleSoft EDI Connector provides a way to read the source ER7 message and generate a structured hashmap of data which can be used in DataWeave. This is achieved using the Mule 4 HL7-V2 EDI Schema Language which supports both standard (strict) HL7-V2 and Lax HL7-V2 (a more relaxed schema definition).
Below is a sample HL7 message in Pipe and Hat format.
We can then use DataWeave to transform our source HL7-V2 message. Below is an example of our original DataWeave script. Whilst this DataWeave would be fine for a single project, or if only defined once, it is quite large and quite complex to maintain.
If we need to define a DataWeave transform for other FHIR Resources that make use of similar mapping constructs, we would need to copy-paste chunks of code and work from scratch each time. Furthermore, as changes are made to the DataWeave script, we need to ensure that no breaking changes are introduced.
%dw 2.0
output application/json
---
{
// Patient Resource
// See https://www.hl7.org/fhir/stu3/patient.html for Patient Specification
resourceType: "Patient",
id: uuid(),
identifier: payload.Data.ADT_A04.PID."PID-03" map (value, index) -> {
use: "official",
"type": {
coding: [{
code: value."CX-05" default null
}]
},
value: value."CX-01" default null
},
active: true,
name: payload.Data.ADT_A04.PID."PID-05" map (value, index) -> {
use: if (value."XPN-07" != null)
if ( ["D", "C"] contains upper (value."XPN-07")) "usual"
else if ( ["L", "OR"] contains upper (value."XPN-07")) "official"
else if ( ["T", "TEMP"] contains upper (value."XPN-07")) "temp"
else if ( ["P", "N"] contains upper (value."XPN-07")) "nickname"
else if ( ["ANON", "S"] contains upper (value."XPN-07")) "anonymous"
else if ( ["OLD", "NOUSE", "BAD"] contains upper (value."XPN-07")) "old"
else if ( ["M"] contains upper (value."XPN-07")) "maiden"
else "unknown"
else null,
text: if (value."XPN-02" != null) value."XPN-02" else ""
++ " "
++ (
if (value."XPN-01"."FN-01" != null) value."XPN-01"."FN-01"
else if (value."XPN-01") value."XPN-01"
else ""
),
family: if (value."XPN-01"."FN-01" != null) value."XPN-01"."FN-01"
else if (value."XPN-01") value."XPN-01"
else "",
given: [ value."XPN-02" ],
suffix: if (value."XPN-04" != null) [value."XPN-04"] else null,
prefix: if (value."XPN-05" != null) [value."XPN-05"] else null
},
gender: if (payload.Data.ADT_A04.PID."PID-08" != null)
if (upper(payload.Data.ADT_A04.PID."PID-08") == "M") "male"
else if (upper(payload.Data.ADT_A04.PID."PID-08") == "F") "female"
else if (upper(payload.Data.ADT_A04.PID."PID-08") == "O") "other"
else "unknown"
else null,
birthDate:
if (payload.Data.ADT_A04.PID."PID-07"."TS-01" != null)
if (sizeOf(payload.Data.ADT_A04.PID."PID-07"."TS-01" default "") > 8)
(payload.Data.ADT_A04.PID."PID-07"."TS-01" default "") as Date { format: "yyyyMMddHHmmss" } as String {format: "yyyy-MM-dd"}
else
(payload.Data.ADT_A04.PID."PID-07"."TS-01" default "") as Date {format: "yyyyMMdd"} as String {format: "yyyy-MM-dd"}
else null
}
We decided to switch to using DataWeave modules (scripts) to create smaller, more reusable code modules. These scripts can be reused in and across other DataWeave functions. We now have an increased ability to unit test the DataWeave functions and to package our DataWeave scripts folder into a redeployable archive .jar package. Our team can now define these mappings in one place and reuse them throughout our integration layer.
%dw 2.0
import modules::gender
import modules::humanName
import modules::timestamp
import modules::extendedCompositeId
import modules::boolean
var pid = payload.Data.ADT_A04.PID
output application/json skipNullOn="everywhere"
---
{
// Patient Resource
// See https://www.hl7.org/fhir/stu3/patient.html for Patient Specification
resourceType: "Patient",
id: uuid(),
identifier: pid."PID-03" map (value, index) -> extendedCompositeId::fhirIdentifierFromCX(value),
active: true,
name: pid."PID-05" map (value, index) -> humanName::humanNameFromXPN(value),
gender: gender::genderFromPid(pid),
birthDate: timestamp::fhirDateFromTS(pid."PID-07"."TS-01"),
deceasedBoolean: boolean::fhirBooleanFromNullable(pid."PID-30"),
deceasedDateTime: timestamp::fhirDateFromTS(pid."PID-29"."TS-1")
}
%dw 2.0
fun genderFromCode(code: String) =
if (upper(code) == "M") "male"
else if (upper(code) == "F") "female"
else if (upper(code) == "O") "other"
else "unknown"
fun genderFromPid(PID) =
if (PID."PID-08" != null) genderFromCode(PID."PID-08" default "")
else null
Just from looking at the above code snippet, we have already made some reuse of the FHIRDateFromTS function in defining birthDate and deceasedDateTime using the updated patient resource DataWeave script. We can also reuse either the patient DataWeave script in the creation of a diagnostic report resource, or we can split out the logic across DataWeave scripts and bring it together at the end to generate the diagnostic report.
%dw 2.0
output application/json
// Flow Vars
var patient = vars.patientResource
var serviceRequest = vars.serviceRequest
var observationList = if (vars.observationList != null) vars.observationList else []
---
{
resourceType: 'DiagnosticReport',
id: uuid(),
contained: [patient] ++
[serviceRequest] ++
observationList,
subject: {
reference: '#' ++ patient.id,
display: patient.name[0].text
}
}
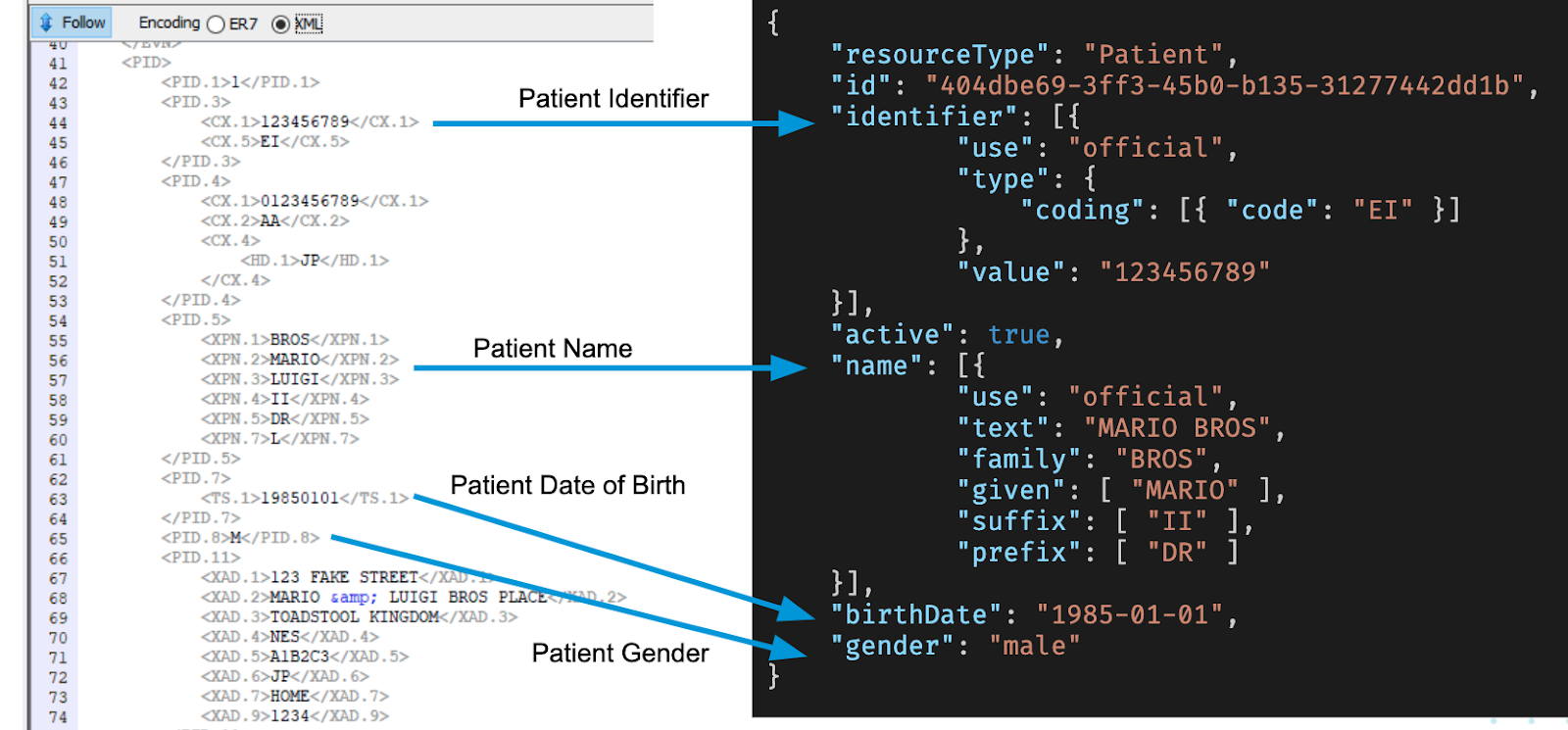
As a result, when we process the sample ADT through the Patient Resource DataWeave script, the patient’s name, date of birth, and gender all get mapped across as expected:
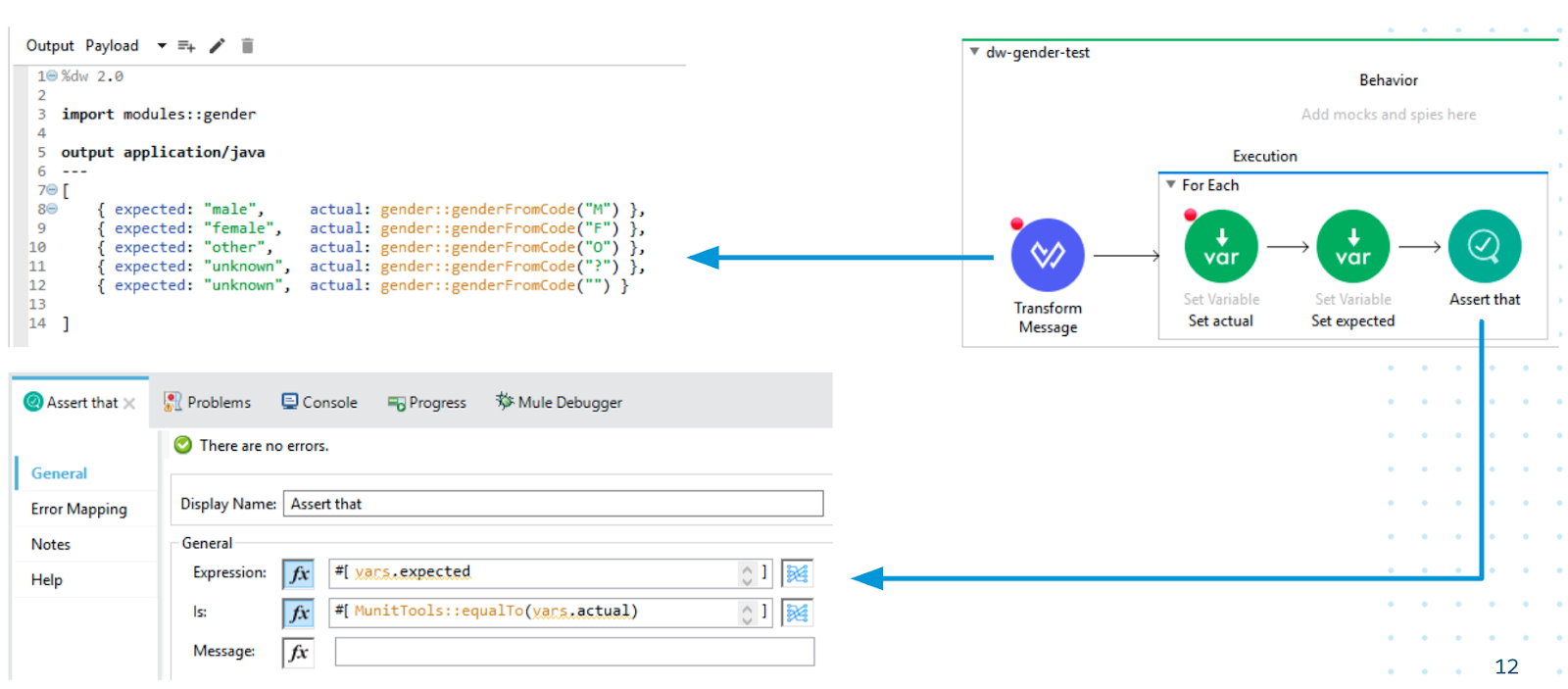
We can also test each of our smaller modules in isolation using MUnit. Each scenario in the MUnit test below asserts that when we call the genderFromCode function with a valid HL7-V2 gender (M/F/O), that the expected FHIR gender is output by the function (male/female/other). We also have scenarios in our test that assert the error handling logic of the genderFromCode function for when we pass a non-valid HL7-V2 gender (question-mark or empty string) into the function. Here we assert the genderFromCode function outputs “unknown” as the result of passing in a non-valid HL7-V2 gender.
By creating these reusable DataWeave scripts and MUnit tests, we have implemented an accelerated healthcare solution. The benefits we have experienced from using Anypoint Platform and an API-led approach are numerous.
Benefits
As a result of building DataWeave scripts, our functions are kept small — making them easier to read and understand when developers are making changes. By packaging up our DataWeave modules as a redeployable jar file, we can version each release and safely make updates to roll out across our integration platform. By conducting MUnit tests, we have confidence that we do not introduce bugs into our workflow. We can now reuse much of this code in the development of new FHIR transformations, such as diagnostic reports and observations. Most importantly, because each process layer service is fine grained and generic, we have reusability across our integration platform — not just in this project — but in other projects as well.
While all of these are great improvements, the most important benefits we’ve seen are:
- Our developers now trust that they can reuse modules of code and expect them to work.
- The code that we write is more reliable because of our rigorous testing.
- We can develop new FHIR transforms in much less time allowing our team to focus on what’s important: the patient.
If you would like to watch my presentation at the Developer Meetup at MuleSoft CONNECT Digital Americas, you can find the recording and recap here! You can also download the sample project for this article here.



