
You might have read Dan Diephouse’s post last month announcing the release of Mule 3.6, and if you haven’t – go read it! And then come back to this. Seriously.
Ok, so now that you’ve read about the new HTTP connector in Mule 3.6 and seen the cool demo that Dan put together it’s my turn to drill down into some of the more interesting details – why we built the new connector, how we went about it and how we ensured that it’s performant.
Why?
The HTTP transport available prior to this new connector has been around for a long time – since Mule 1.x in fact! We’ve obviously updated and improved it a lot over time, but it still used the same underlying technology for some time. It has served us well and has been used to build countless integrations, but not only was it in need of some love (and long overdue for it), it was critical to have killer HTTP connectivity in the brave new world of APIs.
Usability and API’s
You may have noticed that our new HTTP support is now called the “HTTP Connector“. This is due to the fact that it doesn’t stick the the more rigid transport configuration model using endpoints, but instead uses a connector style configuration that you may be familiar with from using our Anypoint Connectors. The other major usability improvement, which you will have seen in Dan’s video, is the support for API-definitions, with initial out-of the-box support for RAML.
Scalability
The old HTTP transport uses Apache Commons HttpClient for outbound connectivity while using a home-grown implementation built on top of the TCP Transport for inbound. We were still using version 3.1 of HttpClient for outbound, because comparative performance tests didn’t show much performance improvement in 4.3 and so we decided to wait and do this bigger refresh of HTTP support. In terms of inbound, while the HTTP transport was great in terms of functionality and performed well, we had been recommending the use of the Jetty Transport for some time because the HTTP transport is based on the thread-per-connection model. This is OK if you can configure your thread pool size based on the number of concurrent connections you expect, but it becomes a notable issue if you expect significant or unknown levels of concurrency. This is where Jetty comes in. Jetty uses non-blocking IO, enabling it to handle many, many more connections without requiring a thread for each.
Confused? Exactly! Thats why in 3.6, HTTP and Jetty transports are now deprecated and a single new performant/scalable HTTP connector with improved configuration had been introduced.
How?
I won’t go into details on the usability improvements or RAML support in this post – and anyway, I’m sure what we did under the hood is much more interesting.
We started nearly from scratch in terms of the underlying technology choices; this meant deciding if we should build our own HTTP support from the ground up or use an existing open-source HTTP framework. Building our own made no sense given the number of great libraries out there, so we started playing around with Http Components, Jetty 9, Netty 4 and Grizzly. We compared their performance as well as their APIs while considering the feasibility of integrating with Mule. We also wanted to use the same framework for inbound and outbound connectivity.
Performance
For performance testing, we were interested in understanding each library’s performance profile for different concurrencies and message size, but also wanted to understand how each library behaved with different processing models – both processing requests in the selector thread and using a pool of worker threads to hand-off request processing to. This is important for Mule, as we support a wide variety of different integration scenarios from high throughput HTTP proxying to slower, more-complex service implementations which may involve database queries, or composing multiple other services.
We performed tests in our dedicated performance testing lab using two servers – one to execute the JMeter test plan and the other server to run the Http Library under test – with the following specifications:
- PowerEdge R620 with two Intel(R) Xeon(R) CPU E5-2630 processors running at 2.30GHz
- 10Gb/s dedicated network
- RHEL 6.5 / Java HotSpot 1.7.0_45
We tested multiple scenarios:
- Payload size: 100B to 100KB
- Concurrency: 10 to 8000
- Processing Model: Selector Thread vs. Worker Thread.
The graphs below include results for both processing models and you can see that in general, with a smaller payload size and such a simple (echo) operation, the use of worker threads is simply an overhead, whereas with larger payload sizes the difference is much less noticeable.
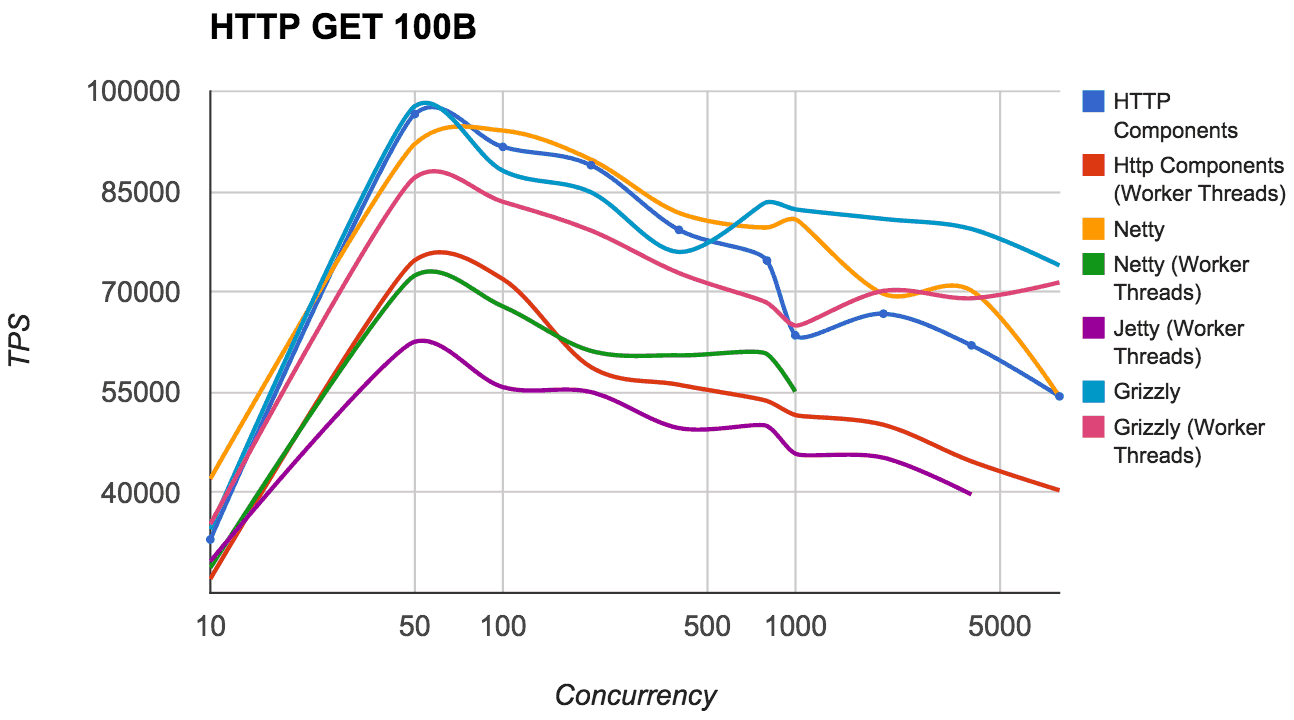
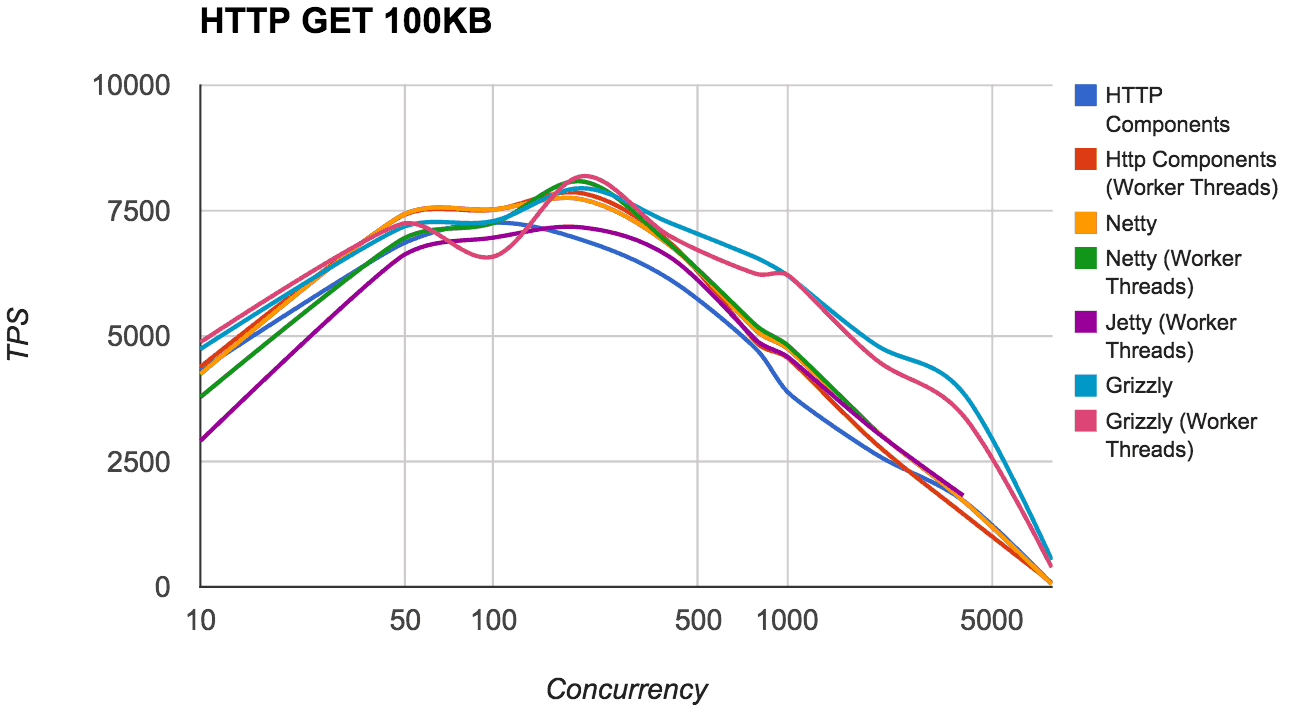
In terms of raw performance, the top performers were Netty and Grizzly. We got very similar numbers from both of these frameworks in our tests, with Jetty and HttpComponents lagging behind. We didn’t have time to dig into the Jetty or HttpComponent results in details, and it should be noted that performance also wasn’t our only criteria, but these were some observations on the different frameworks performance.
- HttpCompoments did really well with a small (100B) body, but lagged behind significanlty as soon as the body size was increased (10KB). Also, it did poorly when worker threads were used, potentially as a result of mechanical sympathy issues because worker thread was only used after the http message had already been parsed.
- Jetty scaled very well, but TPS was lower than the other frameworks with both small bodies (100B) and low concurrencies. I assume this is due to Jetty always using a worker thread for processing, but Grizzly/Netty still managed to do better with a worker thread pool.
- Initially Grizzly was slightly slower than Netty, but enabling Grizzly’s ‘optimizedForMultiplexing’ transport option improved performance giving Grizzly marginally better numbers. We also found that Grizzly appeared to scale better than Netty (up to 8000 client threads).
In order for us to perform a fair comparison, we did the following:
-
- Configured all frameworks to use the same number of acceptors
- Ensured all frameworks used the same tcp socket configuration (soKeepAlive, soReuseAddress etc.)
- Implemented exactly the same test scenario for each framework
- Performed tests with same test plan on the same hardware (detailed above) after a warm-up of 30s load.
- Ran all implementations with Java 7 (default GC) and a 2GB heap.
API/Extensibility
In terms of API and extensibility the primary things we were looking for were:
-
- Fully configurable in terms of socket options, number of selectors etc.
- Easy switch between processing requests in selector or worker threads
- Easy to integrate into Mule
All of the libraries we looked at were fully configurable, and wouldn’t have been hard to integrate into Mule, the most obvious difference was how they varied in terms of allowing different types of request processing.
For both HttpComponents and Jetty, easily switching between processing requests in selector or worker threads, was an issue as Jetty always uses a ThreadPoolExectutor for processing requests and HttpComponents process in selector threads by default – and doesn’t provide a mechanism whereby a ThreadPoolExectutor can be used. Netty was low-level enough to support this, but we found Grizzly’s IOStrategies to be the most elegant and flexible solution, allowing us to easily support a single instance of Grizzly in Mule with different ThreadPool’s for different Http Listeners.
We also found Grizzly to have better abstractions such as the MemoryManager interface makes it generally easier to integrate and extend. Another simple thing was that Grizzly uses the standard Java Executor interface, whereas Netty requires a netty EventExectutorGroup. Also, while we didn’t use it in the end, Grizzly has a higher level servlet-like Server API, which is even easier to use.
One disadvantage of Grizzly compared to Netty is that while Grizzly is already fairly mature, it’s community is much less active. Having said that Oleksiy Stashok has been very responsive on the Grizzly user-list and multiple changes have already been incorporated based on our feedback.
The Result
Wondering if everything we did was worth it? So were we. Once integrated, we went ahead and performed some comparative performance tests between the different version of Mule and different connector/transport implementations.
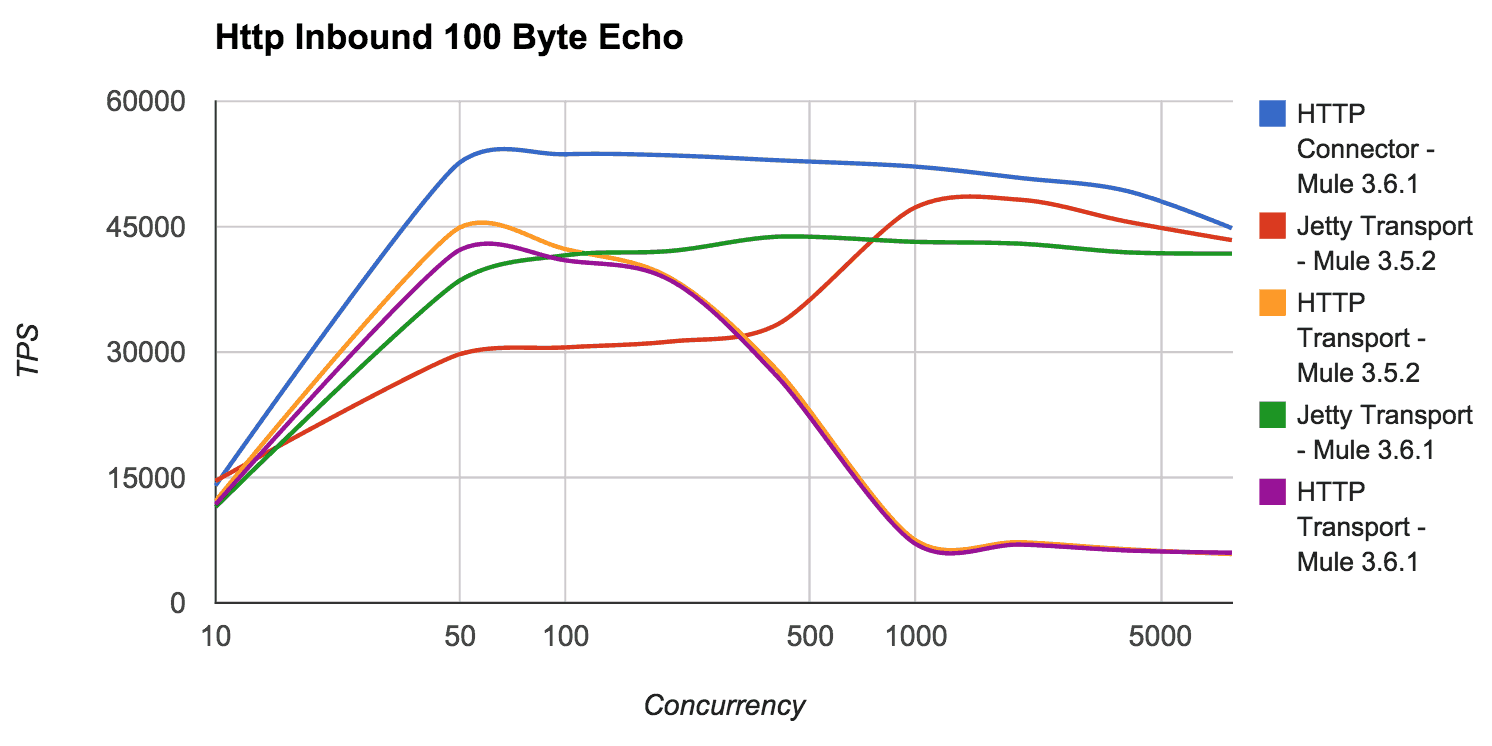
As you can see from the above graph, the new Grizzly based implementation in Mule 3.6 both outperforms the HTTP transport in Mule 3.5 at low concurrencies as well as the Jetty transport available in Mule 3.5 at higher concurrencies meeting our goal to have a single HTTP connector that can be used, and be high performing, in all scenarios. This graph only shows the results with 100 Byte payload, but the results with large payloads are very similar, with the delta between implementations reducing significantly once testing with a 100KB payload.
I didn’t cover HTTP Connector outbound performance in this blog, otherwise it’d would have been twice as long! Perhaps I’ll cover it in a follow up post.
So, if you aren’t already using Mule 3.6, you now have another very good reason to go and download Mule now!



