
This post is the beginning of a short series I’m creating to document my current coding style.
Everyone’s coding style is going to be a bit different, but whatever their style is should be dictated by their values as a software developer. You might see things about my programming style that you think are foolish, or maybe you’ll think I waste too much time on formatting. That’s OK, I’ll try to justify my choices as best I can.
With that being said, here are my values in the order that I care about them. Funny enough, they probably line up with clients’ values as well:
- Client first: The code must meet requirements. No extraneous code, either. The solution must be cost-effective.
- Other developers second: The code must be as readable as possible. The code must be as simple as possible. The code must have a reasonable about of reusability. Use common design patterns where applicable.
- My own ego last: This typically takes the form of using a library instead of rolling my own solution to an already-solved problem.
When I say they probably line up with the clients’ values, I mean the client is typically going to care about themselves (i.e. the company, the shareholders) first, their developers second, and me (a consultant) last.
Since my first value, “client first,” will change from client-to-client depending on their values, I won’t spend too much time there. Different clients are going to have different values depending on who the stakeholders of the project are.
Caring about other developers: my North Star for developing readable code
Let’s start with a quote from one of my favorite programming books, “Structure and Interpretation of Computer Programs,” emphasis mine:
“[…] a computer language is not just a way of getting a computer to perform operations but rather that it is a novel formal medium for expressing ideas about methodology. Thus, programs must be written for people to read, and only incidentally for machines to execute.”
In other words, if you’re writing code that makes a computer do what you want, but other people cannot understand, you’re missing the point of computer programming entirely.
Here’s another one for you, by Martin Fowler:
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.”
I care immensely about the developers who are going to need to maintain my code after I’ve written it. It’s not because I feel some kind of kinship with these developers, or I think we should all stick together through thick and thin. My reasoning is actually pretty selfish: caring about other developers makes my code better, and it saves clients money. When I say it makes my code better, I don’t mean it’s the most efficient, and I don’t mean it’s the fastest. I mean I’ve optimized for readability.
The payoff of optimizing the readability of the code is that other developers don’t need to spend as much time reading my code. This is important, and I’d like to run two hypothetical scenarios to demonstrate why. For the scenarios, we’ll assume I’ve just received a set of well-written requirements, and I’m about to write some code.
The first scenario
In the first scenario, I write the code in one take. It meets all the client’s requirements, and it only takes me eight hours to write. However, because I write this code so fast, I take some shortcuts: I don’t give my components good doc:name attributes, I use variable names like “x,” “y,” and “arr,” because I don’t want to waste time thinking up meaningful names, I never retroactively look at my code and consider if it could be better, I never write tests. When other developers read through my code, it takes them four hours to understand it.
The second scenario
In the second scenario, I write the code over two iterations and take time upfront to design my solution before writing any code. It took me eight hours to design, and 16 hours to write, for a total of 24 hours to create the deliverable. Let’s tack on another eight hours for me to write unit tests that also serve as documentation for developers on how the code is supposed to work. My doc:name attributes give a clear representation of the intention of my code, my variable names are meaningful, and I broke up some sub-flows that were responsible for too much. The total time it took me to complete the task was 32 hours. However, because I invested that time up front to make sure my code was easy to understand and readable, it doesn’t take developers as long to understand it. Whereas in scenario one, it would take a developer four hours to understand my code, in scenario two, it takes developers three hours to understand my code.
Wrapping it up
It took me 4x longer to write the clean code as it did the messy code. But that only yielded a 25% increase in the time it takes other developers to understand my code. Is that even worth it? How do we even measure that? Let’s look at it in terms business stakeholders and developers alike will understand: monetary cost and developer time.
Remember that code is written once, and it is read many more times than that. Let’s assume over the course of this code’s life, it was read 100 times. Let’s tally up how many hours are spent on this code. We can do this with a linear equation:
Scenario 1:
t1 = 8 hrs + (4 hrs * 100) = 8 hrs + 400 hrs = 408 hrs
Scenario 2:
t2 = 32 hrs + (3 hrs * 100) = 32 hrs + 300 hrs = 332 hrs
We’re working under the assumption that every time a developer reads the code, they’re starting from scratch. This helps keep things simple.
Let’s say everyone on the team is billing at $100/hour: the code I rushed to build in scenario one would’ve cost the client $40,800. The code I took my time to build in scenario two would’ve cost the client $33,200. That’s a savings of $7,600. That’s how much it would cost the client to hire a developer for 9.5 days (assuming 8 hours/day).
Maybe you’re rich and you’re thinking “that’s not that much money,” but first, consider this: how much value could *you* deliver to the client in 9.5 days? And after considering that, consider this: once you’ve practiced writing clean, readable code, and you’re good at it, it’s not going to take you 4x as long, and the rewards are going to be greater than 25% in terms of time to understand the code. Let’s modify the numbers a bit to be more in line with my experience.
We’ll modify Scenario 2 only:
t2’ = 20 hrs + (2 hrs * 100) = 20 + 200 = 220 hours
Now the code is costing the client $22,000 over its lifetime. That’s a savings of almost half! You’re saving the client 27.5 days of developer time. You’re saving your fellow developers 27.5 days of reading messy code. They’re throwing parties for you, erecting statues in your honor, slapping your surname on landmarks, you get a $10,000 bonus and five days vacation. Not really, but we can dream, right?
Again, this is a hypothetical scenario, but since code is read so many more times than it’s written, the number of scenarios that favor saving time up front at the expense of readability are much smaller than those that favor spending time up front to optimize readability. Like everything else in software though, this really depends on the situation. If you’re creating a throwaway prototype, don’t waste your time making sure everything is tidy; you might be the last person to ever see that code. If you’re creating something that’s supposed to be around for five to 10 years, you should strongly consider investing some time upfront to make your code clean and readable.
Now that I’ve (hopefully) convinced you that this is important, let’s talk about how this relates to Mule projects with my favorite rule:
A simple main flow
This rule is incredibly simple, and the benefits are immense: a developer reading your code should only have to look at one flow to develop a high-level understanding of how it works. That flow (or flows if there are multiple data flows in a single Mule configuration xml) should be at the top of the file.
As a loose guideline for this, I only allow a few components in that top flow:
- Inbound connectors
- Loggers
- Flow-refs
- Message-Enrichers (examples in Mule 4, so you won’t see these)
- Async scopes
- Business events
- Exception strategies
Again, just like the Pirate’s Code, this is more of a guideline than a set of hard-fast rules. Sometimes it will make sense to put a Choice Router in there, especially if the flow’s primary job is to route messages.
But there is one hard-fast rule: Give every component a descriptive doc:name. Developers should be able to understand your code at a high-level without needing to check out the configuration for every component.
First, let’s see what this looks like. The benefits should be immediately obvious:

Now you, a person looking at my code for the first time, can obviously tell that this flow probably pulls a file, transforms the file, zips the output, and sends it to S3. And it shoots off a notification in there somewhere. You just determined the “what” in less than 30 seconds. If you’re reading the code because you need to make changes, it should be immediately obvious to you where you need to make those changes. You also know the “where.” Then, the next question you need to answer is “how,” (which is exactly where you wanted to be spending your time anyway, right?). But let me ask you this: how much code have you seen where you had to spend more than 30 seconds determining the “what”? How about the “where”? How much time would you have back if you could cut all those times down to less than one minute?
Hopefully that last question didn’t make you too angry. Let’s check out a situation where these rules weren’t followed:

Yeah, good luck. Please don’t do this to other developers. Less than 100 characters and 60 seconds can make a world of difference.

Let’s check out a scenario that I see with a lot of newer Mule developers:
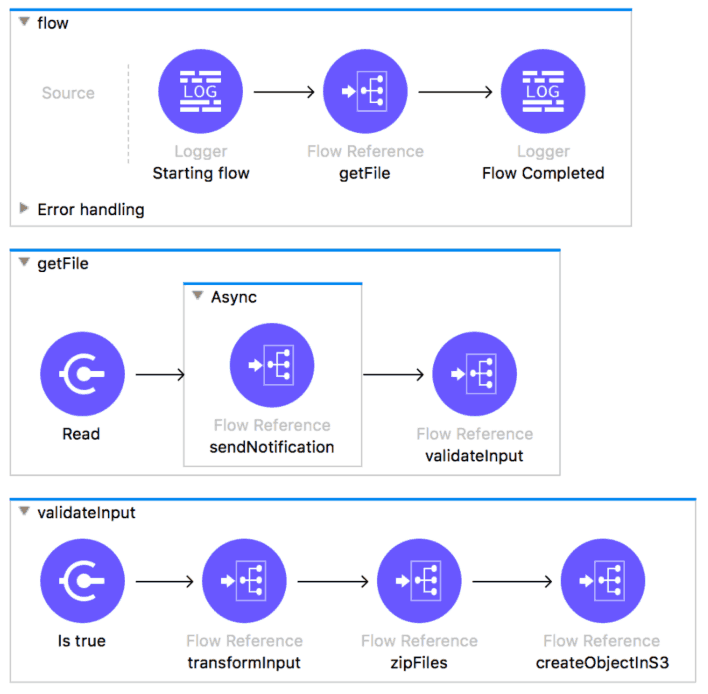
There are three issues here:
- The separation of concerns between flows is completely gone. For example, you can’t call getFile without validating the file, too. This immediately kills your reusability.
- Because of the lack of separation of concerns, unit testing becomes incredibly cumbersome, as you need to mock a ton of flow-refs to isolate functionality.
- The second you start tracing the overall execution of the flow, you’re exposed to the internals of how we retrieve files, what kinds of validations are done, etc. That’s more information than a developer is going to want to know the first time reading your code. It’s going to make it difficult for them to understand the overall goal of the flow.
But it’s an easy fix. Typically you just need to point out the issue, there’s an “aha” moment, and all is well: code from that developer is now consistently more readable, and more reusable.
Conclusion
The readability of your code is important. It’s much more important than how long it takes you to write it. To enhance the readability of your code in Mule projects, I’d recommend you use a single main flow that describes what your code does at a high-level using descriptive doc:name attributes. If you want, you can use this same strategy to design your flows before you start writing the actual implementation. Tune in next time, where I’ll discuss how I format my DataWeave code.
This blog originally appeared on Jerney.io.



