
This is part four of my five-part series documenting high scalability in Mule 4. If you haven’t read part one, Scale your APIs with Mule 4, part two, Reactive programming in Mule 4, and part three, Thread management and auto-tuning in Mule 4, check them out! This post will cover streaming in Mule 4.
Mule applications have always been able to process input streams. Mule 4 now enables an already-consumed stream to be consumed by a subsequent event processor. Instead of having to read a stream into memory for repeated processing of the payload, Mule 4 event processors can consume the same stream both in sequence and in parallel. This is the default setting. There’s no need for explicit configuration. To get a Mule 4 application to behave in the same way as a Mule 3 application you have to manually configure the source of the stream with the <non-repeatable-stream/> configuration.
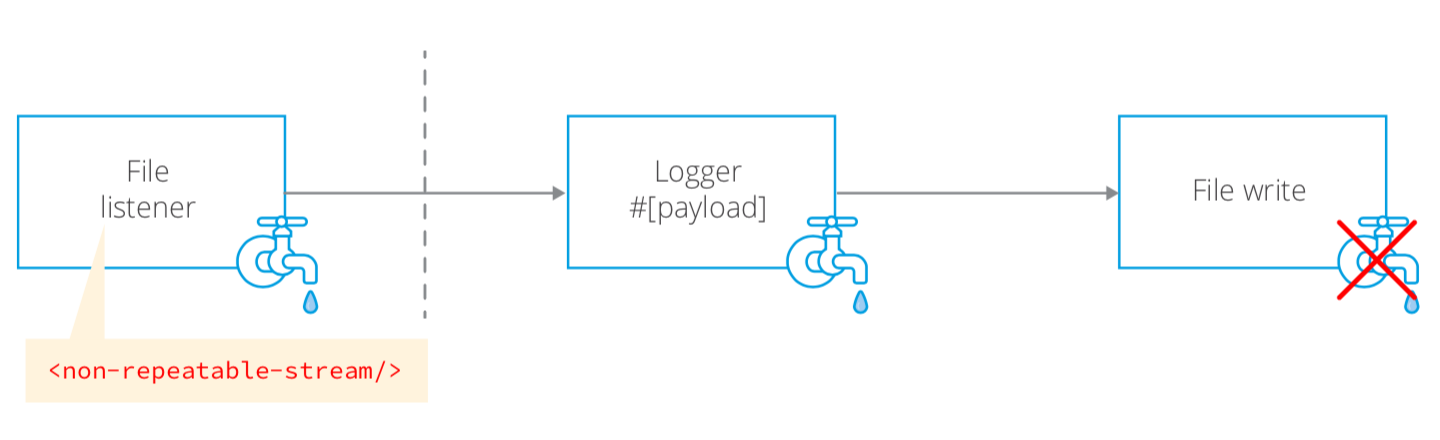
In the above scenario, the File Listener will pass a non-repeatable stream to the chain of event processors. Note that because the Logger consumes the stream it is no longer available to the File write operation. An error will occur because it tries to consume the stream after it was already consumed by the previous Logger operation.
Repeatable and concurrent streams
Mule 4 introduces repeatable and concurrent streams so that the above scenario will work by default. A stream can be consumed any amount of times in a flow. Concurrent stream consumption is also possible so that the multiple branches of a scatter-gather scope can each consume a stream the scope may receive on a flow.
Binary streaming
Binary streams have no understanding of the data structure in their stream. This is typical of the HTTP, File, and SFTP modules.
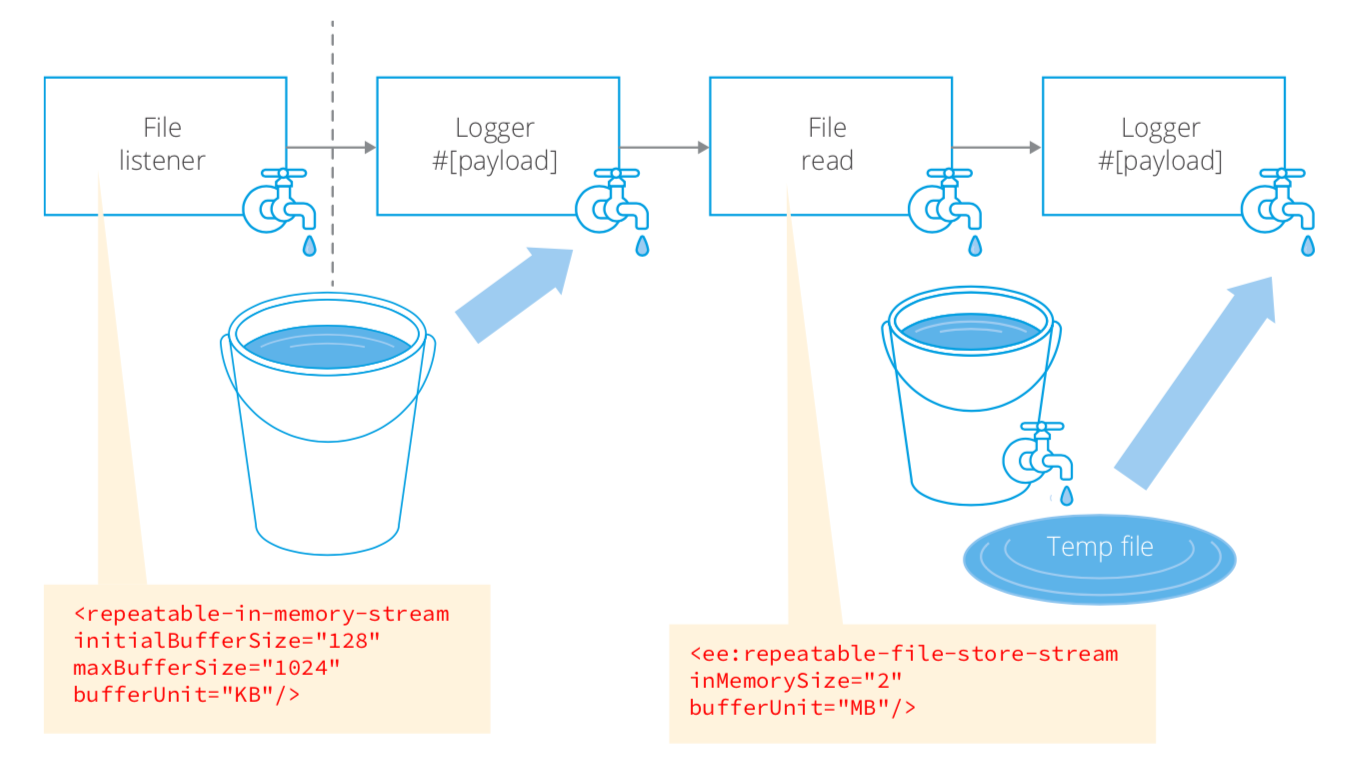
There are two ways to configure repeatable binary streams for event processors in Mule 4: in-memory and file-based. The in-memory configuration allows you to start with an initial size buffer which will increase in size to a max. The file-based configuration allows you to configure the invariant size of a memory buffer which will be filled before any overflow is stored to a temp file. This is transparent to the Mule developer. In the scenario above the developer doesn’t worry about how much of the memory buffer was used or whether any data was stored to file.
Object streaming
Object streams are effectively Object iterables. They are configurable for operations that support paging, like the Database select operation or the Salesforce query operation. The configuration is similar to the binary streams and also applied by default. Those operations that support paging return a PagingProvider (more on this when we explore the Mule SDK). The next event processor in the flow will transparently call the PagingProvider.getPage() method as it iterates through the stream of objects.
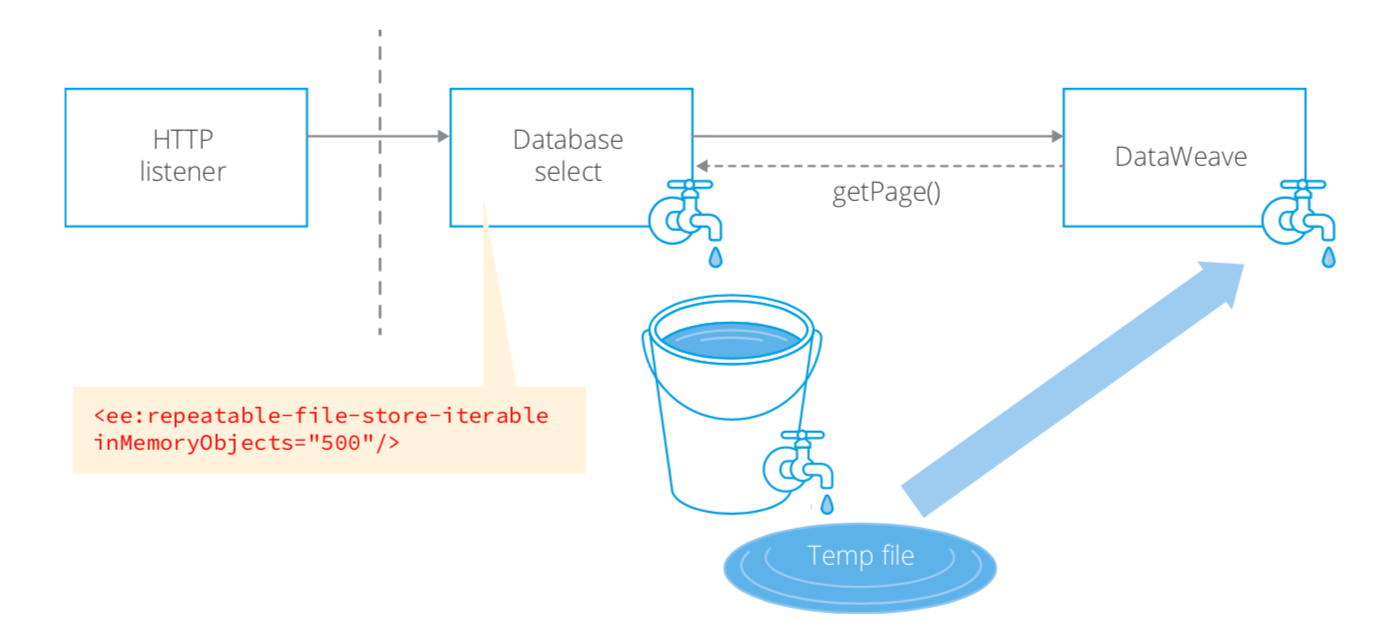
In the above example, the Database select operation passes a PagingProvider reference to the DataWeave event processor. DataWeave will call the PagingProvider.getPage() method as it iterates through the stream of objects. The configuration on the Database module establishes how many objects are stored in memory before the rest are persisted to a temp file.
Tuning strategy for streaming
Because there is no global streaming configuration for the Mule application (or the Mule runtime) you do well to calculate the product of your max expected concurrency and the totality of the in-memory buffers for the application. You should then limit the amount of events being processed by a streaming operation using the maxConcurrency configuration. When the maxConcurrency is reached back pressure will be triggered to the flow source.
My next and final post in this series will focus on scalability features in the Mule 4 SDK. You can try Mule 4 today or download our whitepaper to see how Mule 4 addresses vertical scalability with a radically different design.



