
In the Getting Started with DataWeave: Part 1, we introduced you to DataWeave and its canonical format, the result of every expression you execute in the language. We now continue to explore our new transformation engine, aiming to give you enough grounding to tackle real-world use-cases.
As we did in Part 1, we will continue to show the results of each expression in the DataWeave canonical format.
This series is now complete here:
- Getting started with DataWeave Part 1
- Getting started with DataWeave Part 3
- Getting started with DataWeave Part 4
Expressions
Your entire transformation is encapsulated in a single expression. In Part 1, we discussed writing semi-literal expressions to define the outer structure of your transformation as either an object or an array. Inside this expression, you can write other expressions of different types. There are 7 basic expression types in DataWeave:
- Literal
- Variable reference
- Semi-literal
- Selector
- Function call
- Flow Invocation
- Compound
We covered literal, semi-literal and variable reference expressions in Part 1. In this post, we concentrate on Selector Expressions and Compound Expressions and refer you to our documentation for a complete coverage of these and every other expression types.
Selector Expressions
Selector Expressions are necessary for just about every transformation. They allow us to navigate to any part of the incoming data whether it be in the payload, variables or properties. You should bear in mind two things when utilizing selector expressions: their context and their result. They can be appended to each other to form a chain of selectors. The result of each selector in the chain sets the context (object or array) against which the next selector is evaluated. The first context will typically be the result of a variable reference expression, payload for example. However, any expression can set the proper context. Selectors only make sense when applied to objects or arrays, so you simply need to ensure that the context you set is an object or an array. Invoking a selector expression on a simple type will always result in null. (Strings are the exception to this. They are treated as arrays.)
Array Element Selector Expressions
Arrays, as you would expect, are indexable with the usual [0..n-1] notation. We also allow selection of ranges within the array. For your convenience, the indices can be negative, where -1 indicates the last element on the array. The range beginning with the second element and ending with the last element on array x would be indexed x[1..-1]. To retrieve the third last element to the first in reverse order you need to write x[-3..0].
Object Selector Expressions
Single Key Selector
We have seen that DataWeave objects are sequences of key:value pairs in which the keys can be repeated. Many use cases will require you to retrieve particular values from deep within the object. To do this you will need to use the key selector, written in the form .<key-name>. The result is the value corresponding to the first instance of the key you specified.
Let’s take a look at our weather data XML document again and extract just the contents of the forecast and excluding the location. Bear in mind what we learned about variable references. The payload expression normalizes the input XML document into a DataWeave object whose key:value pairs correspond to the elements and their respective contents.
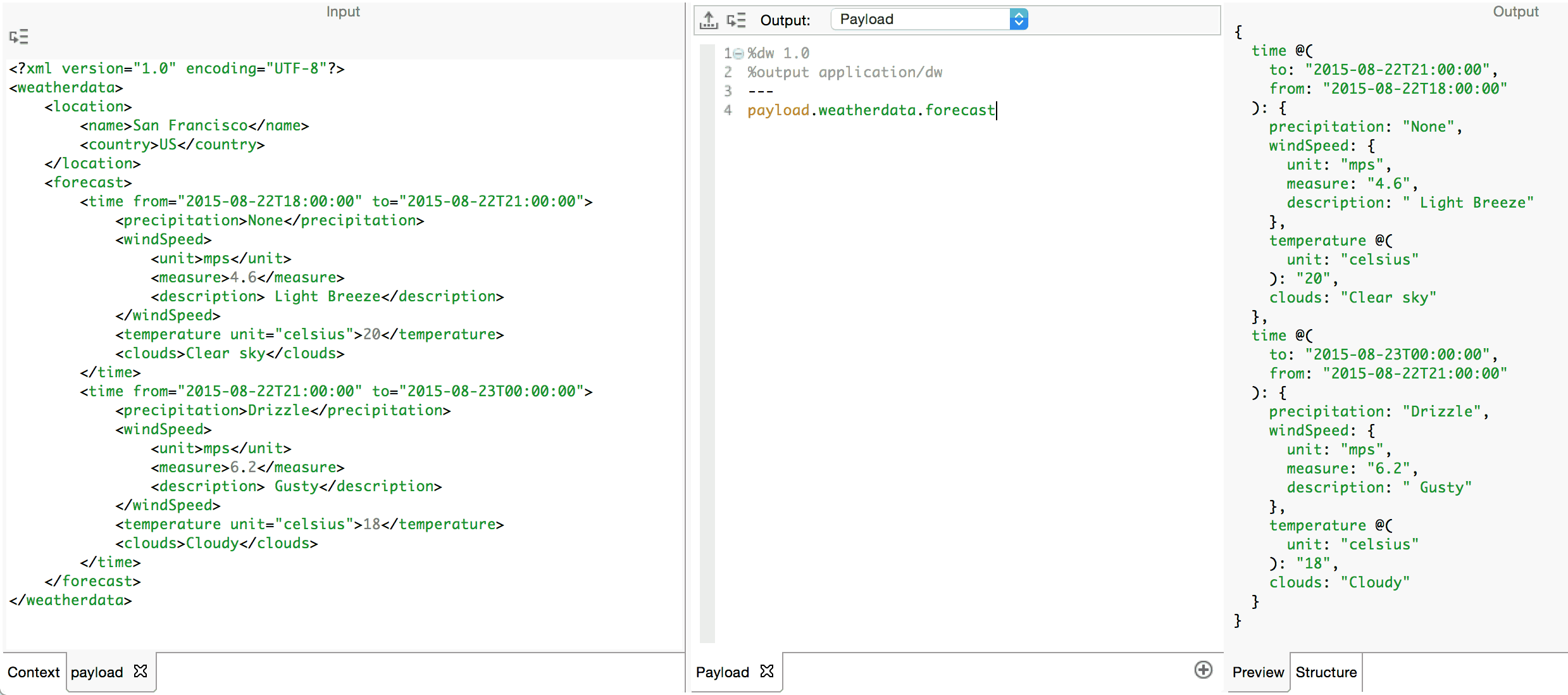
Note how we can chain the selectors together to navigate to the key of interest, in this case, forecast. See how the result is the value corresponding to that key. Hence, the forecast key does not appear in the result of the expression. Consider the following table of the results of navigating further into the object with payload.weatherdata.forecast as the initial context.

Multi-key Selector
Note how the .time selector results in the value of the first instance of time in the initial context object. However, what if we wanted both values? To retrieve the value for each repeating key, you must use the multi-key .*<key-name> expression. This will always result in an array of the values, even if there were only one instance of the key. Hence, the expression payload.weatherdata.forecast.*time will result in an array containing the values for each time key instance in the order in which they appear in the context object.
An important point to make here: when the context of your key selector expression is an array of objects, both the single-key and multi-key selectors will iterate and apply against each object in the array and the result is always an array. Consider the following table of expressions where we again use payload.weatherdata.forecast as the initial context:

Attribute Selector
You may have noticed that the attributes present on the time keys did not appear in the results of any of the above expressions. The key selector expressions only return the value corresponding to the key. When you need to retrieve a particular attribute, you should use the .@<attribute-name> attribute selector. Hence, the value of the from attribute on the first time instance above is retrieved with payload.weatherdata.forecast.time.@from. DataWeave provides a handy shortcut to get all the attributes as an object of key:value pairs. payload.weatherdata.forecast.time.@ will return both the from and to attributes wrapped in an object:

Compound Expressions
Thus far you have seen some of the basic building blocks you will use in a DataWeave transformation. You will enjoy the real power of the language when you combine these expressions together using operators. We explore some of the most important of these next.
Iteration
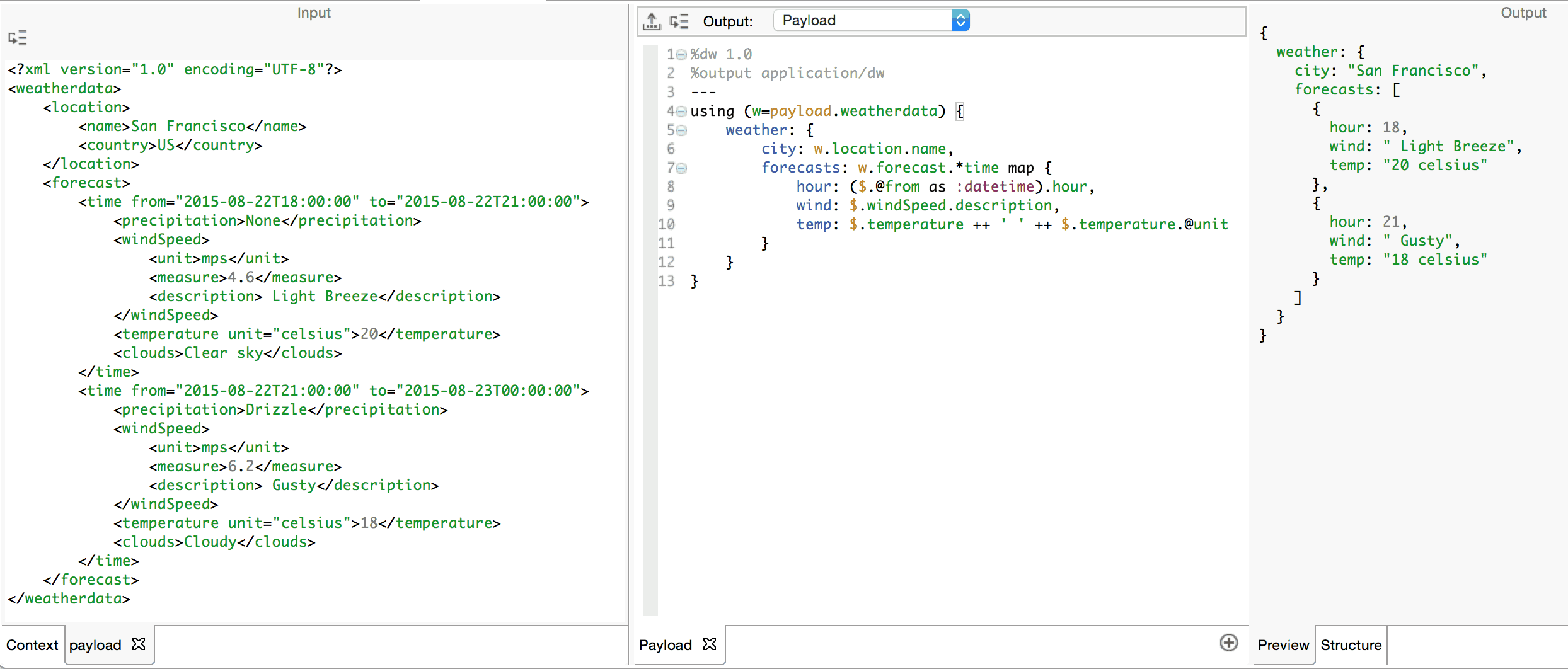
Let’s continue to work on our example weather forecast XML document and transform it so that we get some basic information from it. We are interested in the hour for each of the forecasts and a human readable summary of the wind and the temperature. Of course, there are many forecasts for the day, and we need to iterate through each one. We use the map operator for iteration. It takes as operands an expression which must return an array or an object on the left-hand side and any expression on the right. The result of applying map is an array where each element is the result of the right-hand operand. If the left-hand operand is an array, map will iterate through each element and add the result of the right-hand operand to the output array. If the left-hand operand is an object, map will iterate on the sequence of key:value pairs.
Let’s say we wish to build a forecasts array containing objects with 3 fields: hour for the time of the forecast, wind for a description of the wind conditions and temp for a description of the temperature.
A couple of things to note here:
- Using (w=payload.weatherdata) is a local variable declaration prepended to the object expression which defines our entire transformation. This variable, w, is considered local to the object expression to which the declaration is prepended. Hence, it is only valid to reference w within the scope of this object.
- Map will iterate on each element in the array returned by .*time and add the object defined as its right operand to the resulting array.
- $ is an alias for the element found at each iteration on the array.
- $.@from is the selector expression used to access the value of the from attribute.
- as :datetime is a type-cast expression. The .hour expression can thus be used to extract the hour from the date and time.
- For simple string concatenation, we use the ++ operator.
Filtering on Iteration
We are free to chain expressions together as compound expressions with any number of operators. Often we need to filter the data we work against before or after the operator of choice. The filter operator iterates through elements in an array or keys in an object and produces an array which contains only those elements which match the criteria specified by its right-hand boolean operand.
Let’s say we want to filter the array produced by map above so that we only get those forecasts after six o’clock pm:
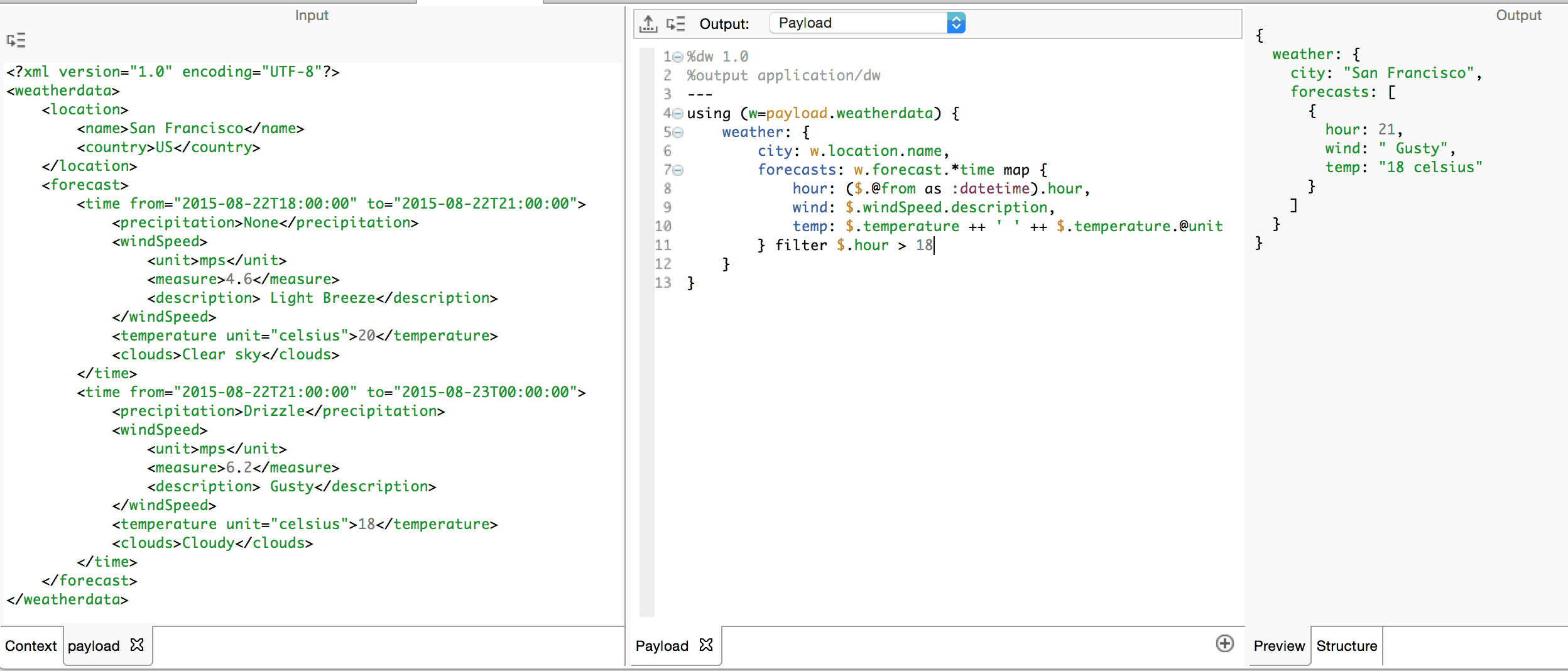
Note how the criteria expressed in the right-hand operand makes reference to $.hour. This key was not present in the original input. It is important to be mindful of the results of each expression in the chain of expressions that form a compound expression. The first expression which utilizes the map operator produces an array of objects with hour, wind and temp keys. This array becomes the left-hand operand of the filter operator, which iterates through the array and produces an array of objects filtering out those objects which fail the said criteria.
Conditional Logic
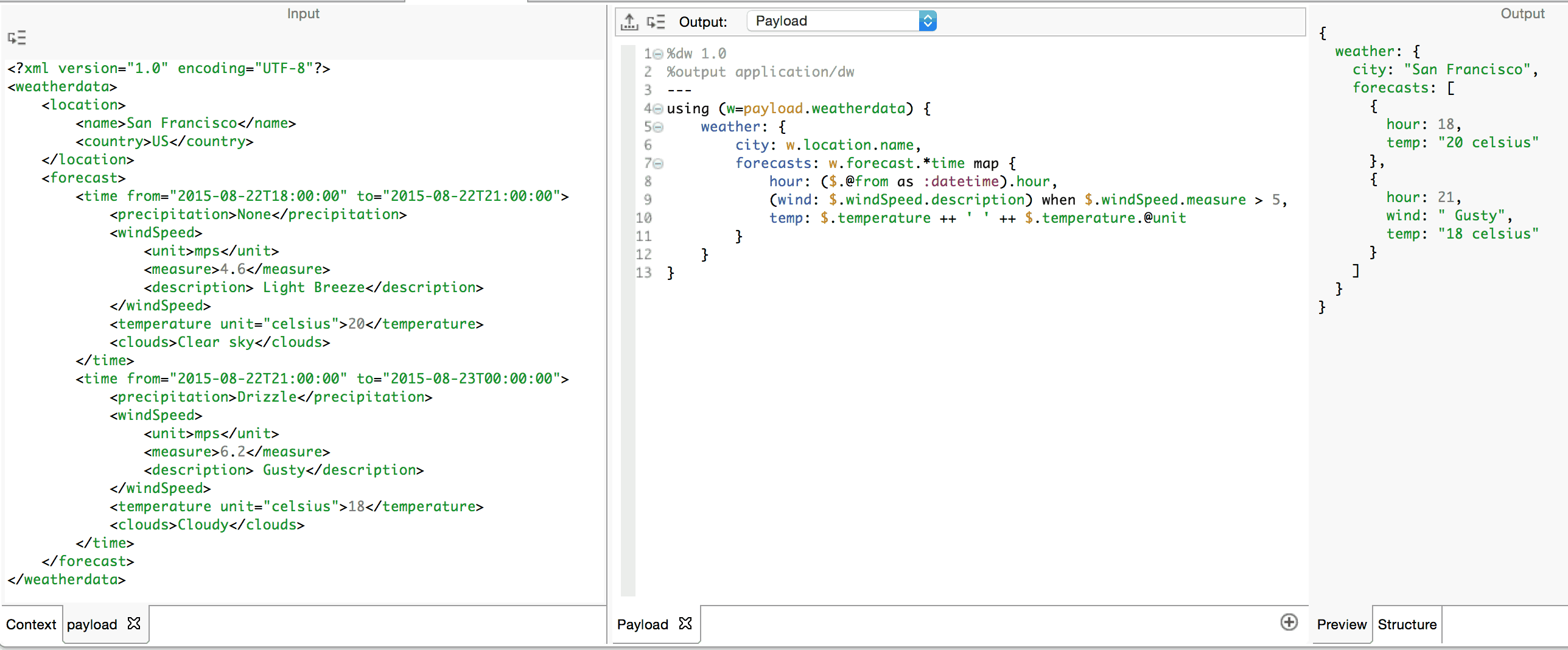
Often our transformation logic needs to output data only when we meet certain criteria. Let’s output every forecast but only include the wind description if the speed is greater than five miles per hour.
Note how we surround the entire wind key:value pair in parentheses. This is the left-hand operand to the when operator. The right-hand operand is a boolean expression. Only when this evaluates to true, is the wind key:value pair included in the output.
Next Steps
That’s it! You’ve just mastered the essentials to utilize DataWeave in every transformation requirement from simple to complex. In our next post, Getting Started with DataWeave: Part 3, we’ll guide you through a real-world scenario of transforming between Java Database result sets, XML and JSON payloads as you expose data through System and Experience APIs.
Also, you can now view our webinar on demand that introduces Dataweave.



