
In the first part of this blog, we discussed how government interventions (like FATCA and GDPR) have increased complexity in your corporate data landscape (on top of an already expansive digital landscape) and explained why a traditional ‘heads-down’ data strategy typically fails.
In part two, we will explore an alternative ‘heads-up’ approach, by outlining what an operationally ‘baked-in-by-default’ risk-based data strategy looks like, and how you can realize this advantage by building an application network.
Could a risk-based ‘heads-up’ business-driven data strategy be more effective?
Previously, we questioned the merits of the heads-down approach by asking ourselves these three questions:
- Do we attempt to manage, integrate, and secure all your data centrally or not?
- Should we aim to achieve common standards for all data or just some?
- Can we just preserve controls for operational data only and afford to let analytical data experience a degree of looseness?
Even with the imperatives of legislative compliance and the regulatory framework your business operates in, can we accept that perhaps not all data holdings of your business need to be managed, nurtured, and treated as an asset? If that can be true, that some data is more core to your business operations than others, that not all data needs to be governed and secured centrally, this opens the way up for options.
Take for example any bank’s AML reporting processes. The risk of non-compliance is now famously writ large in banking groups and conglomerates due to the staggering magnitude of the fines involved.
These fines relate to failures to understand and report transactions where the true counterparties to a financial transaction may be bad actors. So, we can say the risk profile of not managing this type of data is at the moment high, based on the potential penalty or price that is payable if this data isn’t managed correctly. Customer master and order data could be another type since if it is incorrect, there may be reputational damage affecting the bottom line.
Yet, many other types of data, while important to the organization’s mission, come with lower risks, because the data can either be recreated, is synthetic data, or the consequences of failure are not catastrophically risky. Much of unstructured data fits into these categories (like voice, correspondence, or manuals), as does data that is self-contained to specific business processes and not globally shared or needed to be standardized globally across disparate processes.
A data strategy that is grounded in a risk-weighting of corporate data holdings is a strategy that already understands the profile, value and risks inherent of its own data, and is a strategy grounded in tangibles not in abstract statements like “all data is an asset and must be managed.”
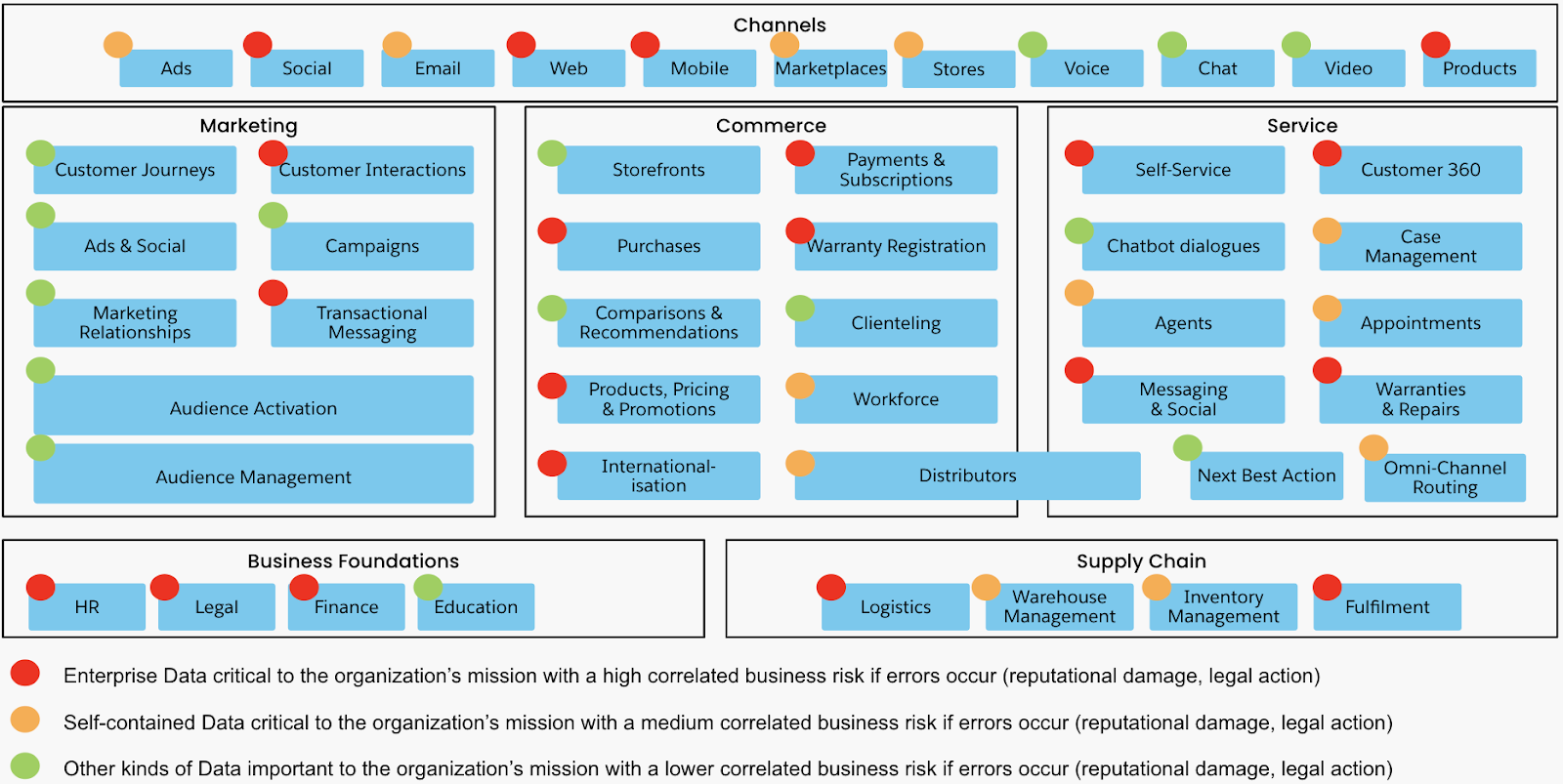
Take the example of a brick-and-mortar/omnichannel digital retailer above. Using a simple metric like the ratio of each risk category to total expressed as a percentage, this classification means that:
- ~42% of enterprise data is rated as critical and therefore the data strategy should address the full spectrum of data protection and maintenance processes for them.
- ~25% of data can rely on the safeguards that are resident in the systems that already hold or integrate that data without expensive stand-alone tooling.
- ~33% of data, whilst important, can have less safeguards and security because the business risk is judged to be lower.
This rating needs to be continuously monitored and improved via a process feedback loop, it is not static and needs to reflect current trends and trading conditions.
Simplifying stand-alone data management processes and tooling means using industrial data management processes (like validation and typing) in the operational systems only.
When that data flows to the analytical stores, they rely on the operational first line of defence for improving analytical quality. The notion of analytical data labs which can be destroyed and recreated on demand which obtain quality operational or even synthetic data will reduce the cost of running the insights business.
The operational application network as an active data strategy
MuleSoft APIs already come with their own lightweight data standards (RAML), validations (inside the Mule app), and operational lineage capability (the network of connected APIs). So, in the case of operational data, much of it requires protection. Management work is already being done by default, according to a business risk-based approach.
Implicit in this risk-based approach, moving away from all data needs to have the gold standard of management and protections applied, is a trade-off between what enterprise data any consumer (internal or external) may get.
Just like in the real-world, where obtaining all features in a product is expensive, it is a business judgement to apply finite resources to priority solutions.
Maximizing business value in a digital age means prioritizing an omnichannel connected experience. This connected experience has customer 360 data that follows their life journey with an organization’s products and services. This omnichannel platform allows the organization to adapt to changing consumer expectations, like advertising on new channels such as TikTok. This approach to data strategy, where data is managed in-stream with valuable business processes, is therefore superior to trying to make all enterprise data available to internal consumers, wherever it may reside because that ‘heads down’ approach simply prioritize an inward-facing agenda
These trade-offs are made in light of the industry profile and business risk appetite. But it is a worthwhile tradeoff to consider, as is understanding how to reduce the cost of expensive and non-value adding data compliance by-design, inside an adaptive and composable application network.
In an end state where an enterprise has developed a mature and extensive operational application network of APIs, this forms the core of the active data strategy which helps minimize these tradeoffs and maximize accessibility. A connected and composable application network also helps with answering the current and future compliance needs, like a customer’s GDPR ‘right to forget me.’
Whether the data is in-stream, message, or file-based, the data that is the lifeblood of your organization’s business processes is being nurtured already.
Separate expensive tooling that grew up in a non-cloud, non-API era are mostly no longer required and can be retired. Heavyweight expensive data standards bound up in complex code (like XML) can be progressively relegated to the past. Analytical data stores using data streaming and modern data warehouse tech (like Snowflake) can be spun up with clean validated data from the many operational systems that APIs connect.
If we have already identified which data is important and which is of lesser importance, and have a pervasive application network, then the cost of compliance with new privacy regulations becomes simpler, because we know where each touchpoint is, and we have standardized on a lightweight data protocol (RAML) that makes extensibility for new requirements and versioning them easier.
Doing this already, also by default, facilitates access for data consumers when and where it is needed. By providing simple to use Process and Experience APIs that mask the complexity of underlying systems, LOB users and even citizen developers are empowered to access federated data safely and quickly for innovation and growth.
Using MuleSoft APIs and creating an application network as a mechanism to facilitate your active data strategy is a great step forward to making your systems lightweight and agile without costly heavyweight classic data management solutions. This trend is happening now and the potential to uplift your data strategy, how you access and use data cost-effectively is great if you fold this thought into your forward plans at the beginning of your MuleSoft journey.
Learn more about how to build an API strategy for your organization with data in mind.



