
The idea of this blog post is to give you a short introduction on how to do Real time sync with Mule ESB. We’ll use several of the newest features that Mule has to offer – like the improved Poll component with watermarking and the Batch Module. Finally we’ll use one of our Anypoint Templates as an example application to illustrate the concepts.
What is it?
Near Real time sync is the term we’ll use along this blog post to refer to the following scenario:
“When you want to keep data flowing constantly from one system to another”
As you might imagine the keyword in the scenario definition here is constantly. That means, periodically the application will move whatever entity/data you care about from the source system to its destination system. The periodicity really depends on what the application is synchronizing. If you are moving purchase orders for a large retailer you could allow the application a few minutes between each synchronization. Now, if we are dealing with Banking transaction you’ll probably like to change that to something in the order of a few seconds or even a hundred milliseconds, unless you really like to deal with very angry people.
The nice thing about the template we’ll use as example is that such change in the behaviour of the application is very simple, just an small change in a properties file’s line.
How does it work?
As I mentioned before the objective of this template is to move data periodically from one system to another one. In order to do that there are few things to solve. The first decision you have to make is choose between these two approaches:
- Push: It means that your application will be notified of the fact that there is new data to be synchronized
- Poll: It means that your application will be in charge of figuring out what new data is there that needs to be synchronized
Poll & Watermark
For this Template we’ve chosen the Poll Approach. The reason behind this is that not many systems out there have the capability to notify changes, and some of the ones that do offer this capability do so in an unreliable way. That means for instance, that they will try to push a message without knowing wether you application is listening or not, or that they offer no ACK mechanism so they don’t ensure that the destination system actually receive the message successfully. In any event the main problem here is message losses.
A reliable application cannot afford to lose a message signalling the creation or update of an entity.
Last but not least several systems out there do offer ways to query for data which is what we need to implement our Poll approach, thus this solution applies to a broader number of source systems.
Now that we’ve decided to use the Poll approach we can define the Mule components to use, and of course we’ve chosen the Poll component with its watermark feature.
The Poll component in it most simple way of working just runs every certain period of time executing the message processor inside of it, thus triggering a flow and the payload of the message entering the flow will be whatever the result of execution of the message processor was.
As we are going to be polling information from a source system, we must tell it what do we need and here is where we use the watermark functionality. In short the watermark functionality will allow us to delegate in the poll component the responsibility of:
- Selecting the watermark value to be used in the current run
- Analyse the returned payload and choose the next watermark to be used in the following run.
I could give you a detailed overview on how Poll and watermarking works but there is already a cool blog out there for that, you can find it here: Link.
Inside Batch
The Batch Module is a really powerful tool and there are tons of documentation to learn how it works, you could start reading these two blogs:
Nevertheless I’ll like to provide a really short introduction to it so you can get a hold of how it works.
The batch module divides its work in three stages:
- Input Stage
- Process Stage
- On complete Stage
The Input Stage
The input stage is the first thing that runs when you execute a batch job. You can do several things inside this stage but you need to ensure that the payload contained in the message after the execution of the last message processor is either an iterable, and Iterator or an array . You can also leave then Input stage empty in which case the previous consideration should be taken for the payload in the message previous to the call of Batch Execute message processor. The final task of the Input Stage, which is implicit i.e. build in into the Batch Module, will transform each item in the iterable/Iterator/array payload into a Record. This is a very important fact to understand, from this point onward you could not access the original payload in this form you’ll only deal with Records. It is worth noticing that this stage runs on the same thread that called the Batch Execute message processor, but once the stage is done consuming all the items in the payload this thread will return, that is the Process Stage runs in a different thread.
The Process Stage
The process stage is divided into Steps. Each step will receive a Record to process.
This is a the main concept that you may find different the first time you work with the Batch module, each step only deals with records. If you recall a record is each item of the iterable/Iterator/array payload processed during the Input Stage. So please keep that present at all times, each step doesn’t deal with the whole original payload but rather with just one item at the time.
The idea behind this is that each Record will be processed in turn by each Step defined in the Batch Job.
The On complete Stage
This is the final stage of batch, it will be executed ones all the records has been processed. Again this stage is executed in a different thread that those in the Input Stage and the Process Stage.
Template Description
Now that you have a basic knowledge of Poll and the Batch Module, let’s describe how this particular Template makes use of it.
- Fetch all the created/updated entities from the source system
- Try to fetch the matching entity in the destination system for a particular entity and store it
- Deal with the orinal entity and we prepare it to push it to the destination system
This is the first flow you’ll find in the application and it is here where you modify the periodicity with which the application run.
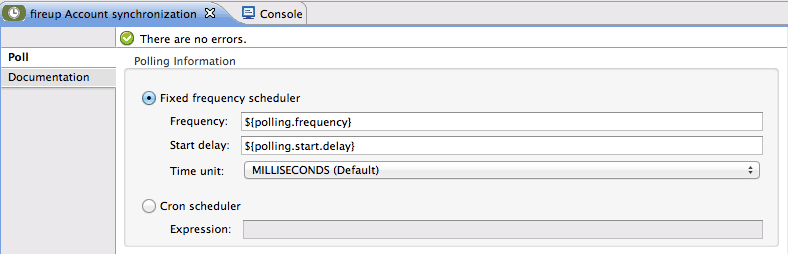
Just change the Frequency, as showed below and you’ll be good to go:
This is the batch job, were you’ll find steps 2 and 3:

As you can see the application is a fairly simple one. Now you may have notice that in the third step we make use of another Batch tool, a scope called Batch Commit. The Batch Commit scope allows you to aggregate records. In this example we aggregate the entities in order to make just one call with as many as 200 entities at the same time, thus reducing the amount of calls to the destinations system and improving the overall performance of the application.
All the records of the original input will be processed, once they are all done then the On Complete Stage will be triggered. At this point the Batch Module offers the user a POJO called Batch Job Result with statistics regarding the final state of the batch process, it expose data such as amount of records processed, amount of records success, etc. You can find more information about the Batch Job Result in this page. You can use this data as you see fit, in this Template we’ve choose just to log this information to the console, but you could send it through email or send a Tweet, or maybe upload a file to your favourite cloud based storage.
Why Batch ?
The Batch Module is a powerful tool offered by Mule ESB. It offers you the capability to process large amounts of data, in a reliable way. That is, it can recover from a crash and keep processing a batch job from where it was left off, even if the power went down and back up.
Now you may be asking why to use something like the Batch module for something like this?
Well because the Batch module offers:
- Support for large amounts of data
- Reliability
- Both at the same time
- Management (which will be coming shortly in the next Mule ESB release)
I reckon that no one will question why reliability is an important thing, but why do we care about large amounts of data. It’s fair enough to asume that if the application is running periodically then the amount of data to be process shouldn’t be that much, then again the really is that you can not asure that. Easily enough a user can shutdown the application for a day and then start it again, just there you have a day worth of data to process, or you could set up you application very first run to bring data which was update during the last five years, finally there could be 10 other applications generating data in your source system at the same time. In any of the previous events your application should hold and be able to deal with that amount of data.
Although you could do all this with just the original tools that Mule offers you, reality shows that it’s far simpler to do so with the Batch module mainly because you just don’t have to deal with all the specifics that the module solves out of the box.



