
In the previous blog post of this series on C4E, I discussed using an API-led approach to build software applications. The C4E practice encourages reuse of resources, collaboration with third-party developers, and frequent direct interaction with business owners. During the initial discovery phase, the team recognizes the opportunity to develop a System API that provides an endpoint for retrieving data from a lookup list. The System API also allows for the list to be replaced and updated.
To be more precise, instead of using static files stored in the source code, the team offers a cleaner approach to retrieve key-value pairs contained within files. In previously built applications, the file is stored in a resource folder within the source, loaded into memory as a key-value store and maintained as a record in the repo.
When a key or value contained within the lookup list changes, the adapted list is updated into the source code, tested in a development environment, deployed to CloudHub and eventually restarted. This is a tedious, clumsy process that is frequently repeated in many of our teams’ use cases. If this were only a single lookup list with infrequent changes, using an API could be viewed as excessive or an over-engineered approach. However, in our use case, lookup lists are used all the time and, on top of that, they are constantly changing. By creating an API, we not only avoid repeating work, but we also provide a resource for streamlining future applications.
Following the C4E approach, the IT team first needed to create a high-level overview defining the steps for our System API. The System API must have a dynamic endpoint point for key-value retrieval and a second API call for updating the lookup list file. Creating a System API for this purpose is well suited for the C4E practice because it encourages reuse and utilizes a scalable design.
A diagram of the process flow for the key value lookup is shown below (the dynamic post flow for updating the list will be available on Github or Anypoint Exchange):
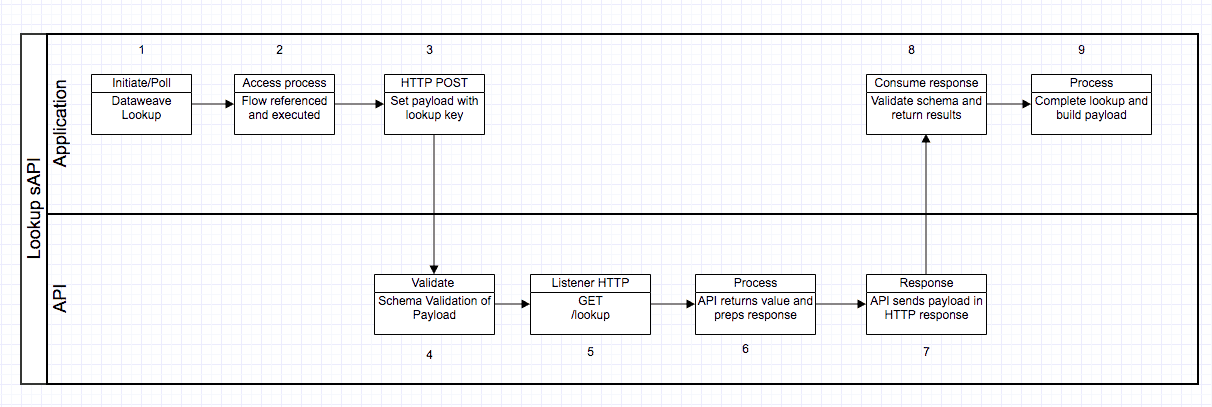
In essence, these are the steps of the process:
- The initial application requires a value lookup from a list. DataWeave looks up the list.
- A flow reference is performed on a lookup from inside of DataWeave.
- The process initiates an HTTP POST to the Lookup System API.
- The API application validates the schema of the payload that is sent against a data type/library.
- The Lookup API listener directs the incoming payload to the processor for lookups.
- The lookup process receives the payload and transforms the result into the expected data type/library.
- The process builds the response with either the correct value from the lookup or an empty payload with an error, then it passes the response back to the HTTP requester.
- The application that requested the lookup value validates the response from the System API.
- The flow reference process returns the result to the DataWeave method call. DataWeave handles the lookup result and runs a conditional operator based on the contents of the result.
- The mission is accomplished.
In some instances, a process like the one described above may appear simple; and some may consider it to be ‘over-engineered.’ However, the beauty of the API-led approach lies within this solution.
By creating a separate endpoint to update the list while the API is active, you remove the burden of restarting applications whenever a list is changed. More importantly, this API is now part of the application network within our organization. IT can reuse this API whenever a lookup list is needed, instead of building the lookup into an application.
In the future, you can make a case for using this API as a lookup repo. The API call to post a new list includes two required query parameters for ‘type’ (csv, json, xml, or flatfile) and ‘lookupListName.’ Additionally, when updating a file, the same parameters are required so that the file type is updated. The file consumption process in the companion Mule configuration has a choice that first directs the file by type, then retrieves the file by name.
Now that we have laid out our grand plan, how do we accomplish this proposal?
Following our C4E approach:
1. Design the Data Types or Libraries for the HTTP requests and build examples for the responses in Anypoint Design Center. The Data Types for this particular scenario are quite simple. This example uses abbreviations: NA→ North America, LATAM→ South America, EMEA→ Europe, APAC→ Asia-Pacific. Here is an example of a simple file for a lookup list:
{
"NA":"North America",
"EMEA":"Europe",
"APAC":"Asia-Pacific",
"LATAM":"Latin America"
}
2. Create a RAML spec that reuses pre-created Data Types (for setting up client-level security), our new Data Types (for payload validation), and the examples data models.
#%RAML 1.0 version: 0.2 title: Lookup System API baseUri: https://mocksvc.mulesoft.com/mocks/8f970c6f-5a0e-406a-82de-1448f9159a3a/api traits: client_id: !include exchange_modules/61c52b0c-72fb-433a-8de7-de834128cfd0/client-id-security/1.0.0/client-id-security.raml types: Lookup: !include exchange_modules/61c52b0c-72fb-433a-8de7-de834128cfd0.it-ops.it-training/lookup-list-data-type/1.0.1/lookup-list-data-type.raml /lookup: is: [client_id] post: queryParameters: listName: string listType: string body: application/json: type: Lookup example: !include exchange_modules/61c52b0c-72fb-433a-8de7-de834128cfd0.it-ops.it-training/lookup-list-example/1.0.0/lookup-list-example.raml responses: 200: body: application/json: example: !include exchange_modules/61c52b0c-72fb-433a-8de7-de834128cfd0.it-ops.it-training/lookup-list-example/1.0.0/lookup-list-example.raml
3. Set up mock endpoints immediately for third-party developers and collaborators. Once we have mock endpoints, those developers can use our API to work on their own applications.
a. baseUri:https://mocksvc.mulesoft.com/mocks/8f970c6f-5a0e-406a-82de-1448f9159a3a/apii
b. This allows third-party developers to start contributing to the project immediately.
4. Update the documentation with the information that meets IT requirement standards.
a. Here is an example of the Anypoint Exchange portal page for the Lookup API.

5. Deploy the application to the API Manager.
6. Enable client-level security as a policy in API Manager.

7. Test the mock service.

8. Download the code and complete the transformations in the application.
9. Deploy to CloudHub.
And voila! Once we complete the above steps, we will have a fully functioning Lookup System API.
Keep an eye out for my next blog post, where I will break down the C4E conclusion scenario and summarize the results of this project.



