
The idea of this post is to clarify some concepts around metadata, what is it, where is stored, how to use it and how it help us to develop our applications.
So, what is it?
Metadata is a term used in many places in the Software industry and its meaning may vary depending on what it’s used for. In the context of Anypoint Studio we are always talking about types and types related information. This information can be provided by the used Connector or can be manually defined by the developer to help him understand what’s going on or use it to design a DataWeave script. It is only for design time propose as it’s supposed to represent what will flow during the execution of your application (runtime).
Levels of Metadata
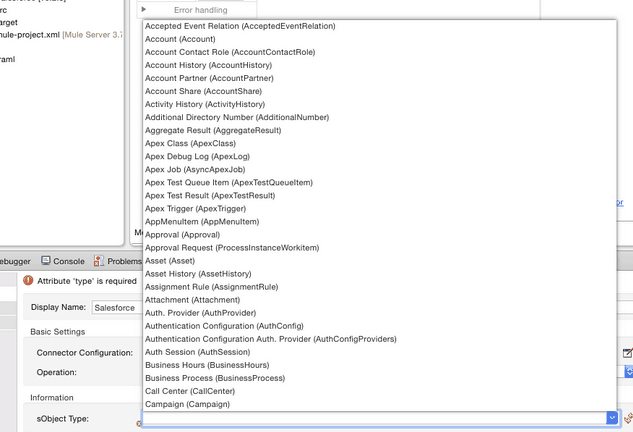
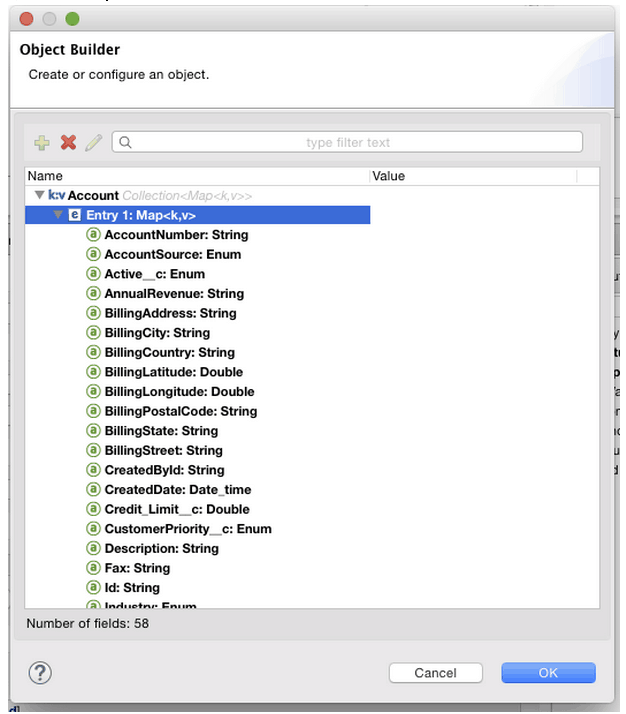
There are two levels of types information that can be retrieved in Studio, you can obtain the list of types and then each type structure, for example, when using Salesforce and configuring the Global Connector’s configuration you first retrieve the list of all the Salesforce types: Account, Opportunity and so on. Later on, when configuring a particular Salesforce operation you may or may not need to use the type structure, so to follow the example if you want to create an Account you will need to specify what are the values of some of the field inside the object Account and this would be the second level of Metadata.
List of Types:
Type Structure:
It’s good to note that this Metadata retrieval operation runs in a job in the background, allowing you to keep configuring your connector or whatever you need till the structure is retrieved. If you observe the right bottom corner of Studio you should see something like this:
Where is stored?
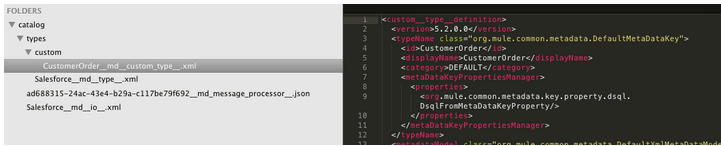
All this type of information is project related so in order for you to be able to export, import and commit and share all this, there is Catalog folder at the root of your project where all is stored to disk. It is not very human readable but Studio provides you a UI to refresh and delete types from your project’s Catalog.
In the Package explorer you can right click on the project and see the DataSense menu options
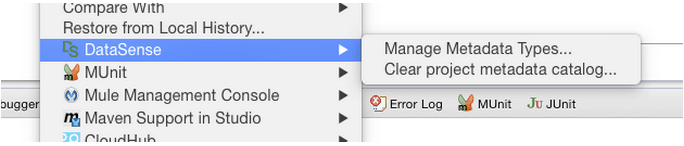
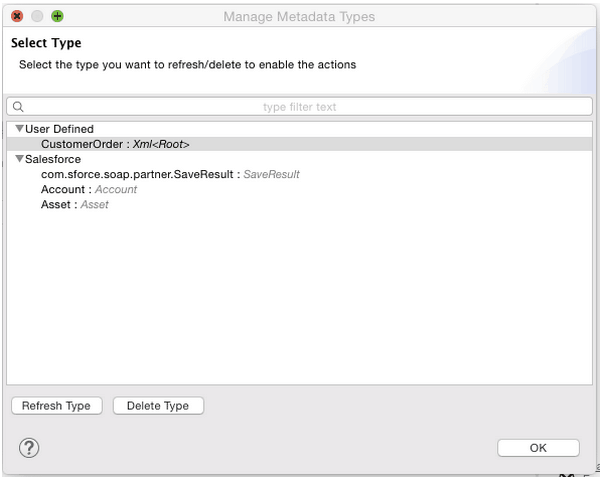
The Manage Metadata Types option will provide you the UI to delete and refresh types and these operations will impact over the files stored in the Catalog folder mentioned before:
Static Metadata vs Dynamic Metadata
Depending on the Connector that you are using there are two types of Metadata, you have static Metadata and Dynamic metadata. The difference here is whether or not the connector needs to hit some Page or Webservice to retrieve this information. Connectors as the mentioned Salesforce Connector have dynamic metadata as you, as a Salesforce user, can create custom Types and if you want to use this Type information in your Mule Application you need to go to Salesforce and download it.
There are other Connectors that have metadata but all the information is stored locally in the connector as the list of types and structures doesn’t change depending on an account. Regardless of what is the type of metadata the connector uses this should be transparent for you but is good to understand how it works.
Connector’s Metadata vs Custom Metadata
Finally there is one more case; what happens when you are using a File or FTP Connector and you don’t have provided information about the files that will be consumed in your flow? Here is where the Custom Metadata mentioned before takes place. You can manually specify the type and structure using different formats: CSV, JSON, XML or a POJO.
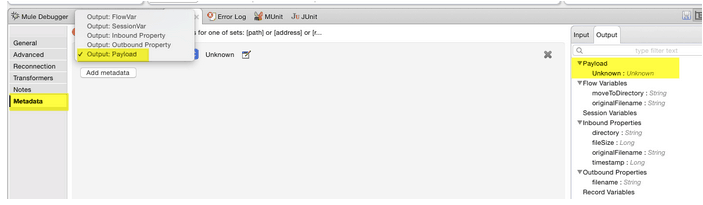
In each Message Processor you have a Metadata tab, where you can specify what goes in and what goes out of it.
Metadata Propagation
One of the important aspects of defining what comes in and what goes out is that this information is propagated in your flow. In the Metadata tree at the right side of Mule Properties window you have the input and output tab. Those represent what flows through the Message Processor. The input received and expected by a connector operation and the result that the operation will generates if there isn’t any exception.
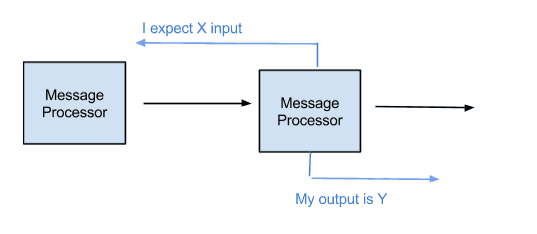
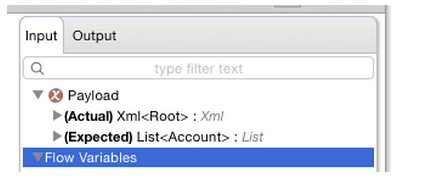
Example of Mismatch:
So, having all the metadata of your flow specified will help you to understand what’s going on in any given point.
- What should pass through,
- What’s the output and how this goes to the next Message Processor.
- What happens with your Mule Message when you adda a new Message Processor in a flow.
- How your payload, variables and properties are transformed
And all this without the need of running your application saving you lot of time.
Then, sharing this information will help other developers to understand your work done and make it much easier to contribute.
And finally, all this is especially helpful when transforming data structures and types using DataWeave; if prior to generating a mapping you configure all the Metadata information, when adding DataWeave in the middle, it will already know what the input is and what you are trying to generate as the output and with this information it will help you create the script needed to transform the data structures and types.
All these reasons are why thinking about the Metadata while developing your Mule Application is helpful and important.



