
We are all very proud to announce that Mule’s December 2013 release shipped with a major leap forward feature that will massively change and simplify Mule’s user experience for both SaaS and On-Premise users. Yes, we are talking about the new Batch jobs. If you need to handle massive amounts of data, or you’re longing for record based reporting and error handling, or even if you are all about resilience and reliability with parallel processing, then this post is for you!
Why Batch? In depth Context & History
If you’ve been following my posts then you know that when I first joined Mulesoft my job was related to architecting SaaS integration apps deployed on CloudHub. The first time that the need for a module like this crossed my mind was on an application that needed to move files from one SaaS system to another. It was expected that each execution of my migration flow would move around 8GB of information distributed in up to 30K files. If this app was to have bullet proof quality at the very least I needed to make sure that:
- If one file fails to be transferred we can continue with the rest.
- I get to retry any failed files.
- Since this was a long running/network intensive process, I need to assure that if for any reason my app or any of the other endpoints crashed, I get to resume form the point I originally was on.
- I need to have a UI to keep track
I managed to successfully achieve all of the above quality points, but I became aware that although it was still easier to do it with Mule than with custom code, there were several functionality gaps that nor the ESB or CloudHub were offering.
Only a few weeks later, a second project came with the following requirements:
- Two-way sync between Salesforce and another SaaS system
- Poll each system every 5 minutes. Expects an average of 5K updated objects on each poll, on each endpoint
- Detect and filter cycles and duplicates
- Synchronise accounts first. Skip any contacts which account hasn’t been synchronised yet.
- And most important: All of the quality attributes of the app above
It was clear by now that I had found a common use case that responded to the same design pattern:
- Get data
- Split
- Queue in persistent store so that memory is not an issue with large datasets
- Process record by record
- Track progress
- Report
Although this app was considerably more complex than the prior one, we successfully delivered it but development was way more painful, including a not so natural integration between Mule and Spring Batch. At this point it was absolutely clear to me that we needed a new construct in Mule to address these use cases. SaaS use cases are fundamentally different from the on-premise ones and part of my job was closing the gap, so I went to our awesome support team and learned that this was a huge need for on-premise users too, who were struggling with Spring Batch and ETL tools. It was turning out to be so common that actually a third application with these kind of requirements surfaced while writing the spec for the batch module.
So, What’s Batch?
Batch is a new Mule construct that provides the ability to process messages in batches. Within an application, you can initiate a batch job which is a block of code that splits messages into individual records, performs actions upon each record, then reports on the results and potentially pushes the processed output to other systems or queues. This functionality is particularly useful when working with streaming input or when engineering “near real-time” data integration between SaaS applications.

For example, batch processing is particularly useful when working with the following scenarios:
- Integrating data sets, small or large, streaming or not, to parallel process records
- Synchronising data sets between business applications, such as syncing contacts between Netsuite and Salesforce, effecting “near real-time”data integration
- Extracting, transforming and loading (ETL) information into a target system, such as uploading data from a flat file (CSV) to Hadoop
- Handling large quantities of incoming data from an API into a legacy system
Working side by side with DataMapper, DataSense and the Anypoint Connectors, Batch turns the Mule platform into a powerful data handling tool combining all the power of Mule with ETL.
The batch feature is huge and will only keep growing in future mule releases. It’s way too big to make it fit into one single post so let’s take a quick dive into its main features and we’ll elaborate on more specific use cases in future posts.
Batch Anatomy
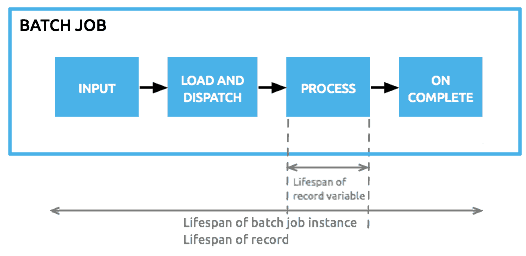
A batch job is a top-level element in Mule which exists outside all Mule flows. Batch jobs split large messages into records which Mule processes asynchronously in a batch job; just as flows process messages, batch jobs process records. A batch job contains one or more batch steps which, in turn, contain any number of message processors that act upon records as they move through the batch job. A batch job executes when triggered by either a batch executor in a Mule flow or a message source in a batch-accepting input; when triggered, Mule creates a new batch job instance. When all records have passed through all batch steps, the batch job instance ends and the batch job result can be summarized in a report to indicate which records succeeded and which failed during processing.

- Input phase: This is an optional phase in which you can place a one-way message source and/or message processors to prepare the data that is actually going to be fed into the job. At this point you’re processing synchronously at a message level
- Loading phase: This phase is automatic and implicit. You don’t have to do anything here. This is mule automatically taking the payload that came out of the input phase, splitting it into records and storing it in persistent queues.
- Process phase: In this phase, each records is processed separately and moved across the steps in an asynchronous and paralleled fashion.
- On Complete phase: In this phase you get a result object that tells you how many records were processed, how many succeeded, which ones failed (and in which step), etc. This is useful for generating reports and sending out notifications
Step by Step
In the third phase, Process, Mule begins asynchronous processing of the records in the batch. Within this required phase, each record moves through the message processors in the first batch step, then queues up for processing through the next batch step and so on until every record has passed through every batch step. Note, however, that a batch job instance does not wait for all its queued records to finish processing in one batch step before pushing any of them to the next batch step. Queues are persistent.
Mule persists a list of all records as they succeed or fail to process through each batch step. If a record should fail to be processed by a message processor in a batch step, Mule can simply continue processing the batch, skipping over the failed record in each subsequent batch step.

- Question: Why to split the processing in steps?
- Answer: Management and error handling! Suppose a job of 1 million records in which only 100 failed. Dividing your process into steps makes it easier to retry each of those hundred records from the point they were left in. Suppose a job that has three steps. In the first one you do validation, in the second one you insert into Google Contacts and in the third one you insert into Salesforce contacts. If a record fails to be inserted into Google Contacts, you don’t want to retry it from the top since that would generate a duplicate into Google Contacts (or force you to check for existence first, which would make your job overly complex and affect performance). Dividing the job into steps allows us to retry that one record from that particular step.
Record Variables
Mule has the concept of message properties (flow variables, outbound and inbound properties, etc). Although available, these concepts don’t really fit into Batch because we’re not processing at a message level but at a record level. That’s why with batch processing we added the ability to set, remove and reference variables associated to individual records. Serialized and persisting only through the Process and On Complete phases (refer to image below), a record variable stores information at the record level, rather than the flow or session level. For example, you can use recordVars to capture whether or not a customer contact – as a record – already exists in a database.
You can set the record vars using a message processor (in the same fashion as message properties):

And yes, we also added MEL support for it so that you can access/set them through expression language:
Skipping Records
You can apply one or more filters as attributes to any number of batch steps within your batch job. Filtering out some records for processing by a batch step streamlines processing so that Mule focuses only on the data which is relevant for a particular batch step.
For example, you could apply a filter to the second batch step in your batch job to make sure that the second step doesn’t attempt to process any records which failed during processing in the first batch step. To put this in context of a use case, imagine a batch job which uses its first batch step to check to see if a Salesforce contact exists for a record; the second batch step updates each existing Salesforce contact with information newly added. In such a case, you could apply a filter to the second batch step to prevent it from processing records which failed during the first batch step, in other words, records for which a contact does not already exist.
Within a batch step – the only place where you can apply a batch filter – you have the option of using one of two methods for applying a filter.
Use a Accept Expression to process only those records which, relative to the MEL expression, evaluate to true; if the record evaluates to false, the batch step does not process the record. The example below filters out all records where the age is less than 21; the batch step does not process those records.

You can also use an Accept Policy to process only those records which, relative to the value of the accept policy attribute, evaluate to true. Refer to the table below for a list of the available values for accept policy. The example below illustrates the second batch step in a batch job which processes only those records which failed processing during the preceding step. In the first batch step, Mule checked each record to see if it had an existing Salesforce contact; the second batch step, which creates a contact for each record, processes only the failed records (i.e. failed to have an existing account).
There are 3 accept policies available:
- NO_FAILURES (default): batch step processes only those records which succeeded
- ALL: batch step processes all records, regardless of whether they failed processing in a preceding batch step
- FAILURES_ONLY: batch step processes only those records which failed processing in a preceding batch steps
Fail Fast
So yes, sometimes a record can fail. But when they all start failing that probably means that something is wrong. It could be wrong data, network is down, etc. It’s very convenient in these kind of scenarios to be able to detect that situation and act upon it. If your batch has one million of bad data records, you take the risk of exceeding your API quota limit in vain. At the very least, you’re just wasting a lot of CPU time. That’s why batch jobs have the concept of maximum number of failed records allowed:
The above declaration means that the job instance will be stopped if more than 100 records are failed. If you set that value to zero (default) then no failure will be allowed and the event of any record failing will stop the job. Finally, you can set it to -1 to indicate that you’re willing to let the job instance finish no matter how many errors are found.
Batch Commit
You can use a Batch Commit block in a batch step to collect a subset of records within a job instance for bulk operations to an external service. For example, rather than upserting each individual contact (i.e. record) to Google Contacts, you can configure a Batch Commit to collect, let’s say 100 records, and upsert all of them to Google Contacts in one chunk.
Within a batch step – the only place you can apply it – you use a Batch Commit to wrap an outbound message processor. See the example below.


Demo Time
This example uses batch processing to address a use case in which the contents of a comma-separated value file (CSV) of leads – comprised of names, birthdays and email addresses – must be uploaded to Salesforce. To avoid duplicating any leads, the batch job checks to see if a lead exists before uploading data to Salesforce. The description below outlines the steps the batch job takes in each phase of processing.

INPUT PHASE
The application first uses a File Endpoint to upload a CSV file, then uses a DataMapper to convert the data format into a collection (see mapping below). Each item in the collection represents a lead. Each lead contains a company name, a first name, a last name, a birthday and an email address.

LOAD AND DISPATCH PHASE (IMPLICIT)
Invisible to the human eye, Mule creates a batch job instance, breaks the collection into records (each lead is now a record), queues the records for processing, then presents the ready-to-process batch job instance to the first batch step. None of these actions is configurable, thus Mule doesn’t expose any of these activities in the application.
PROCESS PHASE
Mule begins processing each lead as a record. The first batch step, lead-check, uses a Salesforce Connector wrapped with a Message Enricher to:
- query Salesforce to find out if a lead already exists: because the message is now the record, the application uses a MEL expression to extract the email address from the payload, then uses it to query Salesforce to find out if the lead exists
- enrich the message with a record variable to indicate that the record (i.e. lead) already exists in the Salesforce account
- The second batch step,
insert-lead, first filters out all the records for which leads already exist. It does so using an Accept Expression attribute on the batch step, indicating that any record that has been enriched with the record variable ‘exists‘ should be excluded for processing by this batch step.

- Next, the batch step uses a Logger to simply log all the records which Mule enriched with an
'exists'record variable. The list this logger produces could be useful in auditing the application to find out which of the leads on the CSV file already exist in Salesforce. - Lastly, the batch step uses a Salesforce Connector wrapped with a Batch Commit to insert all new leads to Salesforce. The batch commit behaves a bit like an aggregator, collecting records as they trickle through the queue into the batch commit “bucket”. When it has collected 200 – as specified with the
sizeattribute of the batch commit element – batch commit inserts all 200 records at once into Salesforce as new leads.

The final batch step, log-failures, uses a Logger to log all records which failed to insert to Salesforce.
ON COMPLETE PHASE
- The application uses yet another Logger to create a simple summary (see console output below) which indicates:
- the number of records which successfully loaded to Salesforce
- the number of records which failed to load
Roadmap
December 2013 is merely the first release of the batch module. Many more awesome features are coming down the line such as:
- Management console in CloudHub and MMC. Never again build your own UI to manage these jobs!
- Infinite size commit blocks
- Multinode support for reliable execution in a cluster
- Support for persisting non-serializable objects
- Many more cool things (but would have to kill you if I told you)
Take Aways
Ok, that was probably too much to take in into a single read, but hopefully it's a good introduction to the feature. Not only as a Mule developer but mainly as a former Mule user who suffered the absence of this feature I'm convinced that after you try a couple of examples you'll find it amazingly easy to handle large datasets/data integration scenarios.
For more information on batch capabilities please look at the awesome documentation that our team put together. Get the latest Studio Download to try it.
Hope you enjoyed reading and please shoot your feedback!



