
View our Hadoop Connector page here.
According to a recent survey conducted by DNV GL – Business Assurance and GFK Eurisko, 52% of enterprises globally see Big Data as an opportunity and 76% of all organizations are planning to increase or maintain their investment in big data over the next two to three years. In line with the survey, there is a growing interest from MuleSoft’s ecosystem in big data, which we are happy to support with our Anypoint Connector for Hadoop (HDFS) v5.0.0.
The Hadoop (HDFS) Connector v5.0.0 is built based on Hadoop 2.7.2 and is tested against Hadoop 2.7.1 / 2.7.2 and Hortonworks Data Platform(HDP) 2.4, which includes Hadoop 2.7.1. In this blog post, I’d like to walk you through how to use the Hadoop (HDFS) Connector v5.0.0 with a demo app called “common-operations”.
Before we start, please make sure you have access to Hadoop v2.7.1 or newer, if not, you can easily install one from the Apache Hadoop website. For the following demo, I’m going to use Hadoop 2.7.2 locally installed on Mac. After I run Hadoop 2.7.2 and hit localhost:50070, I can see the following page. (You might see a slightly different view based on your Hadoop version.)

Before you try the connector, please make sure you have Hadoop (HDFS) Connector v5.0.0 installed in Anypoint Studio. If not, please download it from the Exchange.
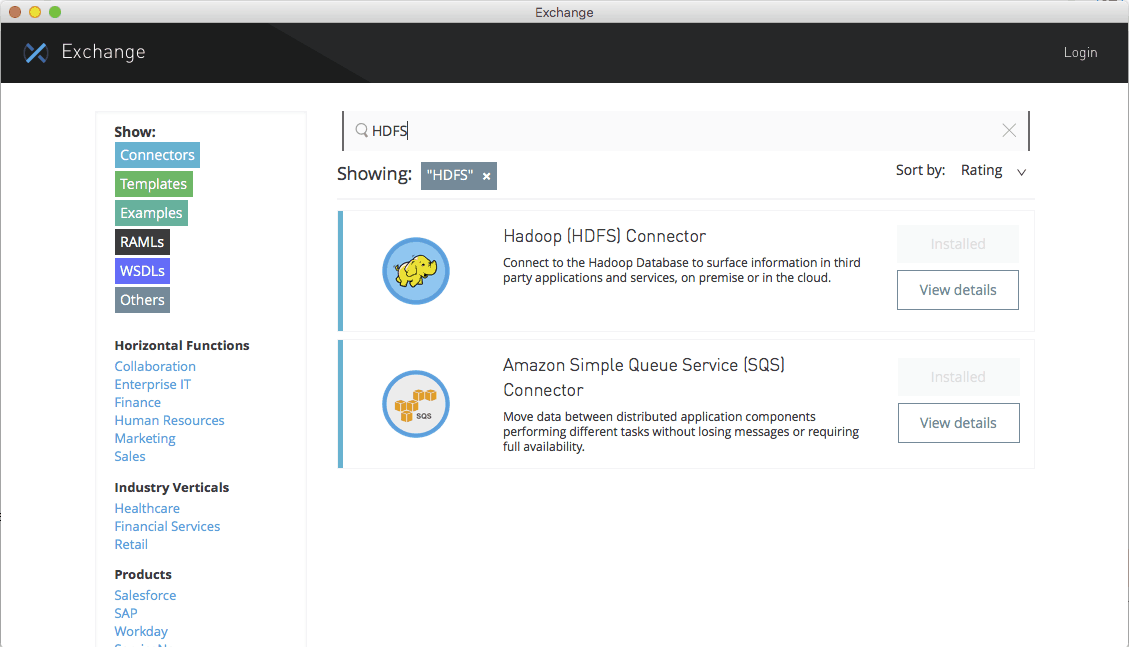
Once you download the common-operations demo app from this page and import it into Studio, you will see the following app showing you the CRUD operations on file and directory.
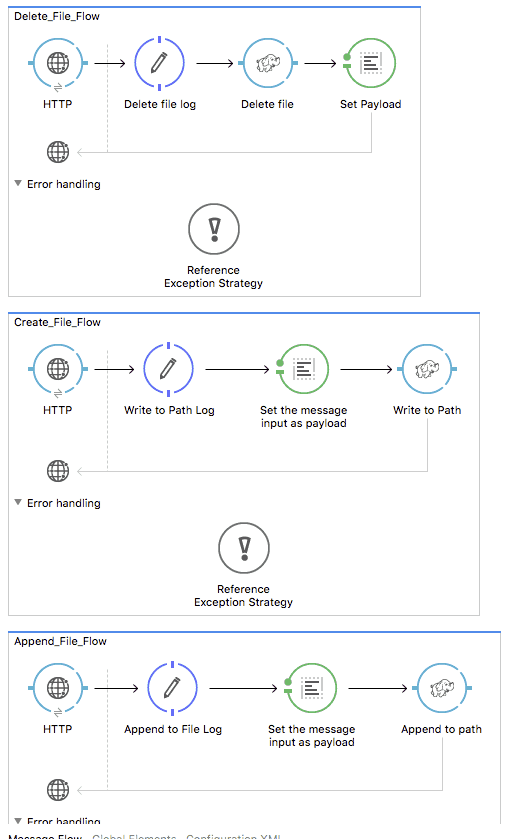
After you import the demo app, select “Global Element” and open the “HDFS: Simple Configuration” by clicking on “Edit”.
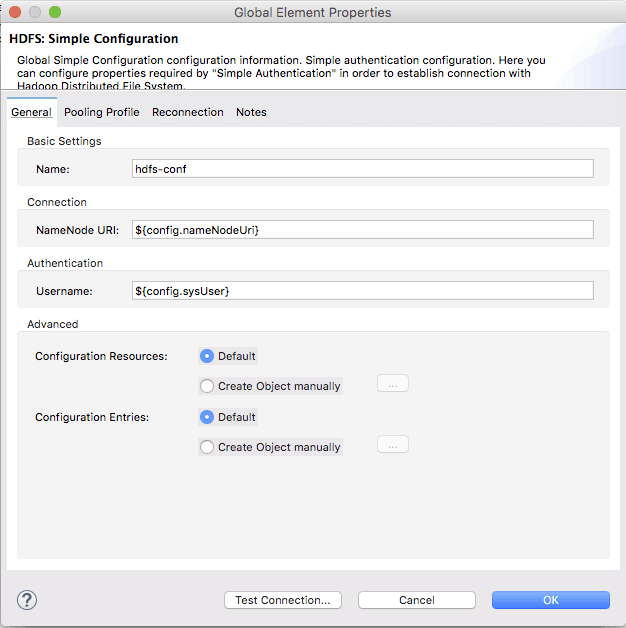
You can specify your HDFS configuration directly here, but I recommend you use the mule-app.properties. In mule-app.properties, configure the following keys:
config.nameNodeUri=hdfs://localhost:9000 (Yours can be different)
config.sysUser= (I have not set up any sysUser.)
If you start the demo app in Studio and hit localhost:8090/ with your browser, you can see the simple html page helping you play with operations supported by Hadoop HDFS Connector v5.0.0.
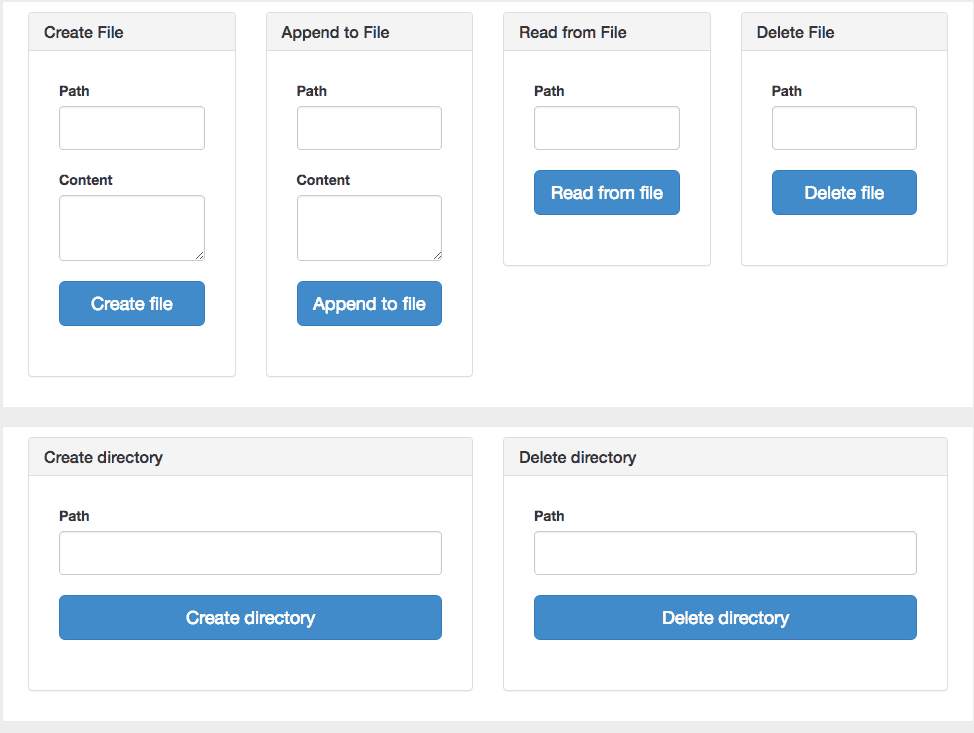
You can simply create a file with the “Create File” form. I created the hellohdfs.txt with the following information:
Path: connectordemo/hellohdfs.txt
Content: Connect anything. Change everything.
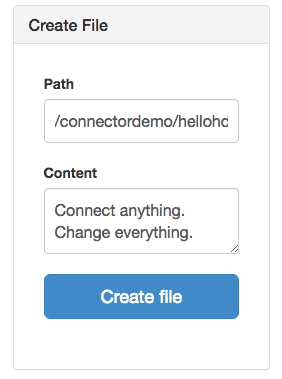
As you can see below, hellohdfs.txt is created under /connectordemo.

While you can try out other operations, I’d like to highlight a new operation called “Read from path” which we added with Hadoop HDFS Connector v5.0.0. With this new version, the connector can read the content of a file designated by its path and stream it to the rest of the flow. You don’t have to drop a poll component in source to periodically patch a file. To try this out, first specify the path (i.e. /connectordemo/hellohdfs.txt) and change the initial state of the flow from “stopped” to “started”.
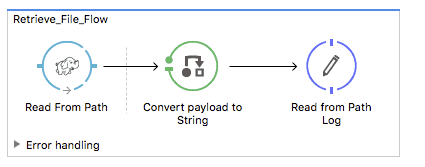
For new users, try the above example to get started, and for others, please share with us how you use or are planning to use the Hadoop HDFS Connector! Also, explore the Anypoint Exchange to see other resources you can leverage today.



